






HashSet 传入对象,怎么过滤
首先,我们知道所有的Set里面都套了一个Map,使用Map的Key存值,Value存放一个固定的Object,这是适配器模式。源码如下:
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* default initial capacity (16) and load factor (0.75).
*/
public HashSet() {
map = new HashMap<>();
}
/**
* Constructs a new set containing the elements in the specified
* collection. The <tt>HashMap</tt> is created with default load factor
* (0.75) and an initial capacity sufficient to contain the elements in
* the specified collection.
*
* @param c the collection whose elements are to be placed into this set
* @throws NullPointerException if the specified collection is null
*/
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* the specified initial capacity and the specified load factor.
*
* @param initialCapacity the initial capacity of the hash map
* @param loadFactor the load factor of the hash map
* @throws IllegalArgumentException if the initial capacity is less
* than zero, or if the load factor is nonpositive
*/
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* the specified initial capacity and default load factor (0.75).
*
* @param initialCapacity the initial capacity of the hash table
* @throws IllegalArgumentException if the initial capacity is less
* than zero
*/
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
/**
* Constructs a new, empty linked hash set. (This package private
* constructor is only used by LinkedHashSet.) The backing
* HashMap instance is a LinkedHashMap with the specified initial
* capacity and the specified load factor.
*
* @param initialCapacity the initial capacity of the hash map
* @param loadFactor the load factor of the hash map
* @param dummy ignored (distinguishes this
* constructor from other int, float constructor.)
* @throws IllegalArgumentException if the initial capacity is less
* than zero, or if the load factor is nonpositive
*/
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
......
}那么问题来了,如果传入两个对象,是什么决定它们是不是相等的,旧的会不会替换新的对象,以及怎么替换或者不替换呢?
我们来看下add方法
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
实际调用的是HashMap的添加方法,只不过是value是成为一个全局变量PRESENT。这时map是一个全局变量指向创建HashSet对象时创建的HashMap对象。
另外add方法的返回值类型是boolean,所以如果返回值是null那么表示添加成功。
探究.add方法也即是探究.put方法。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}下面我们结合一个例子分析源码。
HashSet<String> set = new HashSet<>();
set.add("Tom");
set.add("Tom");
set.add("new String Tom");- 第一次添加元素的过程:set.add(“Tom”);
首先定义Node<K,V>[] tab;意思是创建一个名为tab的Node节点集合,然后if ((tab = table) == null || (n = tab.length) == 0)对比tab和table是否为空,因为table是全局变量所以程序运行开始之前初始值null,判断为true,所以不用判断(n = tab.length) == 0,直接执行 n = (tab = resize()).length;,resize方法打开底层并没有看懂,但是知道是返回值是newTab,其实此时tab已经是被替换了成为长度为16的数组,n等于tab的长度最大值是16,接下来判断p = tab[i = (n - 1) & hash]) == null 其中因为i的范围是0~15,所以n-1来控制防止数组溢出,至于&hash是程序自动编译计算得来的tab的地址(在第三种情况我会详细描述)。这样就执行tab[i] = newNode(hash, key, value, null);不执行else,直接执行图中代码(源代码的最后一段)
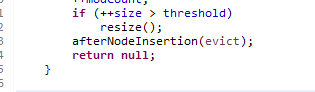
返回值是null,所以put方法完成返回值null,然后boolean判断是turn,.add方法完成。
- 情况二:添加了相同元素时,set.add(“Tom”);如何执行?
下面讨论第二种情况:如果添加了相同元素时,add方法是如何进行判断的:?
HashSet<String> set = new HashSet<>();
set.add("Tom");
set.add("Tom");
此时已经在set集合中添加了一个tom元素,要再添加一个tom,这是putVal是这么运行的,首先执行 if ((tab = table) == null || (n = tab.length) == 0)此时的table已经被第一次添加元素时赋值所以不是null,tab.length明显也不为0,所以接下来执行if ((p = tab[i = (n - 1) & hash]) == null)由于此时的添加的元素的tab和第一次添加的tab,元素是一样的所以tab也是一样的,其找寻的地址也是一样的,所以第二次找到的地址不是null,那么加下来就要执行else if了,进行判读下面语句
if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k)))) p指向第一次的tab[],由于添加的元素相同所以hash、key都相同,所以判断成功,进行下一步e=p;e指向p,p指向tab[i],
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
判断e不等于null,执行V oldValue = e.value;,接下来判断if (!onlyIfAbsent || oldValue == null),onlyIfAbsent 是false,所以!onlyIfAbsent是true,所以返回值是 oldValue,这是put接受到的返回值不是null所以就添加失败。
情况三:添加String类型,set.add(“new String Tom”);的执行过程
HashSet<String> set = new HashSet<>();
set.add("Tom");
set.add(new String("Tom"));//思考:怎么判断不允许重复?
此时默认添加第一个元素,直接分析添加第二个元素的情况。
在分析之前我们看一下下面的程序,
public static void main(String[] args) {
String name1="Tom";
System.out.println(name1.hashCode());
String name2=new String("Tom");
System.out.println(name2.hashCode());
System.out.println(name1==name2);
}
输出结果:
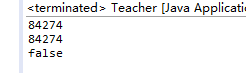
这个时候我们知道虽然==运行的结果是false, 但是.hashCode找到的地址相同,弄清楚这个有助于下面我们详细分析。
此时添加第二个String new “Tom”,首先判断if((tab = table) == null || (n = tab.length) == 0)因为第一次添加了元素,table已经不为空,另外n也不为0,下一行中 n = (tab = resize()).length不执行,所以n依旧是第一次存入元素的n值,之后执行下一个if语句:if ((p = tab[i = (n - 1) & hash]) == null),此时那由于hash值、n值一样,所以p不变,也不为null,判断结果是false进入else,执行下一个if语句
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
p.hash == hash 我们在本分析开头已经分析过,虽然==运行的结果是false但是.hashCode找到的地址相同,所以这个判断是true,又因为key也相同都是Tom,所以整体判断为true,e指向p,p指向tab[i],所以e指向tab[i],接下来执行下列程序:
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
e指向p,所以e不为null,将e.value赋值给oldValue,继续判断onlyIfAbsent不为null,将新Tom的value 把旧的Tom的value覆盖,这就可以将用于hashMap的add方法解释通。最后返回值是oldValue,是一个常量,所以不为null,put接受到不为null所以add方法就不会添加成功。
- 其他:通过重写hashCode方法和equals方法达到让student类通过id属性,控制不填加相同id的目的。
首先第一步:先重写一下hashCode方法,看能不能达到要求:
public class Student {
private String id;
public Student(String id) {
this.id = id;
}
@Override
public int hashCode() {
return id.hashCode();
}
public static void main(String[] args) {
HashSet<Student> set =new HashSet<Student>();
set.add(new Student("110"));
set.add(new Student("110"));
}
}
此时运行代码发现是可以的,添加进去了,而且输出set.seize();也是2.

