







1 前言
本次分享是使用基于 Faster-RCNN 的水稻叶片病害检测的深度学习算法研究,也是我研究的课题,本文本文使用的算法架构为 Faster R-CNN,研究的课题为使用两种不同的主干特征提取网ResNet-50 和VGG-16 模型进行模型训练和对比评估那个模型的性能更好。在实验过程中,首先设置了学习率、迭代次数等参数。为了评估模型的能采用了召回率( recall)、准确率( accuracy)以及识别效果等作为评估指标。通过对比 ResNet-50主干特征提取网络和传统的 VGG-16 特征提取网络,进行了结果分析。
2 算法架构及其原理
本文所使用的 Faster R-CNN 算法是一种在计算机视觉中广泛使用的目标检测算
法。由 Shaoqing Ren 等人在 2015 年提出。这个算法是在 Fast R-CNN 算法基础上的
改进版本,其表现出来的效果为更高的准确率和更快的对象检测的速度。 FasterR-CNN 算法是通过端到端训练、网络化的候选区域生成以及准确性与速度的平衡等方面的改进,成为了目标检测领域的重要里程碑之一,推动了深度学习在目标检测任务中的发展。
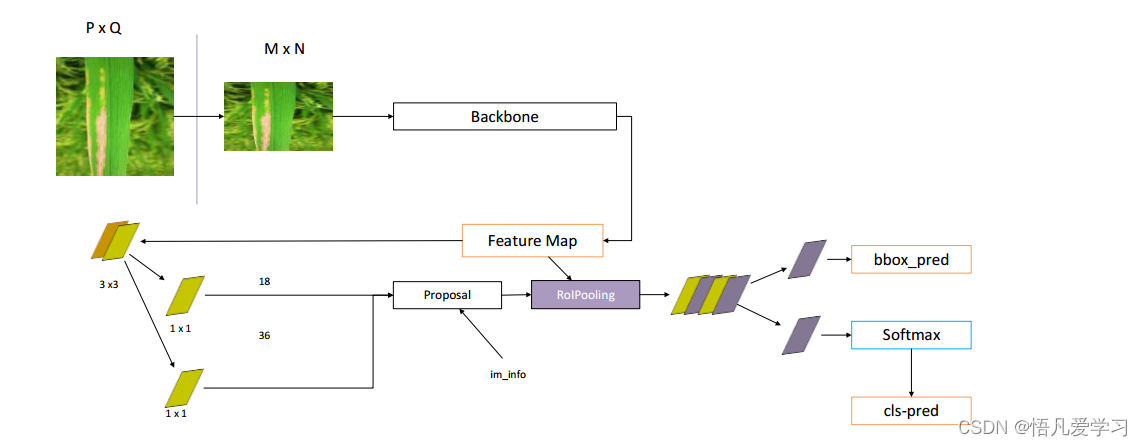 Faster R-CNN 主干网络
Faster R-CNN 主干网络
Faster R-CNN 的架构由两个基本部分组成:区域提议网络( Region Proposal
Network, RPN)和目标检测网络。
2.1 主干特征提取网络
2.1.1 VGG-16 模型
VGG-16 是一种深度卷积神经网络模型,由牛津大学视觉几何组( Visual Geometry
Group)于 2014 年提出。该模型的名称“VGG-16”指的是其包含 16 个卷积层和全连接
层,其中卷积层包括 13 个卷积层和 3 个池化层,全连接层包括 2 个全连接层和一个
softmax 分类器。 VGG-16 模型的特点是使用了非常小的卷积核( 3x3),并且在每个
卷积层之后都使用了 ReLU 激活函数和 2x2 的最大池化层。这种设计使得 VGG-16 模
型具有非常深的网络结构,并且在 ImageNet 图像分类任务上取得了非常好的性能。
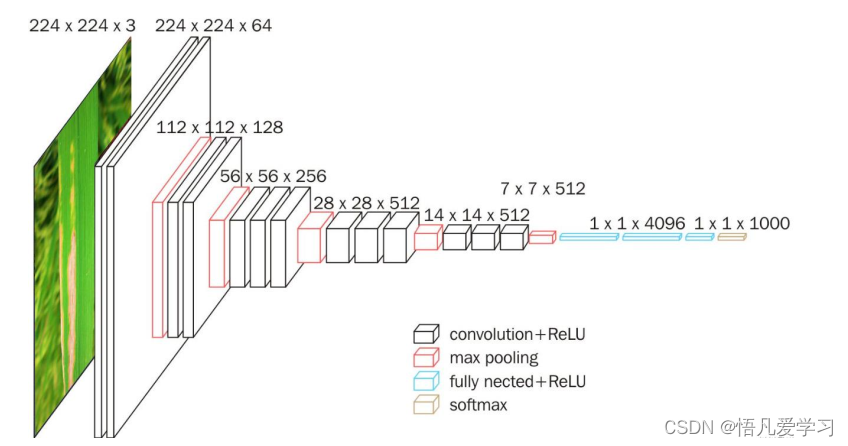 VGG 图形结构图
VGG 图形结构图
本文的研究中输入的图片是以 600× 600×3 像素图像为输入的卷积神经网络模型
中,首先采用 3×3 尺寸的滤波器进行卷积操作,并通过堆叠方式将每 2 到 3 个滤波器
串联在一起,这样可以实现类似扩大感受野的效果。为了保持输入图像的尺寸不变,
模型使用 padding 技术,并保持 stride 为 1。接着,模型通过 2×2 的池化窗口对卷积
后的特征图进行采样,从而减少特征图的尺寸和计算量。此过程简化了模型结构,同
时保留了关键功能,如感受野的拓展和特征降维,以及对于平移不变性的保持。
实现代码:
import torch
import torch.nn as nn
from torch.hub import load_state_dict_from_url
#--------------------------------------#
# VGG16的结构
#--------------------------------------#
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=True):
super(VGG, self).__init__()
self.features = features
#--------------------------------------#
# 平均池化到7x7大小
#--------------------------------------#
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
#--------------------------------------#
# 分类部分
#--------------------------------------#
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
#--------------------------------------#
# 特征提取
#--------------------------------------#
x = self.features(x)
#--------------------------------------#
# 平均池化
#--------------------------------------#
x = self.avgpool(x)
#--------------------------------------#
# 平铺后
#--------------------------------------#
x = torch.flatten(x, 1)
