







数据血缘关系介绍
定义
Data Lineage 数据血统,也叫做Data Provenance 数据起源或Data Pedigree 数据谱系
从数据的产生,ETL处理、流转流通,到最终消亡,数据之间自然会形成一种关系,类似于人类社会的血缘关系,我们称之为数据血缘关系。
数据血缘关系有一些明显的特征
-
归属性。一般来说,特定的数据归属特定的团队或者个人
-
多源性。同一个数据可以有多个来源(多个父亲)。一个数据可以是多个数据经过加工而生成的,而且这种加工过程可以是多个。
-
可追溯性。数据的血缘关系,体现了数据的生命周期,体现了数据从产生到消亡的整个过程,具备可追溯性。
-
层次性。数据的血缘关系是有层次的。对数据的分类、归纳、总结等对数据进行的描述信息又形成了新的数据,不同程度的描述信息形成了数据的层次。
数据血缘关系图中的元素
数据节点
用来用来表现数据的所有者和数据层次信息或终端信息
有三种类型:主节点,数据流出节点,数据流入节点
-
主节点只有一个,位于整个图形的中间,是可视化图形的核心节点。图形展示的血缘关系就是此节点的血缘关系,其他与此节点无关的血缘关系都不在图形上展示,以保证图形的简单、清晰。
-
数据流入节点可以有多个,是主节点的父节点,表示数据来源
-
数据流出节点也可以有多个,是主节点的子节点,表示数据的去向;包括一种特殊的节点,即终端节点,终端节点是一种特殊的数据流出节点,表示数据不再往下进行流转,这种数据一般用来做可视化展示。
流转线路
表现的是数据的流转路径,从左到右流转。数据流转线路从数据流入节点出来往主节点汇聚,又从主节点流出往数据流出节点扩散
数据流转线路表现了三个维度的信息,分别是方向、数据更新量级、数据更新频次
-
方向的表现方式,没有做特别的设计,默认从上到下流转;
-
数据更新的量级通过线条的粗细来表现。线条越粗表示数据量级越大,线条越细则表示数据量级越小。
-
数据更新的频次用线条中线段的长度来表现。线段越短表示更新频次越高,线段越长表示更新频次越底,一根实线则表示只流转一次。
数据血缘关系的作用
数据溯源
溯源,指的是探寻事物的根本、源头。我们分析处理的数据,可能来源很广泛,有政府的数据,有互联网的数据,有通过数据交易从第三方获取的数据,还有自身拥有的数据。不同来源的数据,数据质量参差不齐,对分析处理的结果影响也不尽相同。当数据发生异常,我们需要能追踪到异常发生的原因,把风险控制在适当的水平。
