







之前一直都是在转载被人的一些网络安全相关的文章,最近有空了就写写之前完成的一个项目的核心技术,对网络安全或是弱点扫描器有兴趣的可以和我一起探讨这方面的知识。
ps:当我设计完这款扫描器的时候俨然发现我已经成为一名会写代码的黑客了,不对,应该是白帽子,因为我不会去做坏事,嘿嘿。。。。
设计一款网站弱点扫描器的必要基础是你必须非常熟悉http协议和相关的库(如urllib、urllib2,由于系统采用纯python开发,网络方面主要用到的就是这两个库。),值得说明的是这个系统我借鉴一些开源项目和商业项目的设计,并做了大量的优化,现在整体性能在同类产品中也表现不错,我在这里会大致阐述里面涉及到的核心技术和核心思想,也会对设计的一些不足的地方进行说明,因为归根结低我更喜欢设计而不是漏洞挖掘或是黑客,所以对漏洞的介绍会简单说明,如果大家有兴趣的话我会另写文章去专门介绍各类漏洞的检测方法和利用方法。由于扫描器的开发周期比较长,所有的设计和编码均由我一个人完成,里面的一些我可能考虑的不够完美,希望能和有这方面兴趣的人一起探讨。
网站扫描就是利用web扫描技术对网站进行一次完整的安全评估,设计主要包含扫描引擎、扫描策略、引擎服务器、UI等模块组成,主要模块描述如下:
1. 扫描引擎采用双进程模型,分别为爬虫进程和扫描进程,爬虫进程主要负责由用户配置的参数智能的在指定网站上抓取链接或请求,然后提交给扫描进程,扫描进程则依据配置的策略和抓取的请求进行扫描,找出该请求存在的安全风险。
2. 扫描策略:一个扫描策略对应着一个脚本,一个扫描策略可能检测多种类型的漏洞,可能对应着一个扫描规则库,目前的扫描策略已达到50多条,已覆盖主流的web漏洞、服务器漏洞、cms漏洞、网页挂马等,例如常见的sql注入、xss、strut2远程代码执行、信息泄漏等等。
3. 扫描引擎采用跨平台的boost asio实现,扫描扫描任务同时执行时则由引擎服务器负责调度。
网络爬虫的核心技术:
网络爬虫作为扫描引擎的发动机,它负责按策略抓取页面上的url,包括get和post等请求。核心点包括对各级域名及子域的过滤、对自定义404页面的判断、对抓取算法的设计、数据存储时对内存和磁盘处理、各种网络异常和超时的处理、对首页跳转的处理、对各种类型页面的解析和链接提取、对页面和参数的去重、抓取后台需要登录的页面的处理、其他额外需要考虑的还包括https证书处理、basic、ntlm等http认证、http协议中gzip的使用、keeplive长连接的处理、dns缓存、multipartpost上传、http代理、包括本地缓存的请求优化等。当然考虑更多的话应该还包括javascript的深度解析,对于一些通过js或ajax动态生成的页面可能采用该技术。
