







文章目录
前言
YOLO v2 通过引入锚框、改进网络结构、优化训练策略等方式,在检测精度、速度和泛化能力上都有显著提升,为后续 YOLO 系列(如 YOLO v3、v4、v5)奠定了基础。
一、yolo-v1 与yolo-v2的对比
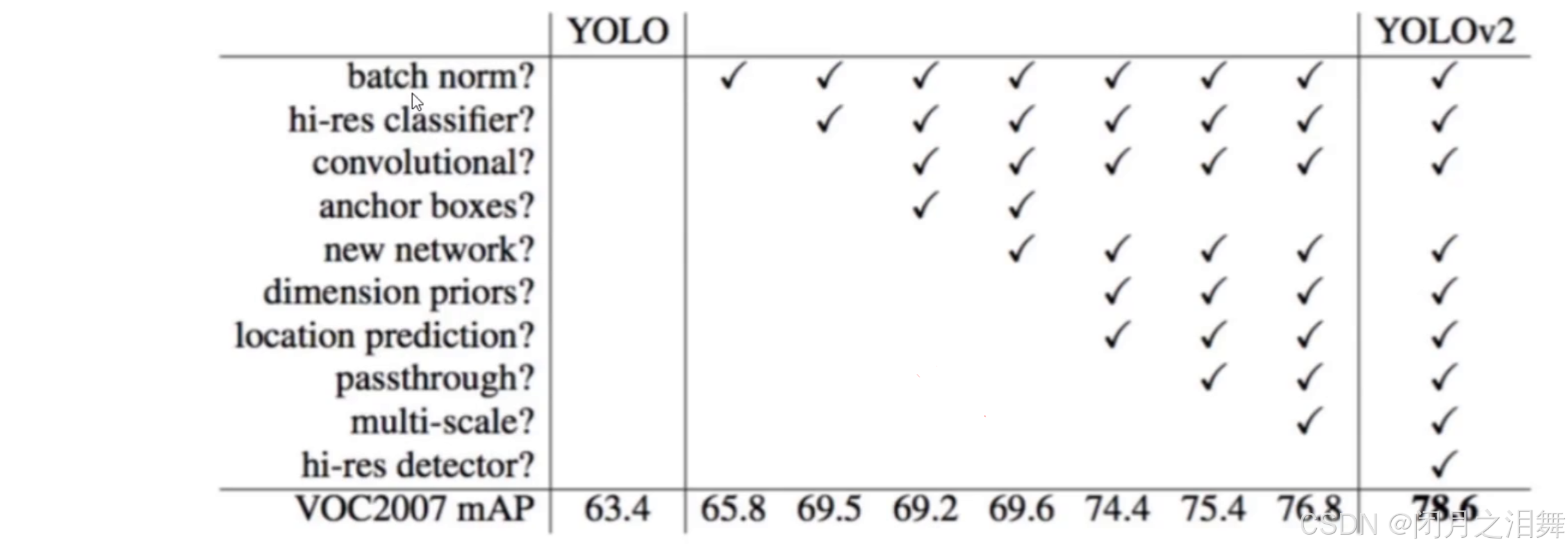
通过上图可以发现,yolo-v2在yolo-v1的基础上增加了多种不同的处理方式,通过观察,通过增加这些手段,模型的mAP指标不断上升,最终的mAP指标的值达到了78.6,相比yolo-v1模型增加了15.2,可以说模型性能有了极大程度的提升。
二、Batch Norm(归一化)
核心思想
Batch Normalization通过对每一层的输入进行归一化处理,使其均值接近0、方差接近1,从而稳定训练过程,减少内部协变量偏移(Internal Covariate Shift)。


优点
加速训练:允许使用更高学习率,减少对初始化的敏感度。
稳定梯度:缓解梯度消失/爆炸问题。
轻微正则化:每个batch的统计量引入噪声,类似Dropout效果。
局限性
小批量问题:batch size过小时统计量估计不准确,可改用Layer Normalization等替代方法。
测试依赖移动平均:需额外维护统计量,增加实现复杂度。
三、yolo v2中的核心思想
1、batch norm在v2模型
V2版本舍弃Dropout,卷积后加入Batch Normalization,网络的每一层输入都做了归一化,收敛相对容易,经过Batch Normalization处理后的网络会提升2%的MAP值,从现在的角度来看,Batch Normalization已经成为网络的必备处理。
YOLO-V2有更大的分辨率
V1训练时用的是224224,测试时使用的时448448,可能导致模型水土不服,v2模型训练时额外又进行了10次448*448的微调,当使用高分辨率分类器后,YOLOv2的mAP提升了约4%