数据的血缘关系,体现了数据的来龙去脉,能帮助我们追踪数据的来源,追踪数据处理过程。在数据的血缘关系可视化图形上,主节点的上面就是数据来源节点,非常清晰,一目了然。数据经过了哪些转换也能从可视化图形上看出来,对异常数据产生原因的分析帮助很大。
评估数据价值
数据的价值在数据交易领域非常重要,涉及到数据的定价。要对数据价值进行评估,就需要有依据。数据血缘关系,可以从几个方面给数据价值的评估提供依据:
-
数据受众。在血缘关系图上,下面的数据流出节点表示受众,亦即数据需求方,数据需求方越多表示数据价值越大;
-
数据更新量级。数据血缘关系图中,数据流转线路的线条越粗,表示数据更新的量级越大,从一定程度上反映了数据价值的大小;
-
数据更新频次。数据更新越频繁,表示数据越鲜活,价值越高。在血缘关系图上,数据流转线路的线段越短,更新越频繁。
数据质量评估
从数据的血缘关系图上,可以方便的看到数据清洗的标准清单,这个清单反映了对数据质量的要求。
数据归档、销毁的参考
如果数据没有了受众,就失去了使用价值。从数据的血缘关系图上看,最下面没有了数据节点,就可以去评估主节点所代表的数据是否要归档或者销毁了
大数据血缘分析系统设计(二)
概述
数据血缘分析属于元数据管理的重要一部分,能够使开发者直观的了解数据的来龙去迈,快速上手
广义上,血缘分析包含以下3个级别:
-
任务级别
-
数据级别
-
字段级别
下面分别介绍
任务级别
大数据平台当中的数据,往往由一个个的任务生成,虽然在不同的应用系统中虽然有不同的名字,如Yarn中的application、Oozie中的Job、Spark/MR/Hive中的Job,但本质上都是同一类东西:都有input/output Data,有的Job会有多个input/output Data。
通过查看任务级别的血缘关系,可以了解到更高层级的信息,如服务器、运行时长、等待时长、当前任务流状态等
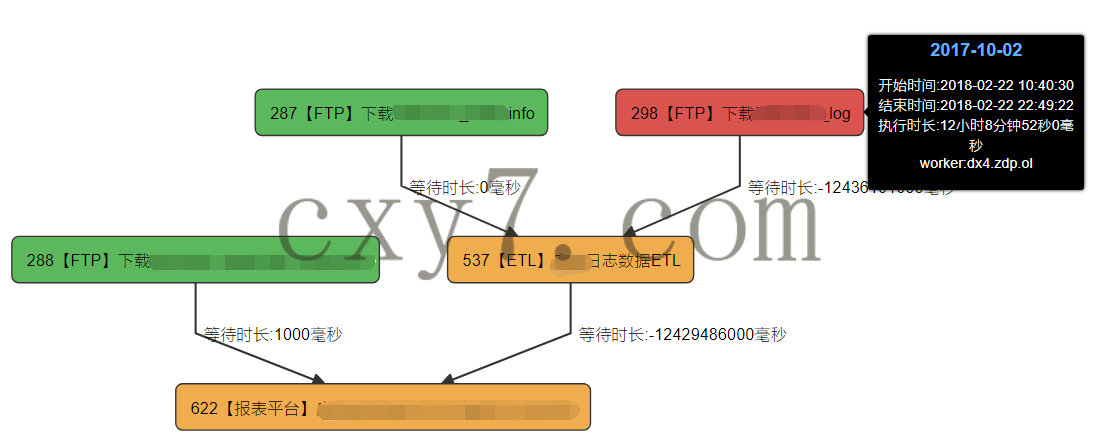
如下图为笔者公司内部一个简单的流程,从中可以看到
-
前置任务状态,如执行失败,或是依赖任务失败;
-
任务执行时长
-
等待依赖项满足所需的时长
-
任务流
-
任务所在服务器信息
-
。。。
数据级别
数据,也叫表、目录等,广义上包括HDFS、HBase、关系型数据库、Kafka、Ftp、本地文件等。
通过查看数据级别的血缘关系,可以看到:
-
表的依赖链条
-
表的重要程度(后续的使用者多少)
-
表的基础信息

