







logstash7.0.1将数据从mysql5.7同步至es7.0.1大数据量下同步慢的问题
先说结论
博主不比比,先说结论
首先我们分为两种情况
全量导库:以主键id的方式写sql语句分页导入es
增量倒库:按数据修改时间的时间字段进行到库
按时间字段进行增量导库
原因:如果我们按修改时间的字段来进行全量倒库,那么logstash的sql语句在大数据量的时候会非常慢,因为logstash在我们的sql之外又套了一层
如:logstash里的mysql.conf文件里的sql
SELECT * FROM article_lib WHERE update_time >= '2021-01-01 10:06:00'
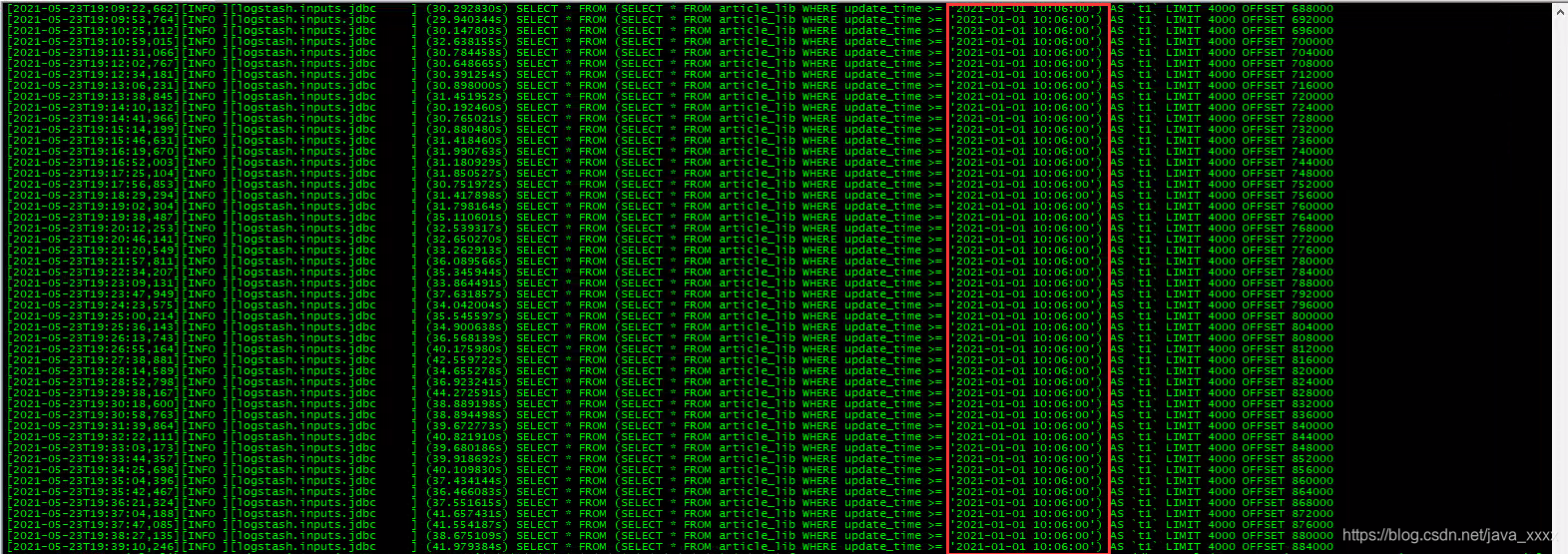
但是logstash执行的时候又给我们套了一层。这样的话当数据量大的时候offset偏移量也越来越大,导致sql的查询效率太低,在下亲测在导入到200w条数据的时候查询一次需要30min左右。
SELECT * FROM (SELECT * FROM article_lib WHERE update_time >= '2021-01-01 10:06:00') AS `t1` LIMIT 4000 OFFSET 884000
比如在200w的数据库全量导入到es,此时如果按照时间字段的方式导入,例如在配置文件中初始时间设置为’2000-01-01’那么它将查询大于该时间的所有的数据,然后再自己慢慢分页,于是就查询就特别慢,而且这是一次定时器的执行,也就是说在这次定时器未执行完毕之前,logstash的sql_last_value是不会更新值的。
优点:按时间字段适合增量导库,在全量导库之后再进行增量导库,此时给logstash指定一个上次运行时间,因为进行过增量导库,于是指定最新的时间即可,数据也就不会太多,也就避免了mysqlsql深度分页瓶颈,mysql数据库的表里需要维护一个时间字段,当程序里的数据进行修改的时候,也要修改该时间字段的值。而且优点在于,每当数据库里得数据有修改,在程序中mysql里该条数据得时间字段也得修改,此时logstash就可以将所有修改或者新增得数据同步至es。达到几乎实时同步的效果。
缺点:如果数据量太大,那么logstash自动在我们配置文件的sql语句外再加一个分页,会有mysql的深度分页瓶颈,效率相当之低。博主吐血亲测。。。300w的数据,用了48个小时还多。。。。
按主键id进行全量导库
全量导入按照id来进行导入,mysql.conf里的sql语句
sql语句
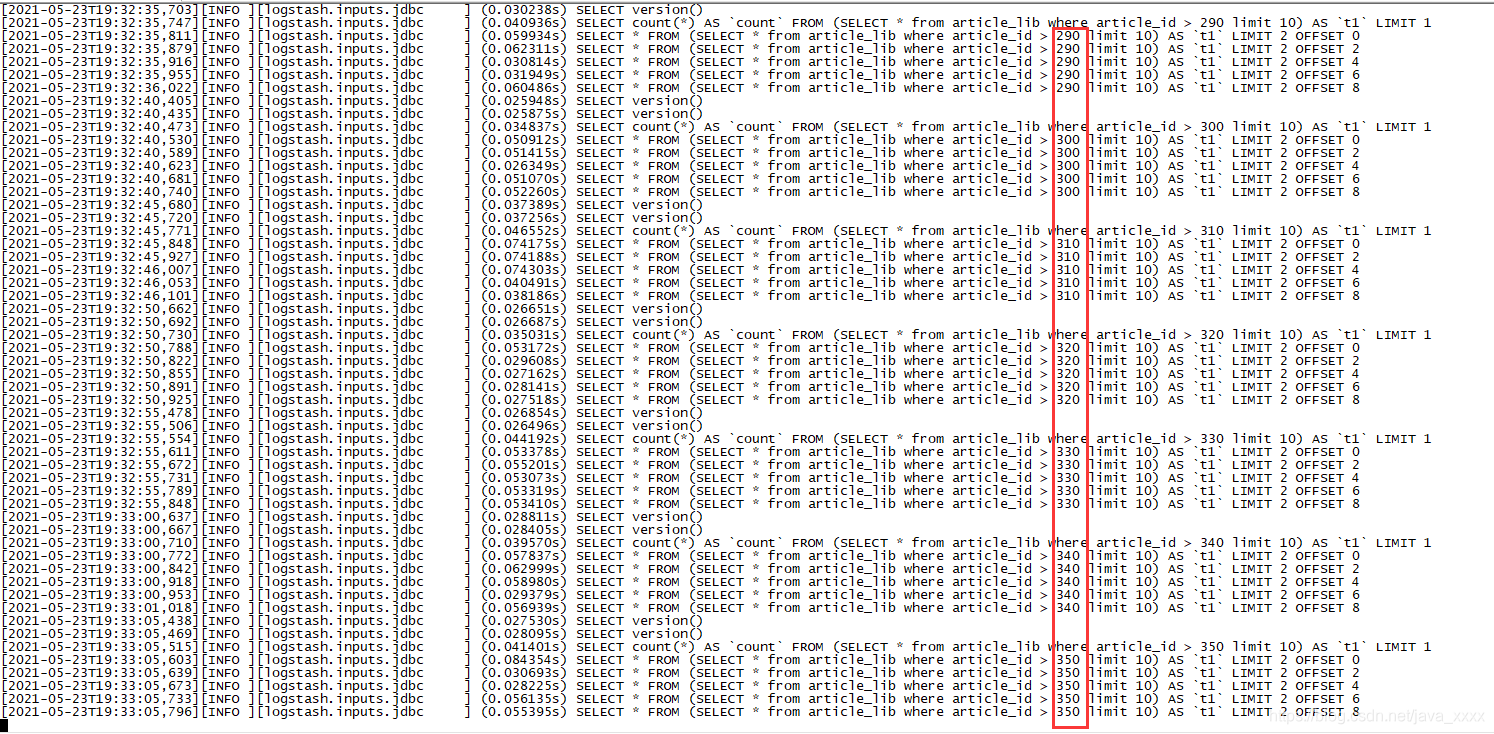
SELECT * from article_lib where article_id > 390 limit 10
logstash执行的时候sql
SELECT * FROM (SELECT * from article_lib where article_id > 390 limit 10) AS `t1` LIMIT 2 OFFSET 4