#--------------------------------------#
# 分类部分
#--------------------------------------#
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
'''
假设输入图像为(600, 600, 3),随着cfg的循环,特征层变化如下:
600,600,3 -> 600,600,64 -> 600,600,64 -> 300,300,64 -> 300,300,128 -> 300,300,128 -> 150,150,128 -> 150,150,256 -> 150,150,256 -> 150,150,256
-> 75,75,256 -> 75,75,512 -> 75,75,512 -> 75,75,512 -> 37,37,512 -> 37,37,512 -> 37,37,512 -> 37,37,512
到cfg结束,我们获得了一个37,37,512的特征层
'''
cfg = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M']
#--------------------------------------#
# 特征提取部分
#--------------------------------------#
def make_layers(cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
def decom_vgg16(pretrained = False):
model = VGG(make_layers(cfg))
if pretrained:
state_dict = load_state_dict_from_url("https://download.pytorch.org/models/vgg16-397923af.pth", model_dir="./model_data")
model.load_state_dict(state_dict)
#----------------------------------------------------------------------------#
# 获取特征提取部分,最终获得一个37,37,1024的特征层
#----------------------------------------------------------------------------#
features = list(model.features)[:30]
#----------------------------------------------------------------------------#
# 获取分类部分,需要除去Dropout部分
#----------------------------------------------------------------------------#
classifier = list(model.classifier)
del classifier[6]
del classifier[5]
del classifier[2]
features = nn.Sequential(*features)
classifier = nn.Sequential(*classifier)
return features, classifier
2.1.2 ResNet-50 模型
ResNet-50 属于 ResNet( Residual Network)系列模型之一。 ResNet-50 由微软亚
研究院的研究团队提出,是在 2015 年 ILSVRC 竞赛中取得了优异成绩的模型之一。
ResNet-50 是一个深度为 50 层的深度残差网络,其中包括卷积层、批量归一化层
和残差块等组件。在 ResNet-50 中,主要包含两种基本的块: Convolutional Block ( Conv
Block)和 Identity Block。通过这两个基本块的结合, ResNet-50 可以更深入地学习图像特征表示,同时通过残差连接帮助网络更好地训练和优化,使得 ResNet-50 成为一种有效的深度卷积神
经网络架构,在图像分类和特征提取任务中取得了显著的成功。
ResNet-50 的出现很好地解决了这些问题,其相比于其他深度神经网络
其特点是引入残差连接( residual connection)。
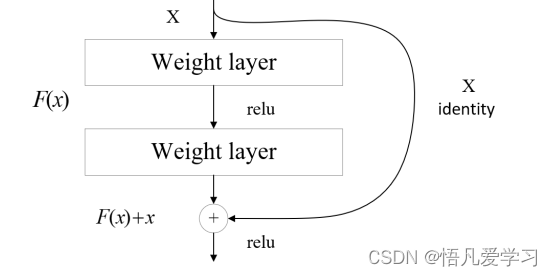
残差网络结构图
残差函数被定义为![]() ,其中 H (x) 表示网络的映射函数。当模型的
,其中 H (x) 表示网络的映射函数。当模型的
训练精度达到饱和时,多余的网络层的训练目标变为将残差结果逼近于 0,即令
F(x) 0 = ,从而实现恒等映射。这样做的目的是为了确保随着网络的加深,训练精度
不会下降。
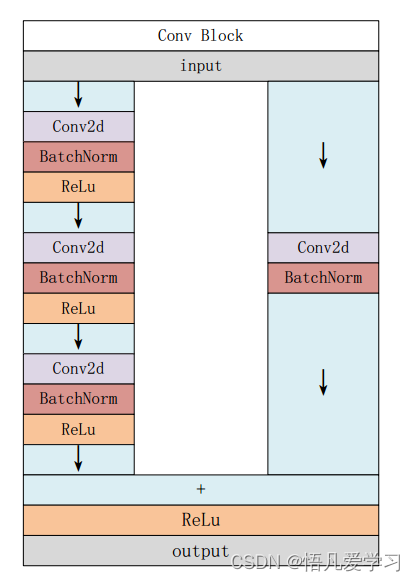