进而可以基于此,做一些数据质量、影响分析的工作
字段级别
在实际使用中,有时会有一些稍显苛刻的需求,如更改字段的影响有多大、字段是如何产生的等,此时就需要字段级别的血缘关系
按照Hive当中的定义,分为两种:Projection和Predicate
Projection
投影,只影响单一输出字段
Predicate
断言,影响所有输出字段

实际应用中,由于Predicate影响所有字段,绘制到图标当中会产生很多条线,因此,我们默认展示Projection
设计
核心概念
| 名词 | 含义 | 例子 |
|---|---|---|
| Job | 任务、或代表业务流程中一个阶段 | 如一个定时任务、一个批处理 |
| Dataset | 数据集,可以存储数据的对象 | Hive表、MySQL表、HDFS目录 |
| Field | 字段,Dataset的属性 | 如User表有userId和userName属性 |
| Dag | 有向无环图 ( Directed Acyclic Graph),图形化展示血缘关系 | JobDag、DataDag、FieldDag |
| Job Lineage | job血缘关系,即Job依赖关系 | job2依赖job1,则表示为job2→job1 |
| Data Lineage | Data血缘关系,即Data的Input/Output关系 | data3是通过data1和data2 join出来的,则data3→data1,data2 |
| Field Lineage | 字段血缘关系,即字段的predicate/projection关系 | 如as是projection关系,where是predicate关系 |
DB Model
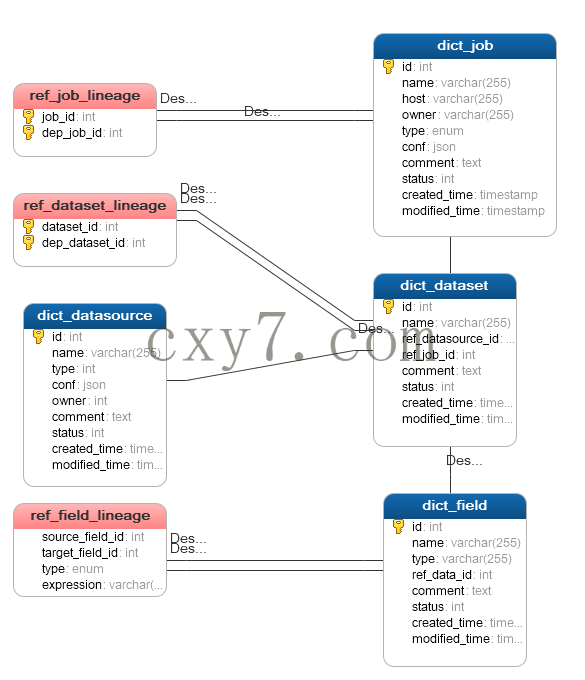
三张表映射表说明
| 表名 | 用途 |
| ref_job_lineage | 用于存储Job级别的血缘关系 |
| ref_dataset_lineage | 用于存储数据级别的血缘关系 |
| ref_field_lineage | 用于存储字段级别的血缘关系 |
在前面一篇《大数据血缘分析系统设计(二)》中,对大数据血缘分析系统做了整体的介绍,任务级别的血缘关系计划放在分布式调度系统的设计当中介绍,因此本系列后面主要针对数据级别和字段级别进行介绍
数据级别血缘关系介绍
参考《数据级别》
血缘关系数据的收集
数据ID的标识
要想血缘关系图中方便的定位到数据,首要解决的问题,就是数据ID的唯一标识。最容易想到的,就是利用服务器IP-数据库-数据表这种方式,但这种方式的不足之处在于,一是标识符长,不容易传播,二是无法统一不同数据源,如数据可能是Kafka、FTP、本地文件等方式存储的,相应的标识方式也互不相同。因此,容易想到,使用元数据统一分配的ID,是比较合适的。
参考《WhereHows》中的设计,不同数据源的数据,经过ETL进入元数据系统时,由元数据系统唯一分配ID
如下图,为WhereHows的dict_dataset数据表内容样例
可见,同一数据,既有id标识,也有URN的标识

数据流转的收集
解决了数据ID标识的问题,另一个难点在于数据流转关系的收集,针对不同的数据处理方式,收集方式也不一样
SQL
在《利用LineageInfo分析HiveQL中的表级别血缘关系》一文中,我提到,利用org.apache.hadoop.hive.ql.tools.LineageInfo类,可以用来分析HiveQL中的表级别血缘关系,然而,如何获取到运行的HiveQL的语句呢?
Hive提供了Hook机制,在Hive编译、执行的各个阶段,可以调用参数配置的各种Hook
我们利用hive.exec.post.hooks这个钩子,在每条语句执行结束后自动调用该钩子

配置方法,在hive-site.xml中配置以下参数
<property>
<name>hive.exec.post.hooks</name>
<value>org.apache.hadoop.hive.ql.hooks.LineageLogger</value>
</property>
在org.apache.hadoop.hive.ql.hooks.LineageLogger的run方法中加入以下代码

在HiveQL执行完成后,在Driver端的日志当中,就会打印出如下信息

MapReduce
对与Mapreduce程序,由于输入输出均是由各种InputFormat/OutFormat执行,因此可以在Job提交时获取
在org.apache.hadoop.mapreduce.JobSubmitter#submitJobInternal方法中添加一些逻辑,如在submitJob之后

org.apache.hadoop.mapreduce.HadoopLineageLogger的代码如下
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
|
MR任务运行完成之后,在日志之中会输出如下信息
| 1 |
|
Spark
类似于Hive,可以通过自定义org.apache.spark.scheduler.SparkListener
然后在spark/conf中指定spark.sql.queryExecutionListeners和spark.extraListeners
订阅事件总线上的事件
有关Spark事件总线的详情,可以参考《Spark2.3源码分析——LiveListenerBus(事件总线)》
其他
虽然Hive/MR/Spark任务占了数据处理的多数,但仍然有一些数据处理不能覆盖,怎么样能够获取到这些信息呢?
这就需要祭出杀手锏——人工录入了
通过在元数据系统的数据详情页,维护当前数据的前置数据,即可串联起整个数据流程

