







前言
今天给大家带来的是node简单爬虫,对于前端小白也是非常好理解且会非常有成就感的小技能
爬虫的思路可以总结为:请求 url – > html(信息) -> 解析html
这篇文章呢,就带大家爬取豆瓣TOP250电影的信息
工具
爬虫必备工具:cheerio
cheerio简单介绍:cheerio是jquery核心功能的一个快速灵活而又简洁的实现,主要是为了用在服务器端需要对DOM进行操作的地方。 大家可以简单的理解为用来解析html非常方便的工具。
使用之前只需要在终端安装即可 npm install cheerio
node爬虫步骤解析
一、选取网页url,使用http协议get到网页数据
豆瓣TOP250链接地址:https://movie.douban.com/top250
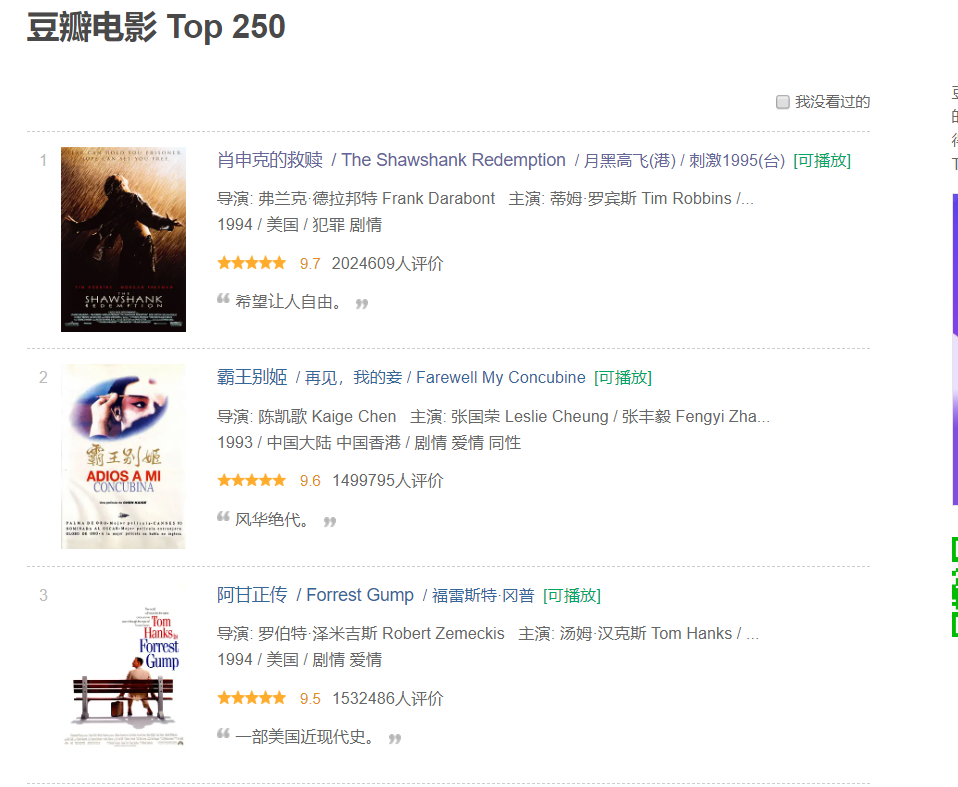
首先我们请求http协议,通过http来拿到网页的所有数据
const https = require('https');
https.get('https://movie.douban.com/top250',function(res){
// 分段返回的 自己拼接
let html = '';
// 有数据产生的时候 拼接
res.on('data',function(chunk){
html += chunk;
})
// 拼接完成
res.on('end',function(){
console.log(html);
})
})
上面代码呢,大家一定要注意我们请求数据时,拿到的数据是分段拿到的,我们需要通过自己把数据拼接起来
res.on('data',function(chunk){
html += chunk;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 913
913











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