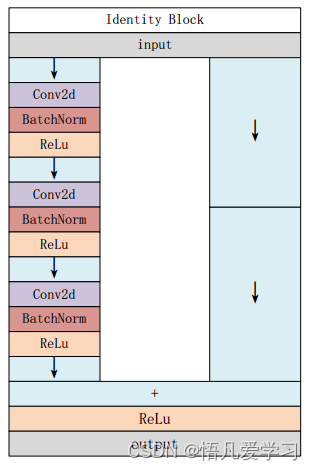
Conv Block 结构图 Identity Block 结构图
代码实现:
import math
import torch.nn as nn
from torch.hub import load_state_dict_from_url
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, stride=stride, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
#-----------------------------------#
# 假设输入进来的图片是600,600,3
#-----------------------------------#
self.inplanes = 64
super(ResNet, self).__init__()
# 600,600,3 -> 300,300,64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
# 300,300,64 -> 150,150,64
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=0, ceil_mode=True)
# 150,150,64 -> 150,150,256
self.layer1 = self._make_layer(block, 64, layers[0])
# 150,150,256 -> 75,75,512
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
# 75,75,512 -> 38,38,1024 到这里可以获得一个38,38,1024的共享特征层
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
# self.layer4被用在classifier模型中
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
#-------------------------------------------------------------------#
# 当模型需要进行高和宽的压缩的时候,就需要用到残差边的downsample
#-------------------------------------------------------------------#
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def resnet50(pretrained = False):
model = ResNet(Bottleneck, [3, 4, 6, 3])
if pretrained:
state_dict = load_state_dict_from_url("https://download.pytorch.org/models/resnet50-19c8e357.pth", model_dir="./model_data")
model.load_state_dict(state_dict)
#----------------------------------------------------------------------------#
# 获取特征提取部分,从conv1到model.layer3,最终获得一个38,38,1024的特征层
#----------------------------------------------------------------------------#
features = list([model.conv1, model.bn1, model.relu, model.maxpool, model.layer1, model.layer2, model.layer3])
#----------------------------------------------------------------------------#
# 获取分类部分,从model.layer4到model.avgpool
#----------------------------------------------------------------------------#
classifier = list([model.layer4, model.avgpool])
features = nn.Sequential(*features)
classifier = nn.Sequential(*classifier)
return features, classifier
2.2 区域建议网络RPN
RPN( Region Proposal Network,区域建议网络)是目标检测算法中的关键组件