血缘关系图的可视化
按照《数据血缘关系图中的元素》的介绍,一个血缘关系图中的要素有两部分,数据节点的和流转线路
故需要将前面收集到的原始信息做一次ETL处理,与元数据系统中的ID库做一个映射,进而封装成JSON数据,提供给前端展示,
如按照下面方式组织
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 |
|
展示页面

大数据血缘分析系统设计(四)
在前一篇文章《大数据血缘分析系统设计(三)》中,我们介绍了数据级别的血缘关系分析,接下来,我们分析以下字段级别的血缘关系
尽管在大多数场景下,血缘关系分析到数据级别已经够用了,但在某些场景下仍显得不足,比如我想了解更改字段类型的影响有多大、字段是如何产生的等,此时就需要字段级别的血缘关系
字段级别的血缘关系说明
按照Hive当中的定义,分为两种:Projection和Predicate
Projection
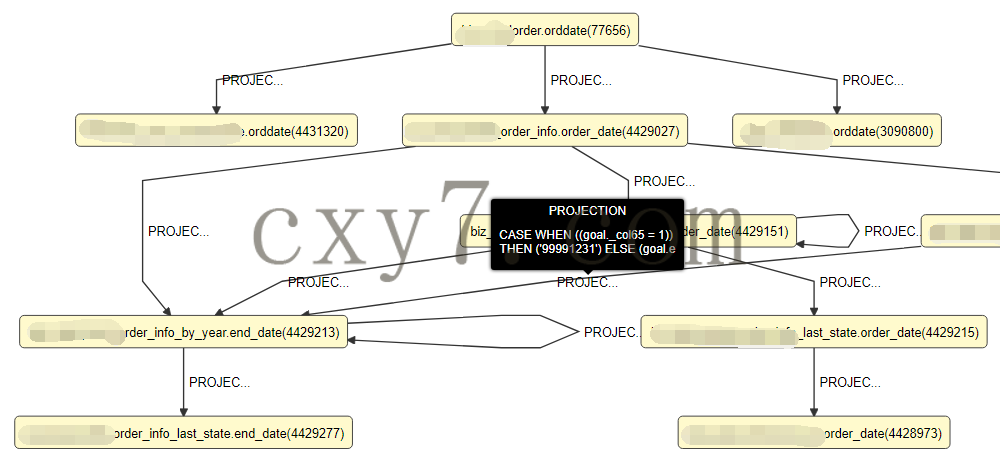
投影,只影响单一输出字段,因此可以看到单个字段的产生、转换、后续使用等
如下图,是字段orddatte的DAG
Predicate
谓语、断言,影响所有输出字段
如下图,是createtime字段的血缘关系图,由于createtime字段参与了where子句中的筛选,因此,输出表的所有字段都会跟该字段关联起来

