






这篇文章讲一下数据迁移的几种方案,相信大家都经历过数据迁移
单库到单库的迁移
单库到单库的迁移简单粗暴,可以通过 MySQL 主从同步的方式做到准实时的数据拷贝;也可以通过 mysqldump 工具将源库的数据导出再导入到新库,首先这两种方式只能支持单库到单库的迁移, 无法支持单库到多库多表的场景。其次即便是单库到单库的迁移,迁移过程也需要满足以下几个目标:
- 迁移应该是在线的迁移,也就是在迁移的同时还会有数据的写入;
- 数据应该保证完整性,也就是说在迁移之后需要保证新的库和旧的库的数据是一致的;
- 迁移的过程需要做到可回滚,这样一旦迁移的过程中出现问题,可以立刻回滚到源库不会对系统的可用性造成影响。
如果使用 Binlog 同步的方式,在同步完成后再修改代码,将主库修改为新的数据库,这样就不可回滚,一旦迁移后发现问题,由于已经有增量的数据写入了新库而没有写入旧库,不可能再将数据库改成旧库。
一、双写方案
注意:双写之前要断掉旧库与新库的同步
优点:迁移的过程可以随时回滚,将迁移的风险降到了最低。
缺点:时间周期比较长,应用有改造的成本。
物理机之间的数据迁移
- 将新库配置为源库的从库用来同步数据;如果需要将数据同步到多库多表,那么可以使用一些第三方工具获取 Binlog 的增量日志(比如开源工具
Canal),在获取增量日志之后就可以按照分库分表的逻辑写入到新的库表中了。 - 同时我们需要改造业务代码,在数据写入的时候不仅要写入旧库也要写入新库。当然,基于性能的考虑,我们可以异步地写入新库,只要保证旧库写入成功即可。但是我们需要注意的是,需要将写入新库失败的数据记录在单独的日志中,这样方便后续对这些数据补写,保证新库和旧库的数据一致性。