之一,用于生成候选目标区域。 RPN 是一种基于深度学习的神经网络,通常与卷积
神经网络结合使用。其主要目的是在图像中生成一系列候选目标框,这些候选框可能
包含感兴趣的目标物体。
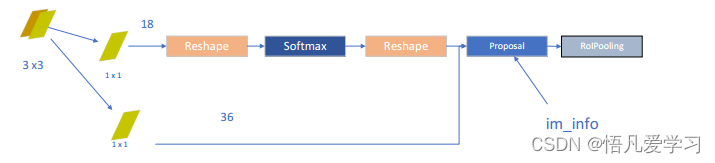
RPN 生成的特征层在图像中通常被称为公用特征层( Shared Feature Map)。这个
特征层有两个主要应用。一个是与 RoI 池化( Region of Interest Pooling)结合使用,
用于提取每个候选区域的固定大小的特征向量;另一个是经过一次 3×3 的卷积操作
后,然后进行一个 2×9 通道的 1×1 卷积和一个 4×9 通道的 1×1 卷积,用于产生 RPN
网络的最终输出,包括目标边界框的坐标调整和目标得分预测。通过这些步骤, RPN
能够有效地生成候选目标框,并为后续的目标检测提供高质量的区域提议,从而提高
整个 Faster R-CNN 系统的性能和效率。
代码实现:
import numpy as np
import torch
from torch import nn
from torch.nn import functional as F
from torchvision.ops import nms
from utils.anchors import _enumerate_shifted_anchor, generate_anchor_base
from utils.utils_bbox import loc2bbox
class ProposalCreator():
def __init__(
self,
mode,
nms_iou = 0.7,
n_train_pre_nms = 12000,
n_train_post_nms = 600,
n_test_pre_nms = 3000,
n_test_post_nms = 300,
min_size = 16
):
#-----------------------------------#
# 设置预测还是训练
#-----------------------------------#
self.mode = mode
#-----------------------------------#
# 建议框非极大抑制的iou大小
#-----------------------------------#
self.nms_iou = nms_iou
#-----------------------------------#
# 训练用到的建议框数量
#-----------------------------------#
self.n_train_pre_nms = n_train_pre_nms
self.n_train_post_nms = n_train_post_nms
#-----------------------------------#
# 预测用到的建议框数量
#-----------------------------------#
self.n_test_pre_nms = n_test_pre_nms
self.n_test_post_nms = n_test_post_nms
self.min_size = min_size
def __call__(self, loc, score, anchor, img_size, scale=1.):
if self.mode == "training":
n_pre_nms = self.n_train_pre_nms
n_post_nms = self.n_train_post_nms
else:
n_pre_nms = self.n_test_pre_nms
n_post_nms = self.n_test_post_nms
#-----------------------------------#
# 将先验框转换成tensor
#-----------------------------------#
anchor = torch.from_numpy(anchor)
if loc.is_cuda:
anchor = anchor.cuda()
#-----------------------------------#
# 将RPN网络预测结果转化成建议框
#-----------------------------------#
roi = loc2bbox(anchor, loc)
#-----------------------------------#
# 防止建议框超出图像边缘
#-----------------------------------#
roi[:, [0, 2]] = torch.clamp(roi[:, [0, 2]], min = 0, max = img_size[1])
roi[:, [1, 3]] = torch.clamp(roi[:, [1, 3]], min = 0, max = img_size[0])
#-----------------------------------#