血缘关系的收集
SQL
类似于数据级别的血缘关系,可以通过在Hive中配置hive.exec.post.hooks参数来收集
查看org.apache.hadoop.hive.ql.hooks.LineageLogger代码
org.apache.hadoop.hive.ql.hooks.LineageLogger#run
-
从Context中拿到QueryPlan对象
-
解析查询计划,拿到Edge列表,即字段转化关系
-
根据Edge,拿到Vertex集合,即字段节点
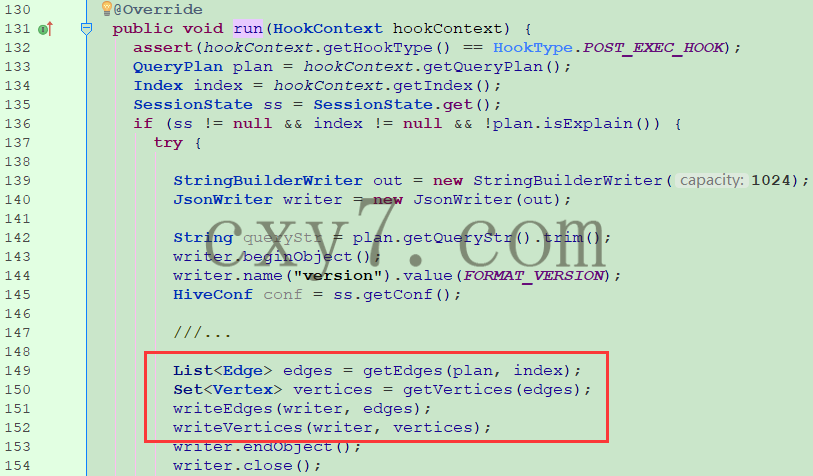
org.apache.hadoop.hive.ql.hooks.LineageLogger#getEdges
核心代码就两段
基于查询计划的输出, 找出目标表名和字段列表
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
//拿到最终的SelectOperator列表
LinkedHashMap<String, ObjectPair<SelectOperator,
org.apache.hadoop.hive.ql.metadata.Table>> finalSelOps = index.getFinalSelectOps();
Map<String, Vertex> vertexCache = new LinkedHashMap<String, Vertex>();
List<Edge> edges = new ArrayList<Edge>();
for (ObjectPair<SelectOperator, org.apache.hadoop.hive.ql.metadata.Table> pair: finalSelOps.values()) {
List<FieldSchema> fieldSchemas = plan.getResultSchema().getFieldSchemas();
SelectOperator finalSelOp = pair.getFirst();
org.apache.hadoop.hive.ql.metadata.Table t = pair.getSecond();
String destTableName = null;
List<String> colNames = null;
if (t != null) {
destTableName = t.getDbName() + "." + t.getTableName();
fieldSchemas = t.getCols();
} else {
// 基于查询计划的输出, 找出目标表名和字段列表.
for (WriteEntity output : plan.getOutputs()) {
Entity.Type entityType = output.getType();
if (entityType == Entity.Type.TABLE
|| entityType == Entity.Type.PARTITION) {
t = output.getTable();
destTableName = t.getDbName() + "." + t.getTableName();
List<FieldSchema> cols = t.getCols();
if (cols != null && !cols.isEmpty()) {
colNames = Utilities.getColumnNamesFromFieldSchema(cols);
}
break;
}
}
}
|
遍历每个目标字段,生成血缘关系的边
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
Set<Vertex> targets = new LinkedHashSet<Vertex>();
for (int i = 0; i < fields; i++) {
Vertex target = getOrCreateVertex(vertexCache,
getTargetFieldName(i, destTableName, colNames, fieldSchemas),
Vertex.Type.COLUMN);
targets.add(target);
Dependency dep = dependencies.get(i);
addEdge(vertexCache, edges, dep.getBaseCols(), target,
dep.getExpr(), Edge.Type.PROJECTION);
}
Set<Predicate> conds = index.getPredicates(finalSelOp);
if (conds != null && !conds.isEmpty()) {
for (Predicate cond: conds) {
addEdge(vertexCache, edges, cond.getBaseCols(),
new LinkedHashSet<Vertex>(targets), cond.getExpr(),
Edge.Type.PREDICATE);
}
}
|
org.apache.hadoop.hive.ql.hooks.LineageLogger#getVertices
直接从Edge中取出sources和targets
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
private Set<Vertex> getVertices(List<Edge> edges) {
Set<Vertex> vertices = new LinkedHashSet<Vertex>();
for (Edge edge: edges) {
vertices.addAll(edge.targets);
}
for (Edge edge: edges) {
vertices.addAll(edge.sources);
}
// Assign ids to all vertices,
// targets at first, then sources.
int id = 0;
for (Vertex vertex: vertices) {
vertex.id = id++;
}
return vertices;
}
|
人工录入
字段相比数据,更加难以获取血缘关系,除了SQL类型的,可以通过语法分析拿到,其它的都要靠人工录入来完成,因此,需要以下的维护页面
新增依赖关系
由于维护字段的关系工作量繁重,为了减轻工作量,可以给出字段建议,通过分析当前字段所在表的前后依赖关系,可以给出来源字段和目标字段的候选项
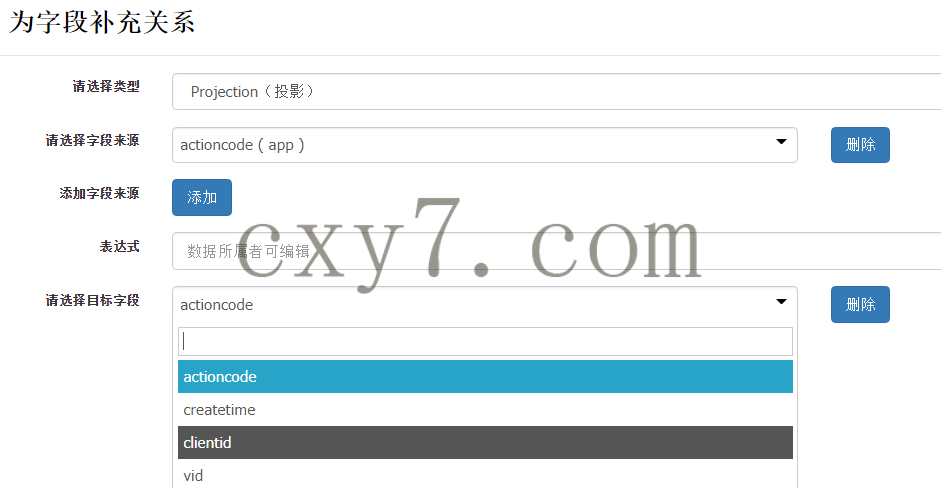
列表页

