







减少循环,提高运行效率,灵感来源,实习接的一些需求,看到运行时间预计要几小时那瞬间奔溃有点
- 情景: 增加一列进行打标分几个类别
套两个循环 结果

用isin()优化后
for j in tqdm(range(len(bcc_brand_list))):
df.loc[df['brand_name'].isin(bcc_brand_list), 'category'] = 'BCC'
for j in tqdm(range(len(fc_brand_list))):
df.loc[df['brand_name'].isin(fc_brand_list), 'category'] = 'FC'
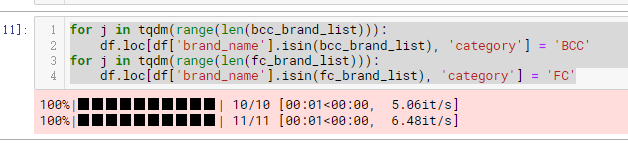
2,3秒就好了,快了上千倍
2. 同理 循环一个个判断字符串的哇也很久
优化方案用contains()
last_data['buzz'][i] = temp.loc[temp['keywords'].str.contains(last_data['keyword_2'][i])]['buzz'].sum()
- 类似求超多词语词频的情况, 可以借用jieba分词时用的思路
用Counter() - 有时对于两个循环遍历的, 而且数据量很大,达到千万级别, 可以可以考虑分段减少循环 结合实际情况break等等方法都可以实现
总结
感觉接触点有趣的东西, 打算找本相关的书来看一下

努力继续更新上来
偶尔发现的apply函数的新用法
我一般是在dataframe格式的数据里面用
data['A'] = data['A'].apply(lambda x:x+2)
就是一般我是针对某一列进行处理
现在发现可以同时对某几列一起处理
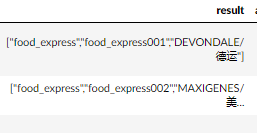
data['result'] = data.apply(lambda x: '["'+'","'.join([x['industry'],x['brand_id'],x['brand_name']])+'"]',axis=1)
对几列进行操作合并
联想到groupby一下可以多行变一行的感觉
总结
专栏学习
01 【数据分析实战项目】: 无人智能售货机商务分析、 线上课程智能推荐、 学术前沿趋势分析
02 【算法--数据挖掘】: 机器学习----吃瓜教程!、 集成学习、 深度学习 学术前沿趋势分析
03 【天池数据挖掘竞赛】: 心电信号多分类分类、 新闻推荐入门赛系统项目
04 【Python数据分析】: Numpy 数值计算基础、 Matplotlib 数据可视化基础、 Pandas 统计分析基础、 Pandas 进行数据预处理、 scikit-learn 构建模型
往期精彩内容
01 【常见的数据分析师的面试问题】: 基础知识考查、概率论与数理统计、数据挖掘、常见模型介绍、数据分析师工作必备技能等等
02 【基于条件随机场模型的中文分词】: 中文分析、python代码实现
03 【 Github开源项目】: Github开源项目 数分/数挖学习路线
欢迎关注我,一起交流学习探索数据分析的世界,洞察数据!努力接受社会毒打~~

















 2506
2506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