# 建议框的宽高的最小值不可以小于16
#-----------------------------------#
min_size = self.min_size * scale
keep = torch.where(((roi[:, 2] - roi[:, 0]) >= min_size) & ((roi[:, 3] - roi[:, 1]) >= min_size))[0]
#-----------------------------------#
# 将对应的建议框保留下来
#-----------------------------------#
roi = roi[keep, :]
score = score[keep]
#-----------------------------------#
# 根据得分进行排序,取出建议框
#-----------------------------------#
order = torch.argsort(score, descending=True)
if n_pre_nms > 0:
order = order[:n_pre_nms]
roi = roi[order, :]
score = score[order]
#-----------------------------------#
# 对建议框进行非极大抑制
# 使用官方的非极大抑制会快非常多
#-----------------------------------#
keep = nms(roi, score, self.nms_iou)
keep = keep[:n_post_nms]
roi = roi[keep]
return roi
class RegionProposalNetwork(nn.Module):
def __init__(
self,
in_channels = 512,
mid_channels = 512,
ratios = [0.5, 1, 2],
anchor_scales = [8, 16, 32],
feat_stride = 16,
mode = "training",
):
super(RegionProposalNetwork, self).__init__()
#-----------------------------------------#
# 生成基础先验框,shape为[9, 4]
#-----------------------------------------#
self.anchor_base = generate_anchor_base(anchor_scales = anchor_scales, ratios = ratios)
n_anchor = self.anchor_base.shape[0]
#-----------------------------------------#
# 先进行一个3x3的卷积,可理解为特征整合
#-----------------------------------------#
self.conv1 = nn.Conv2d(in_channels, mid_channels, 3, 1, 1)
#-----------------------------------------#
# 分类预测先验框内部是否包含物体
#-----------------------------------------#
self.score = nn.Conv2d(mid_channels, n_anchor * 2, 1, 1, 0)
#-----------------------------------------#
# 回归预测对先验框进行调整
#-----------------------------------------#
self.loc = nn.Conv2d(mid_channels, n_anchor * 4, 1, 1, 0)
#-----------------------------------------#
# 特征点间距步长
#-----------------------------------------#
self.feat_stride = feat_stride
#-----------------------------------------#
# 用于对建议框解码并进行非极大抑制
#-----------------------------------------#
self.proposal_layer = ProposalCreator(mode)
#--------------------------------------#
# 对FPN的网络部分进行权值初始化
#--------------------------------------#
normal_init(self.conv1, 0, 0.01)
normal_init(self.score, 0, 0.01)
normal_init(self.loc, 0, 0.01)