字段血缘关系图
准备数据
上面收集到的原始数据,需要进行ETL,与元数据系统中的ID关联起来,才能方便提供给前端页面展示
下面给出一个demo数据
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
|
{
"vertices":["ll_inland_detail_basic.actioncode(4420694)","ll_inland_detail_basic_copy.actioncode(4141049)","mm_transform_source.actioncode(4423049)","mm_transform_source_page.actioncode(4443827)"],
"edges":[
{
"expression":"n.actioncode",
"source":{
"name":"actioncode",
"id":"ll_inland_detail_basic.actioncode(4420694)",
"type":"string",
"dataset":{
"name":"ll_inland_detail_basic",
"id":4587,
"ref_datasource_id":0,
"status":0
},
"status":0
},
"type":"PROJECTION",
"target":{
"name":"actioncode",
"id":"mm_transform_source.actioncode(4423049)",
"type":"string",
"dataset":{
"name":"mm_transform_source",
"id":16544,
"ref_datasource_id":0,
"status":0
},
"status":0
}
},
{
"expression":"n.actioncode",
"source":{
"name":"actioncode",
"id":"ll_inland_detail_basic.actioncode(4420694)",
"type":"string",
"dataset":{
"name":"ll_inland_detail_basic",
"id":4587,
"ref_datasource_id":0,
"status":0
},
"status":0
},
"type":"PROJECTION",
"target":{
"name":"actioncode",
"id":"mm_transform_source_page.actioncode(4443827)",
"type":"string",
"dataset":{
"name":"mm_transform_source_page",
"id":17188,
"ref_datasource_id":0,
"status":0
},
"status":0
}
},
{
"expression":"NULL",
"source":{
"name":"actioncode",
"id":"ll_inland_detail_basic.actioncode(4420694)",
"type":"string",
"dataset":{
"name":"ll_inland_detail_basic",
"id":4587,
"ref_datasource_id":0,
"status":0
},
"status":0
},
"type":"PROJECTION",
"target":{
"name":"actioncode",
"id":"ll_inland_detail_basic_copy.actioncode(4141049)",
"type":"string",
"dataset":{
"name":"ll_inland_detail_basic_copy",
"id":11452,
"ref_datasource_id":0,
"status":0
},
"status":0
}
}
]
}
|
前端页面展示


















 496
496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