2、YOLO-v2-网络结构
yolo模型底层使用的都是DarkNet模型,实际输入为416416,没有全连接层(FC),经历五次降采样,图片尺寸压缩到1313,1*1卷积节省了很多的参数。
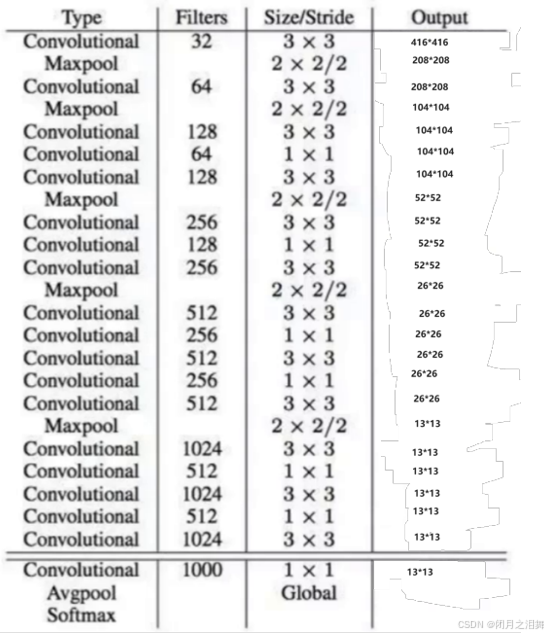
这里模型的结构中做了若干次的卷积,五次最大池化,最终做了一次全局平均池化并经历了softmax激活。
3、YOLO-V2-聚类提取先验框
在模型训练之前,提前把训练集的标签值提取出来,通过k-means聚类的方法,聚类出5个类别。结果当作是先验框。最后在进行模型训练。
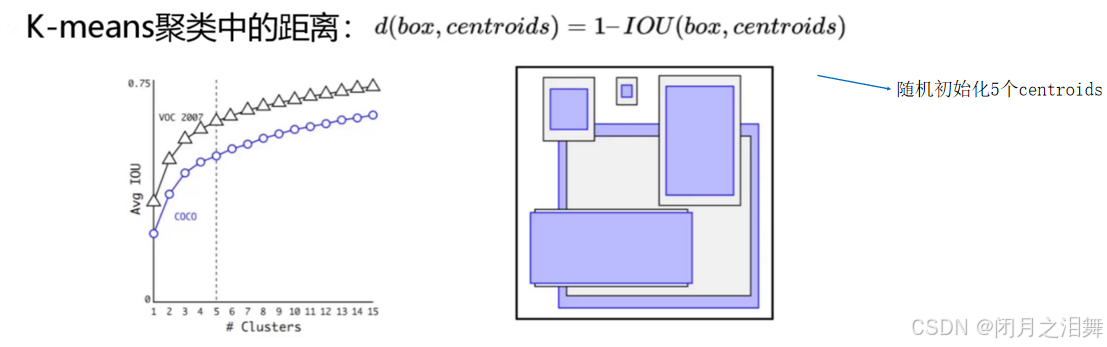
faster-rcnn系列选择的先验比例都是常规的,但是不一定完全适合数据集。
4、Anchor Box(锚框)
通过引入anchor boxes,使得预测的box数量更多(1313n)跟faster-rcnn系列不同的是先验框并不是直接按照长宽固定比给定

由上图可以看出,使用锚框和不使用锚框mAP指标变化不大,但是召回率却有显著提升。
5、Directed Location Prediction(直接位置预测)
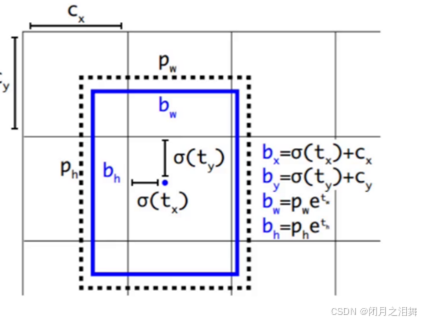
Directed Location Prediction是一种方法,其目的是进行位置微调,预测偏移量。它用于限制偏移量,以防止在训练时出现发散。这种方法预测的是相对位置,即相对于网格的偏移量。模型输出的值为tx、ty。