def forward(self, x, img_size, scale=1.):
n, _, h, w = x.shape
#-----------------------------------------#
# 先进行一个3x3的卷积,可理解为特征整合
#-----------------------------------------#
x = F.relu(self.conv1(x))
#-----------------------------------------#
# 回归预测对先验框进行调整
#-----------------------------------------#
rpn_locs = self.loc(x)
rpn_locs = rpn_locs.permute(0, 2, 3, 1).contiguous().view(n, -1, 4)
#-----------------------------------------#
# 分类预测先验框内部是否包含物体
#-----------------------------------------#
rpn_scores = self.score(x)
rpn_scores = rpn_scores.permute(0, 2, 3, 1).contiguous().view(n, -1, 2)
#--------------------------------------------------------------------------------------#
# 进行softmax概率计算,每个先验框只有两个判别结果
# 内部包含物体或者内部不包含物体,rpn_softmax_scores[:, :, 1]的内容为包含物体的概率
#--------------------------------------------------------------------------------------#
rpn_softmax_scores = F.softmax(rpn_scores, dim=-1)
rpn_fg_scores = rpn_softmax_scores[:, :, 1].contiguous()
rpn_fg_scores = rpn_fg_scores.view(n, -1)
#------------------------------------------------------------------------------------------------#
# 生成先验框,此时获得的anchor是布满网格点的,当输入图片为600,600,3的时候,shape为(12996, 4)
#------------------------------------------------------------------------------------------------#
anchor = _enumerate_shifted_anchor(np.array(self.anchor_base), self.feat_stride, h, w)
rois = list()
roi_indices = list()
for i in range(n):
roi = self.proposal_layer(rpn_locs[i], rpn_fg_scores[i], anchor, img_size, scale = scale)
batch_index = i * torch.ones((len(roi),))
rois.append(roi)
roi_indices.append(batch_index)
rois = torch.cat(rois, dim=0)
roi_indices = torch.cat(roi_indices, dim=0)
return rpn_locs, rpn_scores, rois, roi_indices, anchor
def normal_init(m, mean, stddev, truncated=False):
if truncated:
m.weight.data.normal_().fmod_(2).mul_(stddev).add_(mean) # not a perfect approximation
else:
m.weight.data.normal_(mean, stddev)
m.bias.data.zero_()
2.3 分类与回归
Faster R-CNN 中的全连接层在目标检测任务中起到了重要的作用。通过学习特
征表示和进行目标分类,帮助模型识别和定位图像中的目标物体。
全连接层通常被添加在卷积层之后,以便提取更高级的特征表示。这些全连接层
的参数在训练过程中通过反向传播算法进行学习和更新,以使模型能够更准确地预测
目标的位置和类别。全连接层通常是在卷积层之后添加的,以便提取更高级的特征表
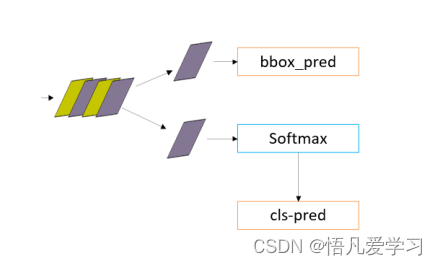
分类与回归
代码实现:
import warnings