- 然后我们就可以开始校验数据了。由于数据库中数据量很大,做全量的数据校验不太现实。你可以抽取部分数据,具体数据量依据总体数据量而定,只要保证这些数据是一致的就可以。
- 如果一切顺利,我们就可以将读流量切换到新库了。由于担心一次切换全量读流量可能会对系统产生未知的影响,所以这里最好采用灰度的方式来切换,比如开始切换 10% 的流量,如果没有问题再切换到 50% 的流量,最后再切换到 100%。
- 由于有双写的存在,所以在切换的过程中出现任何的问题都可以将读写流量随时切换到旧库去,保障系统的性能。
- 在观察了几天发现数据的迁移没有问题之后,就可以将数据库的双写改造成只写新库,数据的迁移也就完成了。

自建机房迁移到云机房
如果是将数据从自建机房迁移到云上,也可以使用上面这个方案,只是你需要考虑的一个重要的因素是:自建机房到云上的专线的带宽和延迟,你需要尽量减少跨专线的读操作,所以在切换读流量的时候你需要保证自建机房的应用服务器读取本机房的数据库,云上的应用服务器读取云上的数据库。这样在完成迁移之前,只要将自建机房的应用服务器停掉并且将写入流量都切到新库就可以了。
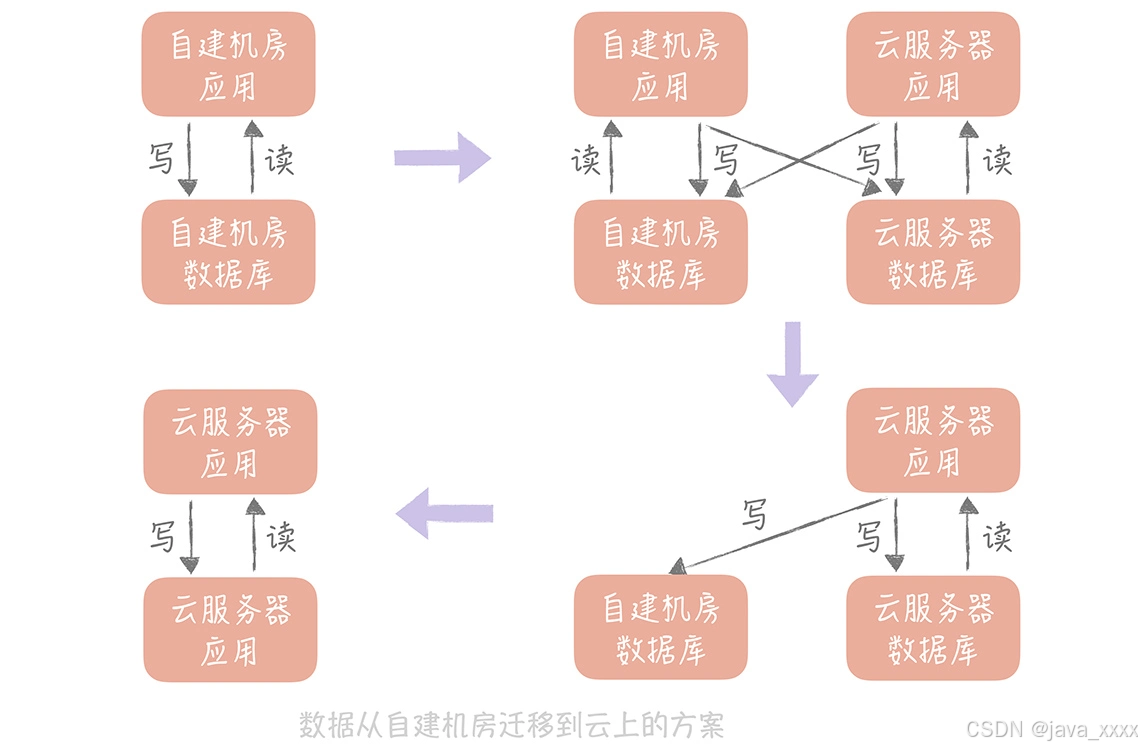
这种方案是一种比较通用的方案,无论是迁移 MySQL 中的数据还是迁移 Redis 中的数据,甚至迁移消息队列都可以使用这种方式,在实际的工作中可以直接拿来使用。
二、级联同步方案
方案
优点:是简单易实施,在业务上基本没有改造的成本。