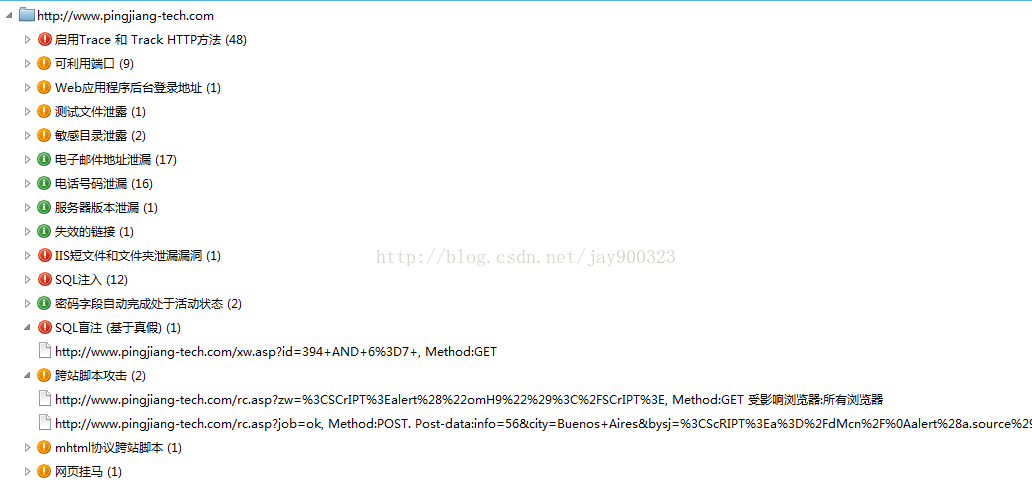
扫描进程作为扫描进程的核心之一,它主要负责对所有的策略的调度执行,策略不同其执行方式可能也会有所不同,一些策略可能只需要执行一次或多次,有些策略可能需要每个请求或特殊的请求才执行一次,策略之间可能会存在依赖关系。当策略发现一个web漏洞之后会将所有漏洞的详细信息提交通过接口提交给扫描进程,扫描进程还负责和引擎服务器进行通信,通信方案中定义了各种类型的数据包,例如扫描状态、扫描进度、弱点信息等等。扫描策略采用插件化模型设计,通过定制插件便可实现对相应漏洞的扫描功能。扫描策略这里大致枚举下:跨站脚本攻击、SQL注入、SQL盲注、远程命令执行、WebDAV不安全配置、WebDAV远程代码执行、任意文件上传、目录穿越、Struts2远程代码执行、表单绕过、文件包含、openssl heart bleed、Spring远程代码执行、Spring表达式JSP属性处理信息泄露、IIS短文件和文件夹泄漏漏洞、可利用端口、信息泄漏、cms指纹识别等等。
引擎服务器封装了用户层的各种接口,包括引擎启动、各种类型的回调接口(如扫描状态回调、弱点回调、命令行回调、错误回调等等),我将一个服务器的所有处理过程都封装在了一个dll里面,当初这样的设计就是为了模块化、方便扩展,可设计成单独的扫描服务并后期采用bs结构,UI部分采用duilib实现,就不赘述了。
所有的策略通过插件实现对于写写数据采集的软件完全可以在此扫描器的基础上通过定制策略来实现,一款好的弱点扫描器应该有完整的日志排错功能、网络很复杂,可能就会出现你预料不到的错误,你应该能根据日志快速的找出错误原因并改进优化,对漏洞的误报和漏报控制在一定范围内。唯一不足的地方在于对动态js的解析能力较弱,具体可参考http://demo.aisec.cn/demo/aisec/中各种动态页面生成的方式,我用虚拟浏览器对某个url的访问时间明显高于urllib2的请求时间,直接拖慢了引擎的抓取速度。虽然对于js生成的页面中的请求抓取不存在问题,但是ajax的请求还是较难抓到。下一版本的扫描器将会考虑加入web2.0的高效抓取功能,下面附一张对某网站的扫描结果。
图1
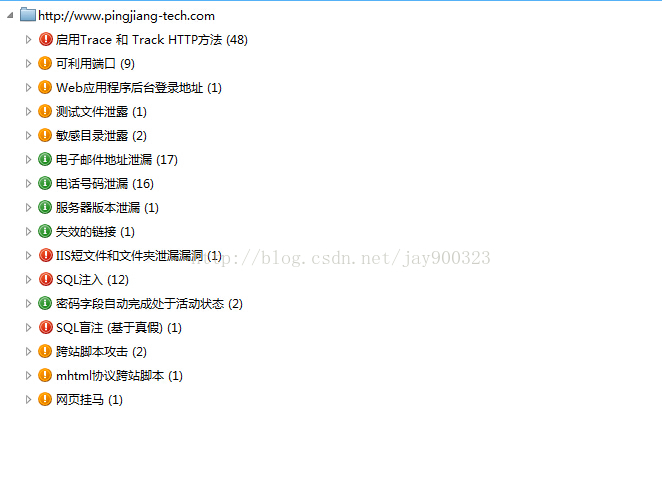
图2
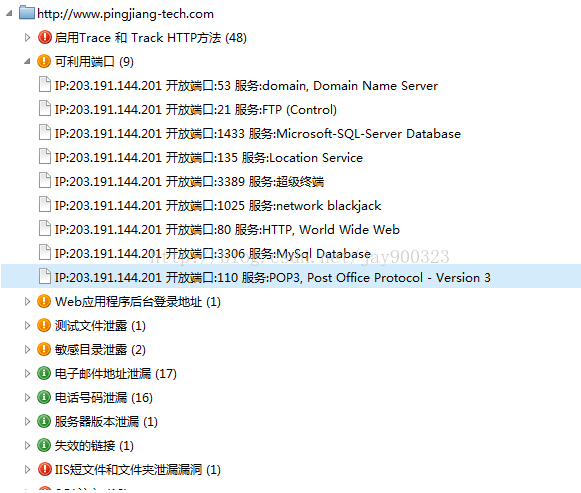
图3

















 412
412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