import torch
from torch import nn
from torchvision.ops import RoIPool
warnings.filterwarnings("ignore")
class VGG16RoIHead(nn.Module):
def __init__(self, n_class, roi_size, spatial_scale, classifier):
super(VGG16RoIHead, self).__init__()
self.classifier = classifier
#--------------------------------------#
# 对ROIPooling后的的结果进行回归预测
#--------------------------------------#
self.cls_loc = nn.Linear(4096, n_class * 4)
#-----------------------------------#
# 对ROIPooling后的的结果进行分类
#-----------------------------------#
self.score = nn.Linear(4096, n_class)
#-----------------------------------#
# 权值初始化
#-----------------------------------#
normal_init(self.cls_loc, 0, 0.001)
normal_init(self.score, 0, 0.01)
self.roi = RoIPool((roi_size, roi_size), spatial_scale)
def forward(self, x, rois, roi_indices, img_size):
n, _, _, _ = x.shape
if x.is_cuda:
roi_indices = roi_indices.cuda()
rois = rois.cuda()
rois_feature_map = torch.zeros_like(rois)
rois_feature_map[:, [0,2]] = rois[:, [0,2]] / img_size[1] * x.size()[3]
rois_feature_map[:, [1,3]] = rois[:, [1,3]] / img_size[0] * x.size()[2]
indices_and_rois = torch.cat([roi_indices[:, None], rois_feature_map], dim=1)
#-----------------------------------#
# 利用建议框对公用特征层进行截取
#-----------------------------------#
pool = self.roi(x, indices_and_rois)
#-----------------------------------#
# 利用classifier网络进行特征提取
#-----------------------------------#
pool = pool.view(pool.size(0), -1)
#--------------------------------------------------------------#
# 当输入为一张图片的时候,这里获得的f7的shape为[300, 4096]
#--------------------------------------------------------------#
fc7 = self.classifier(pool)
roi_cls_locs = self.cls_loc(fc7)
roi_scores = self.score(fc7)
roi_cls_locs = roi_cls_locs.view(n, -1, roi_cls_locs.size(1))
roi_scores = roi_scores.view(n, -1, roi_scores.size(1))
return roi_cls_locs, roi_scores
class Resnet50RoIHead(nn.Module):
def __init__(self, n_class, roi_size, spatial_scale, classifier):
super(Resnet50RoIHead, self).__init__()
self.classifier = classifier
#--------------------------------------#
# 对ROIPooling后的的结果进行回归预测
#--------------------------------------#
self.cls_loc = nn.Linear(2048, n_class * 4)
#-----------------------------------#