缺点:是在切写的时候需要短暂的停止写入,对于业务来说是有损的,不过如果在业务低峰期来执行切写,可以将对业务的影响降至最低。
这种方案比较适合数据从自建机房向云上迁移的场景。因为迁移上云最担心云上的环境和自建机房的环境不一致,会导致数据库在云上运行时因为参数配置或者硬件环境不同出现问题。
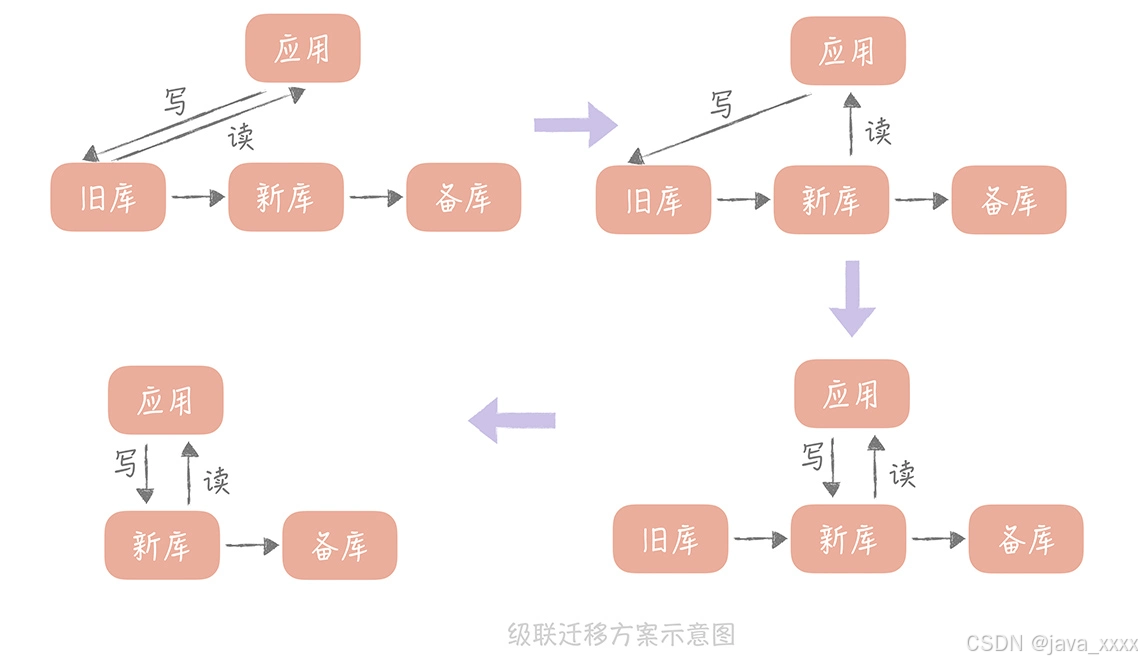
所以我们会在自建机房准备一个备库,在云上环境上准备一个新库,通过级联同步的方式在自建机房留下一个可回滚的数据库,具体的步骤如下:
- 先将新库配置为旧库的从库,用作数据同步;
- 再将一个备库配置为新库的从库,用作数据的备份;
- 等到三个库的写入一致后,将数据库的读流量切换到新库;
- 然后暂停应用的写入,将业务的写入流量切换到新库(由于这里需要暂停应用的写入,所以需要安排在业务的低峰期)。
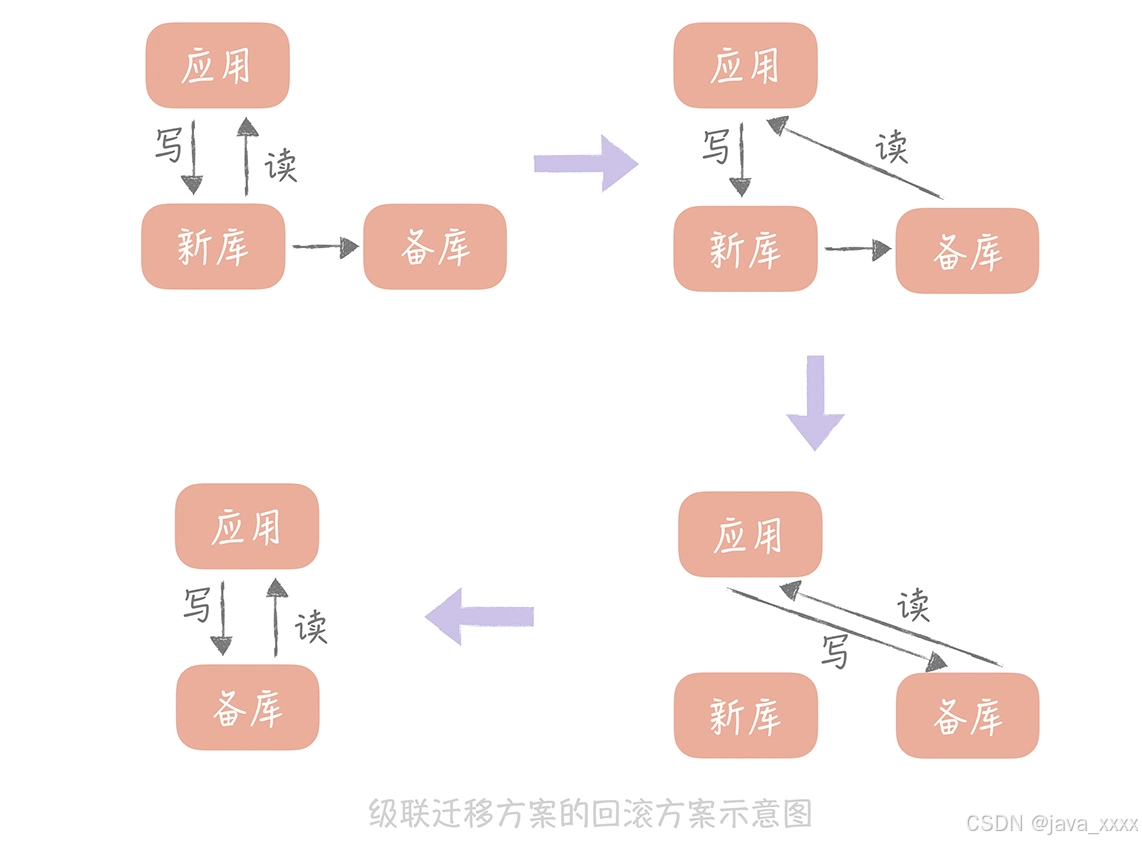
这种方案的回滚方案也比较简单,可以先将读流量切换到备库再暂停应用的写入,将写流量切换到备库,这样所有的流量都切换到了备库,也就是又回到了自建机房的环境,就可以认为已经回滚了。
上面的级联迁移方案可以应用在将 MySQL 从自建机房迁移到云上的场景,也可以应用在将 Redis 从自建机房迁移到云上的场景,如果你有类似的需求可以直接拿来应用。
数据迁移时如何预热缓存