这样的好处在于每次执行完毕,就将本次执行的最后的id记录进sql_last_value,然后下次再按照该值进行分页查询,这种方式的效率比 按时间来进行全量导库 就快在它有分页,按时间来进行全量导库是全量全查出来,然后logstash再自己分页,这样的查询是很慢的。
如果是按时间增量导入,但是我们也在sql语句里分页呢,答案是不行的,
例如下面,logstash查询完只是查询了4000条数据,然后本次定时器执行完毕,将时间写入last_run_metadata_path配置的文件中,坑比的事来了,它写入的是当前执行时间,即当前时间“2021-05-23”,而不是上一条数据里记录时间字段记录的修改时间,于是下次执行就读取2021-05-23这个时间往下去执行,中间的所有数据全部都被跳过了。。。
优点:可以自己分页,加快的查询的速度,大大降低了mysql的深度分页瓶颈
缺点:当在程序里有数据被修改时,没法同步更新到es里。因为是按id,只会同步id越来越大的。
SELECT * FROM article_lib WHERE update_time >= '2021-01-01 10:06:00' limit 4000
总结,就算是一张卫生纸,一条内裤都有它本身的用处。没有什么方法是多余的,每种方法都有它对应的场景,在合适的场景下利用合适的方法,会达到事半功倍的效果。
附加上两种情况下的配置
按id全量导入
全量导入:
last_run_metadata_path配置文件last_id.txt
配置想要开始导库的id值
0
mysql_all.conf
input {
jdbc {
jdbc_driver_library => "/root/logstash7.0.1/mysql-connector-java-5.1.18.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://rm-bp1ud1aqb980hj62i9o.mysql.rds.aliyuncs.com:3306/web-monitor"
jdbc_user => "account"
jdbc_password => "password"
tracking_column => article_id
record_last_run => true
tracking_column_type => "numeric"
#按id导入的时候一定要开启,否则字段类型就是默认的timestamp
use_column_value => true
clean_run => false
jdbc_paging_enabled => "true"
jdbc_page_size => "4000"
last_run_metadata_path => "/root/logstash7.0.1/logstash-7.0.1/config/last_id.txt"
schedule => "*/5 * * * * *"
statement => "SELECT * from article_lib where article_id > :sql_last_value limit 4000"
}
}
output {
#stdout { codec => "rubydebug"}