# 对ROIPooling后的的结果进行分类
#-----------------------------------#
self.score = nn.Linear(2048, n_class)
#-----------------------------------#
# 权值初始化
#-----------------------------------#
normal_init(self.cls_loc, 0, 0.001)
normal_init(self.score, 0, 0.01)
self.roi = RoIPool((roi_size, roi_size), spatial_scale)
def forward(self, x, rois, roi_indices, img_size):
n, _, _, _ = x.shape
if x.is_cuda:
roi_indices = roi_indices.cuda()
rois = rois.cuda()
rois_feature_map = torch.zeros_like(rois)
rois_feature_map[:, [0,2]] = rois[:, [0,2]] / img_size[1] * x.size()[3]
rois_feature_map[:, [1,3]] = rois[:, [1,3]] / img_size[0] * x.size()[2]
indices_and_rois = torch.cat([roi_indices[:, None], rois_feature_map], dim=1)
#-----------------------------------#
# 利用建议框对公用特征层进行截取
#-----------------------------------#
pool = self.roi(x, indices_and_rois)
#-----------------------------------#
# 利用classifier网络进行特征提取
#-----------------------------------#
fc7 = self.classifier(pool)
#--------------------------------------------------------------#
# 当输入为一张图片的时候,这里获得的f7的shape为[300, 2048]
#--------------------------------------------------------------#
fc7 = fc7.view(fc7.size(0), -1)
roi_cls_locs = self.cls_loc(fc7)
roi_scores = self.score(fc7)
roi_cls_locs = roi_cls_locs.view(n, -1, roi_cls_locs.size(1))
roi_scores = roi_scores.view(n, -1, roi_scores.size(1))
return roi_cls_locs, roi_scores
def normal_init(m, mean, stddev, truncated=False):
if truncated:
m.weight.data.normal_().fmod_(2).mul_(stddev).add_(mean) # not a perfect approximation
else:
m.weight.data.normal_(mean, stddev)
m.bias.data.zero_()
3 实验环境需求
1.不是30系列显卡的电脑使用
| 环境 | 版本 |
| Python | 3.6.0 |
| Pytorch | 1.2.0 |
| Torchvision | 0.4.0 |
| Cuda | v10.0 |
| Cudnn | 10.0 |
2.30系列显卡及其以上的
| 环境 | 版本 |
| Python | 3.7.0 |
| Pytorch | 1.7.1 |
| Torchvision | 0.8.2 |
| Cuda | v11.0 |
| Cudnn | 11.0 |
4 数据集说明
数据集标签:1 RiceBlast (稻瘟病)、2 BacterialBlight (细菌性枯萎病)、3 BrownSpot(褐斑病)

5 实验结果
测试结果:



两种不同模型的测试结果(ResNet-50为左边图像,VGG-16为右边图像。
MAP测试对比图:
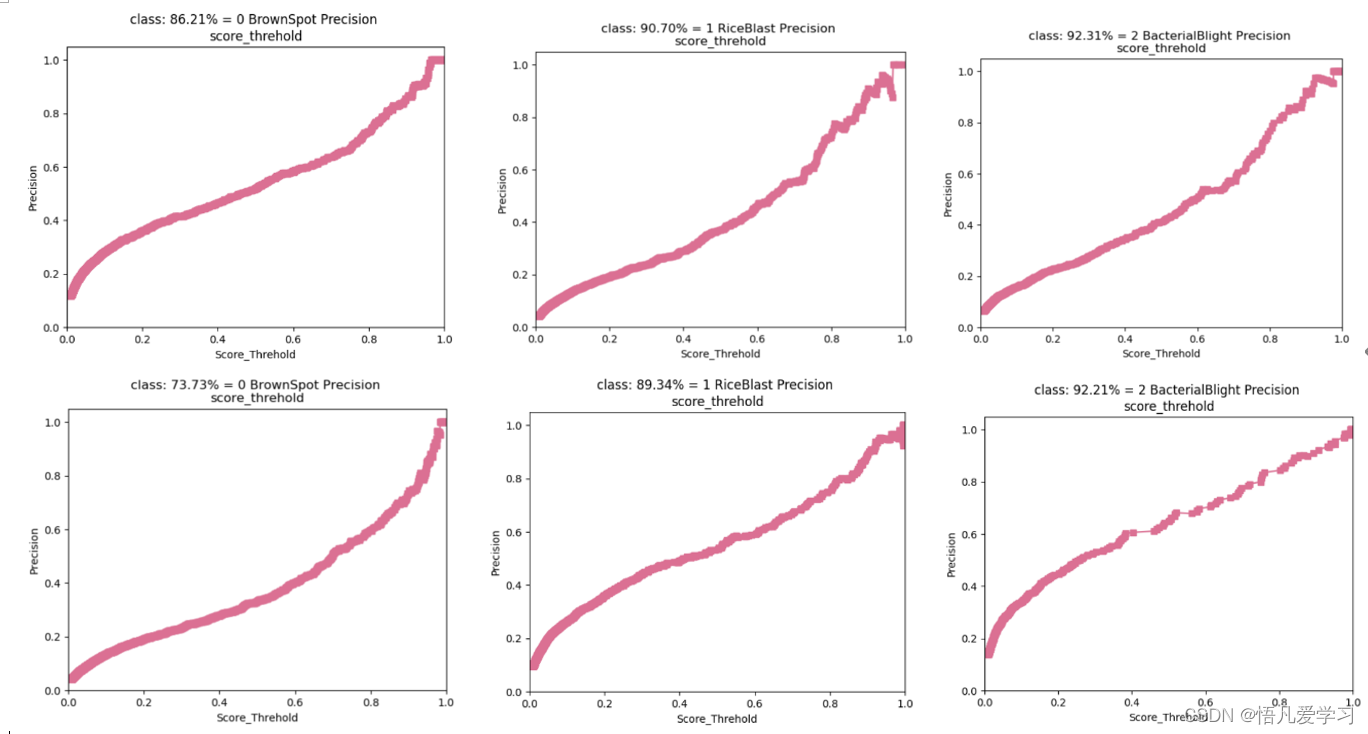
结果:
使用ResNet-50模型对BrownSpot、RiceBlast、BacterialBlight的平均识别准确率分别比VGG-16提高12.48%、1.36%和0.1%,整体的准确率提升4.65%。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