预测的偏移量包括tx、ty、tw、th(第一次为先验框及初始化的中心坐标在模型中输出的结果与真实框损失值得到的偏移量值)。调整后的预测值bx、by、bw、bh是通过计算得到的。
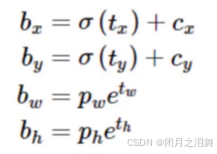

6、感受野
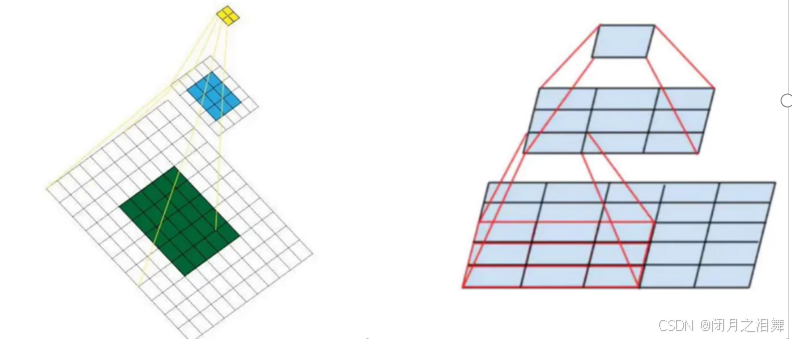
感受野就是特征图上的点能看到原始图像多大区域
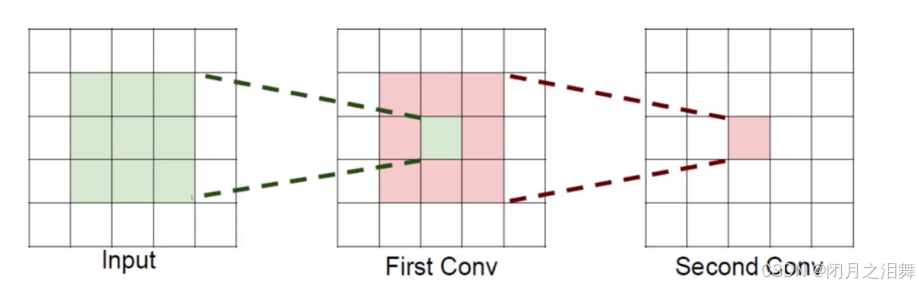
如果堆叠3个33的卷积层,并保持滑动窗口步长为1,其他感受野就是77的了,这跟一个使用77卷积核的结果是一样的,但是使用三个33的卷积核的参数量小于7*7的。

