







 本文介绍了一个使用Node.js实现的简单豆瓣电影爬虫程序。该程序通过HTTPS模块发起请求,并利用cheerio解析HTML,抓取正在上映的电影标题、评分及海报链接,最后将数据保存到本地文件中。
本文介绍了一个使用Node.js实现的简单豆瓣电影爬虫程序。该程序通过HTTPS模块发起请求,并利用cheerio解析HTML,抓取正在上映的电影标题、评分及海报链接,最后将数据保存到本地文件中。
直接上代码:这是http模块
'use strict'
//引入内建和第三方模块
const https = require("https")
const url = require("url")
const Promise = require("bluebird")
//创建启动服务模块
function start(url){
return new Promise((resolve,reject)=>{
https.get(url,(res)=>{
const statusCode = res.statusCode
const contentType = res.headers['content-type']
let error
if(statusCode != 200){
error = new Error(`请求失败.\n`+`code:${statusCode}`)
}
if(error){
console.log(error)
res.resume()
return
}
res.setEncoding("utf-8")
let getData = ""
res.on("data",(datachunk)=>{
getData += datachunk
})
res.on("end",()=>{
resolve(getData)
})
}).on("error",(e)=>{
reject(e)
console.log("获取数据出错")
})
})
}
exports.start = start主程序入口:
const crawler = require("./crawler")
const querystring = require("querystring")
const cheerio = require("cheerio")
const fs = require("fs")
//url
const douban_url = "https://movie.douban.com/nowplaying/chengdu/"
crawler.start(douban_url).then(res=>{
var $ = cheerio.load(res)
var data = []
$('#nowplaying .list-item').each(function(i,e){
var obj = "obj" + i
obj = {}
obj.title = $(e).attr("data-title")+"\n"
obj.score = $(e).attr("data-score")+"\n"
obj.src = $('#nowplaying .list-item img').attr("src")+"\n"
data.push(obj)
})
fs.writeFileSync("./get_data/data.txt",JSON.stringify(data));
})
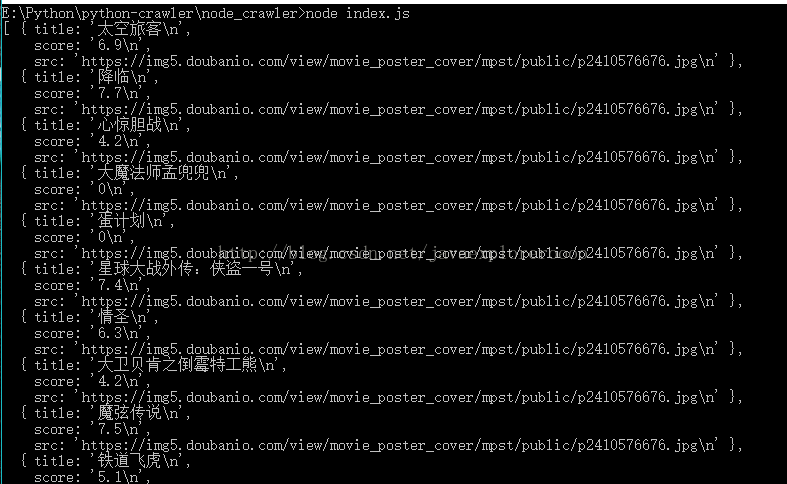
效果展示:

















 1028
1028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