elasticsearch {
hosts => "127.0.0.1:9201"
index => "idx_article"
document_id => "%{article_id}"
}
}
按时间增量导入
last_run_metadata_path配置文件last_time.txt
--- 2021-05-23 10:55:00.788057000 Z
mysql.conf配置文件
input {
jdbc {
jdbc_driver_library => "/root/logstash7.0.1/mysql-connector-java-5.1.18.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://rm-bp1ud1aqb980hj62i9o.mysql.rds.aliyuncs.com:3306/web-monitor"
jdbc_user => "account"
jdbc_password => "password"
tracking_column => publish_time
record_last_run => true
tracking_column_type => "timestamp"
#use_column_value => true
clean_run => false
jdbc_paging_enabled => "true"
jdbc_page_size => "2"
last_run_metadata_path => "/root/logstash7.0.1/logstash-7.0.1/config/last_time.txt"
schedule => "*/5 * * * * *"
statement => "SELECT * from article_lib where publish_time > :sql_last_value"
}
}
output {
#stdout { codec => "rubydebug"}
elasticsearch {
hosts => "127.0.0.1:9201"
index => "idx_article"
document_id => "%{article_id}"
}
}
logstash后台启动命令
启动logstash
nohup ./logstash -f /root/logstash-7.0.1/config/mysql.conf &
总结
总结:全量倒库,或者第一次将所有数据通过logstash将mysql的数据导入es的时候采用按id的方式导入。当导入完毕之后,再采用增量导入的方式同步数据。
其实本质的问题还是logstash对mysql的语句优化不够导致查询mysql数据太慢。
就算是一张卫生纸,一条内裤都有它本身的用处。没有什么方法是多余的,每种方法都有它对应的场景,在合适的场景下利用合适的方法,会达到事半功倍的效果。

















 814
814

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