上面两个Student对象的hashCode()值不一样,所以能添加成功。
现在我们结合源码分析一下为什么第二次会添加成功了:
if ((tab = table) == null || (n = tab.length) == 0)//tab不为空,length也不为0,所以下一个if
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)//p是上一个添加的Student也明显不为空,执行else
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))//哈希值是一样的,但是key是不一样的,所以判断key也不为空,但是key和k(p.key)是不一样的,所以那就进行下一个else if
e = p;
else if (p instanceof TreeNode)//明显判断不对,所以进行下一个else
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {//此时没有对binCount进行设限,所以是一个死循环
if ((e = p.next) == null) {//这里p.next指向e
p.next = newNode(hash, key, value, null);//这里把第二个对象存进去
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);//这个代码无论执不执行,都会执行下一部的break,跳出循环。
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key//判断不为空,所以向下执行
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;//最终是执行到这里,返回值是null,所以添加成功了!
如果是这样的话,是不能实现让student类通过id属性,控制不填加相同id的目的,所以我们如何进行优化?

看到这里之后,想到如果添加相同元素不成功是因为当时这里的key是相同的,但是我们如何把它改为通过判断id相同,而让条件成立,重写equals方法即可,代码如下。
public boolean equals(Object obj) {//obj对象上转型,Object四所有类的父类
if (obj instanceof Student) {//此时就是判断obj是否是Student类
Student stu = (Student) obj;//对象上转型,值得回忆的是,对象下转型的公式是:子类 子类对象 = (子类)父类对象。
return this.id.equals(stu.id);
}
return false;
}















 5266
5266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