在从自建机房向云上迁移数据时,我们也需要考虑缓存的迁移方案是怎样的。那么你可能会说:缓存本来就是作为一个中间的存储而存在的,我只需要在云上部署一个空的缓存节点,云上的请求也会穿透到云上的数据库,然后回种缓存,对于业务是没有影响的。你说得没错,但是你还需要考虑的是缓存的命中率。如果你部署一个空的缓存,那么所有的请求就都穿透到数据库,数据库可能因为承受不了这么大的压力而宕机,这样你的服务就会不可用了。所以,缓存迁移的重点是保持缓存的热度。刚刚我提到,Redis 的数据迁移可以使用双写的方案或者级联同步的方案,所以在这里我就不考虑 Redis 缓存的同步了,而是以 Memcached 为例来说明。
刚刚我提到,Redis 的数据迁移可以使用双写的方案或者级联同步的方案,所以在这里我就不考虑 Redis 缓存的同步了,而是以 Memcached 为例来说明。
使用副本组预热缓存
优点:
1.实现缓存数据的迁移,
2.可以尽量控制专线的带宽和请求的延迟情况,你也可以直接在项目中使用。
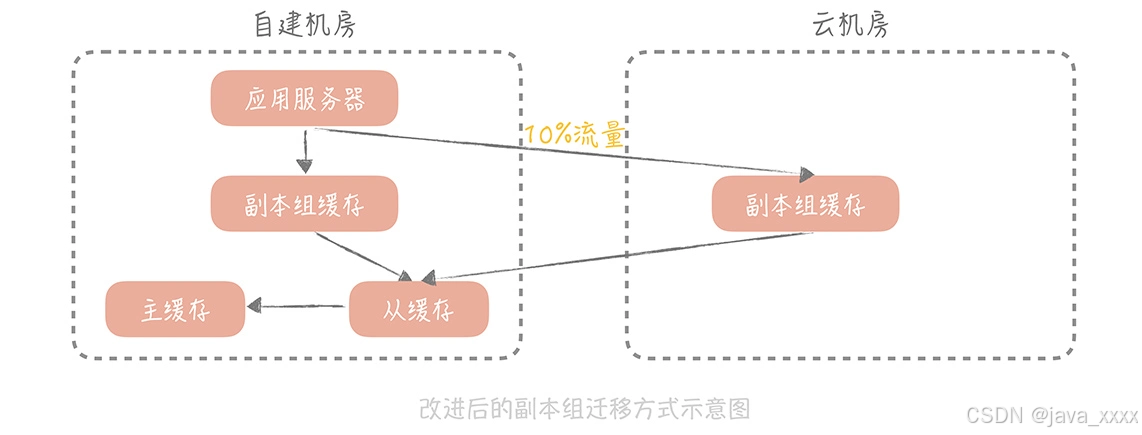
- 在云上部署多组 mc 的副本组,自建机房在接收到写入请求时,会优先写入自建机房的缓存节点,异步写入云上部署的 mc 节点;
- 在处理自建机房的读请求时,会指定一定的流量(比如 10%)优先走云上的缓存节点,这样虽然也会走专线穿透回自建机房的缓存节点,但是流量是可控的;
- 当云上缓存节点的命中率达到 90% 以上时,就可以在云上部署应用服务器,让云上的应用服务器完全走云上的缓存节点就可以了。

















 683
683

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