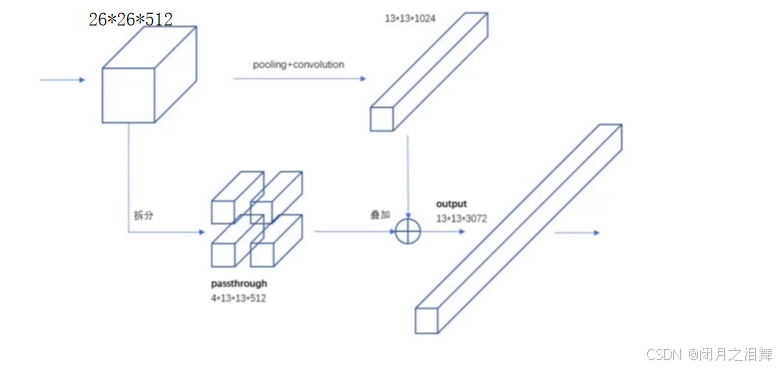
7、yolo-v2-Grained Features
Grained Features(粒度特征) 是机器学习与计算机视觉中用于描述数据或特征在不同层次或细节上的表示方式。根据粒度的不同,特征可分为 细粒度(Fine-Grained) 和 粗粒度(Coarse-Grained) 两类,分别对应特征的细节信息和抽象信息。
细粒度特征(Fine-Grained Features)
定义:关注数据的细微差异,捕捉同一大类下子类或实例间的局部区别。
粗粒度特征(Coarse-Grained Features)
定义:关注整体结构或宏观模式,忽略细节差异。
在进行多尺度特征融合任务时,结合不同粒度的特征提升模型性能(如目标检测、语义分割)。
最后一层时感受野太大了,小目标可能丢失了,需融合之前的特征
8、Multi-Scale
Multi-Scale(多尺度) 是计算机视觉、图像处理及深度学习中的核心方法,旨在通过不同尺度的特征或输入数据捕捉目标的多层次信息,从而提升模型对复杂场景的适应能力。
多尺度方法的核心在于 利用不同尺度的信息互补性:
粗尺度(大感受野):捕捉全局结构、语义信息(如物体类别、场景布局)。
细尺度(小感受野):保留局部细节(如边缘、纹理、小物体)。
融合不同尺度的特征:结合全局与局部信息,增强模型对尺度变化、遮挡和小目标的鲁棒性。
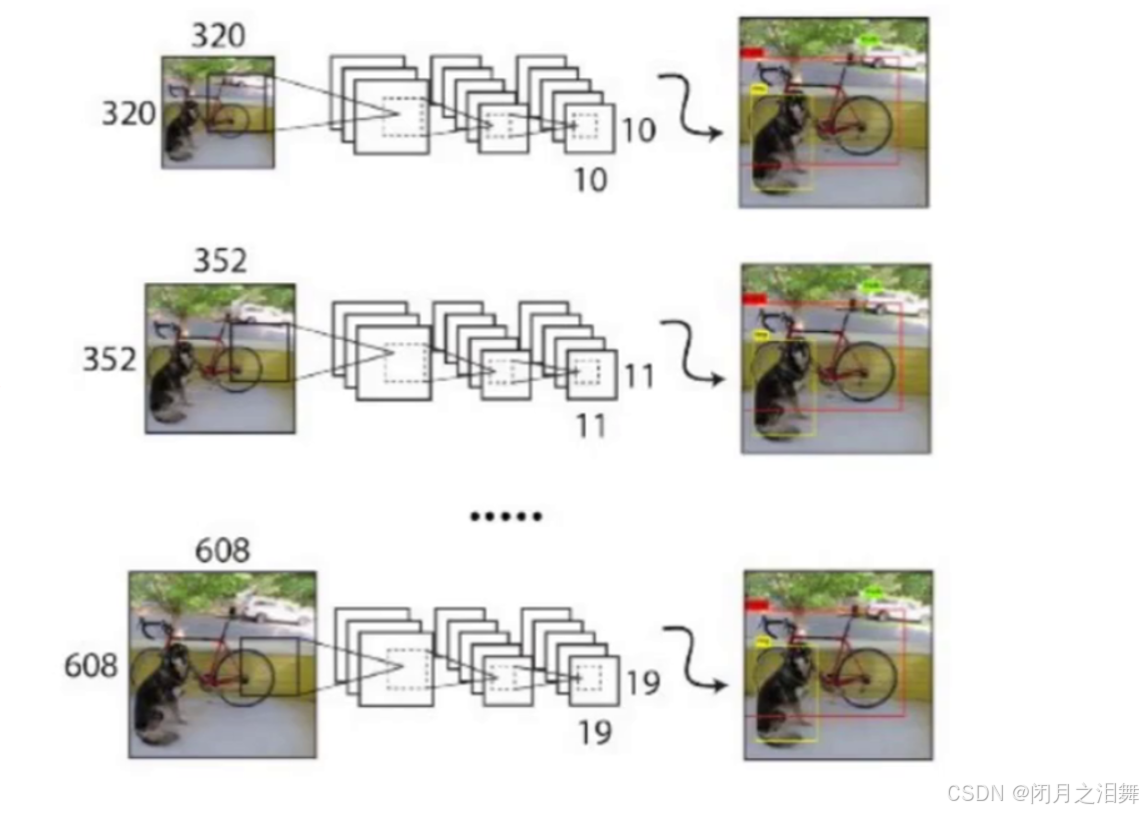
整个网络结构不包含全连接层,因此输入图片的大小可以任意
最小的图像尺寸为320320
最大的图像尺寸为608608
注意:输入的图片应该需要被32整除。
总结
YOLO v2 相比 YOLO v1 引入了锚框机制(含 K-means 聚类确定锚框尺寸)、批归一化、Darknet-19 全卷积骨干网络、多尺度训练、细粒度特征融合(passthrough 层)、直接位置预测优化训练稳定性,以及支持分类与检测数据集联合训练的框架,显著提升了检测精度、速度和泛化能力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









