






自然语言处理(NaturalLanguage Processing,NLP)是人工智能的一大分支领域,其主要目的是让机器理解人类的语言文字,从而执行一系列任务。
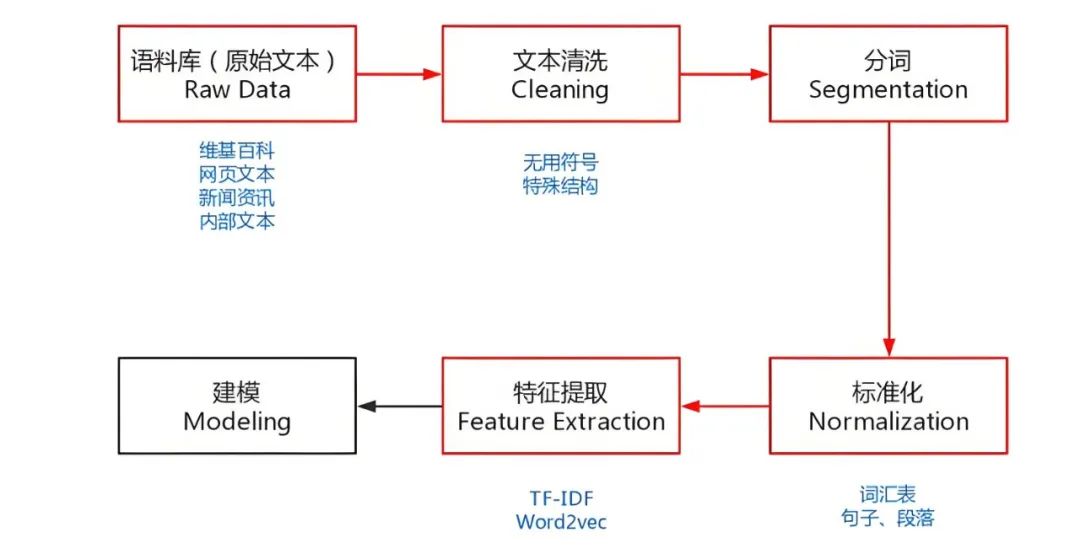
通常来说,语音识别、文本生成、情感分析、知识图谱、机器翻译、问答系统、聊天机器人等都是常见的自然语言处理任务。
如果继续划分下去,自然语言处理还可被细分为自然语言理解(Natural Language Understanding,NLU)和自然语言生成(Natural Language Generation, NLG )
相比计算机视觉相关的任务,自然语言处理任务难度更高。与图片和视频相比,语言文字受到方言、表达方式、歧义等多种因素的影响,更不用说,很多文字并非字面意思,需要联系上下文来理解其更加深层次的含义。
举个自然语言处理领域的经典例子,“南京市长江大桥”这句话就可以有两种断句方式,一种是“南京市”和“长江大桥”;另一种则是“南京市长”和“江大桥"。
当模型没有联系上下文时,很难判断这句话的真实意图是什么。此外,像“C罗梅开二度”这句话,对模型来说,更是难上加难,因为它既不知道C罗是谁,更不知道“梅开二度”在足球中是什么含义。
在2019年之前,自然语言处理使用的技术主要是循环神经网络(Recurent Neural Network,RNN)和卷积神经网络(Convolutional Neural Network,CNN)等特征抽取器。
卷积神经网络主要由卷积层、池化层和全连接层组成。如图3-6所示:
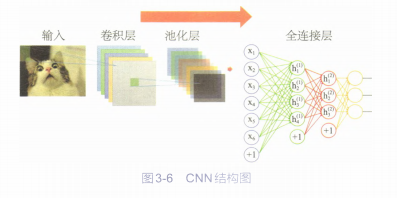
其中,卷积层用来提取图像中的特征,随着卷积层不断加深,提取的特征范围也在加大,相当于人眼从局部开始逐步看到整体:池化层则是用来降维,大幅度降低参数的量级。
从而简化网络:全连接层就是普通的神经网络层,池化层的输出就是全连接层的输入,全连接层的输出就是卷积神经网络整体的输出结果。
看到这里,你很可能会有疑问,卷积神经网络不是应用在图像领域吗?和自然语言处理有什么关系呢?
其实在大部分情况下,文本数据和图像数据一样,都会被处理后转化为矩阵的形式作为模型的输入,此时对于卷积神经网络,数据本身是图像、文字或语音,又有什么区别呢?
相比卷积神经网络来说,循环神经网络最大的特性就是对于序列数据的处理非常有效,能挖掘出数据中的时序信息及语义信息,天然适合处理文本和语音数据。
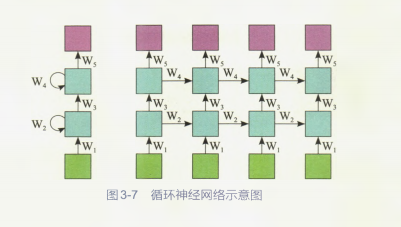
从图3-7所示的循环神经网络示意图中可以看到,输入数据(绿色部分)之间是有前后关联的,在处理数据的时候每一个隐藏层的神经元(蓝色部分)都会接收从上一个时刻传来的历史信息,这也就意味着循环神经网络拥有了像人类一样的记忆能力,这是一个重要的突破!
介绍完卷积神经网络和循环神经网络后,补充说明一下,上面之所以说“在2019年之前”,是因为在2018年尾BERT(其全称是Bidirectinal Encoder Representation fromTransformer,是一种用于语言表征的预训练模型)模型的横空出世,彻底改变了自然语言处理的范式。
预训练模型其实很容易理解,记住**“举一反三”**这四个字就可以。当预训练模型训练好以后,仅需要对该模型最后几层的神经元权重进行微调(Fime Tuning),再利用一些新数据进行增量的训练,即可将模型的能力迁移到其他领域。
通俗地说,预训练模型就相当于“站在了巨人的肩膀上”,可以在开始就获得及格线以上的成绩,并在此基础上继续进步。
在预训练模型被大范围使用之前,使用传统的深度学习算法,想让模型得到更好的效果,就需要在数据量和神经网络的层数上做文章,通常需要数据在量级上的提升并不断叠加更深的神经网络。
虽然这种“暴力解法”也可以使得模型效果更好,但总体来说,性价比不高。同时,哪怕卷积神经网络和循环神经网络等特征抽取器进行各种变形,但表达能力依旧受限,传统的深度学习算法仍旧无法学到数据里蕴含的更深刻的含义。
在这种情况下,BERT的出现让此前的循环神经网络和卷积神经网络等方法黯然失色,自此之后,自然语言处理领域几乎被 BERT实现了“大一统”,无论是在学术界还是工业界,自然语言处理研究和应用的突破几乎离不开BERT的变体。
BERT之所以能取得这么大的突破,和其将特征抽取器从循环神经网络和卷积神经网络统一成Transformer架构有很大的关系。那我们下期再来详细介绍一下Transformer是如何为AIGC奠基的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









