






一、内存分配模型
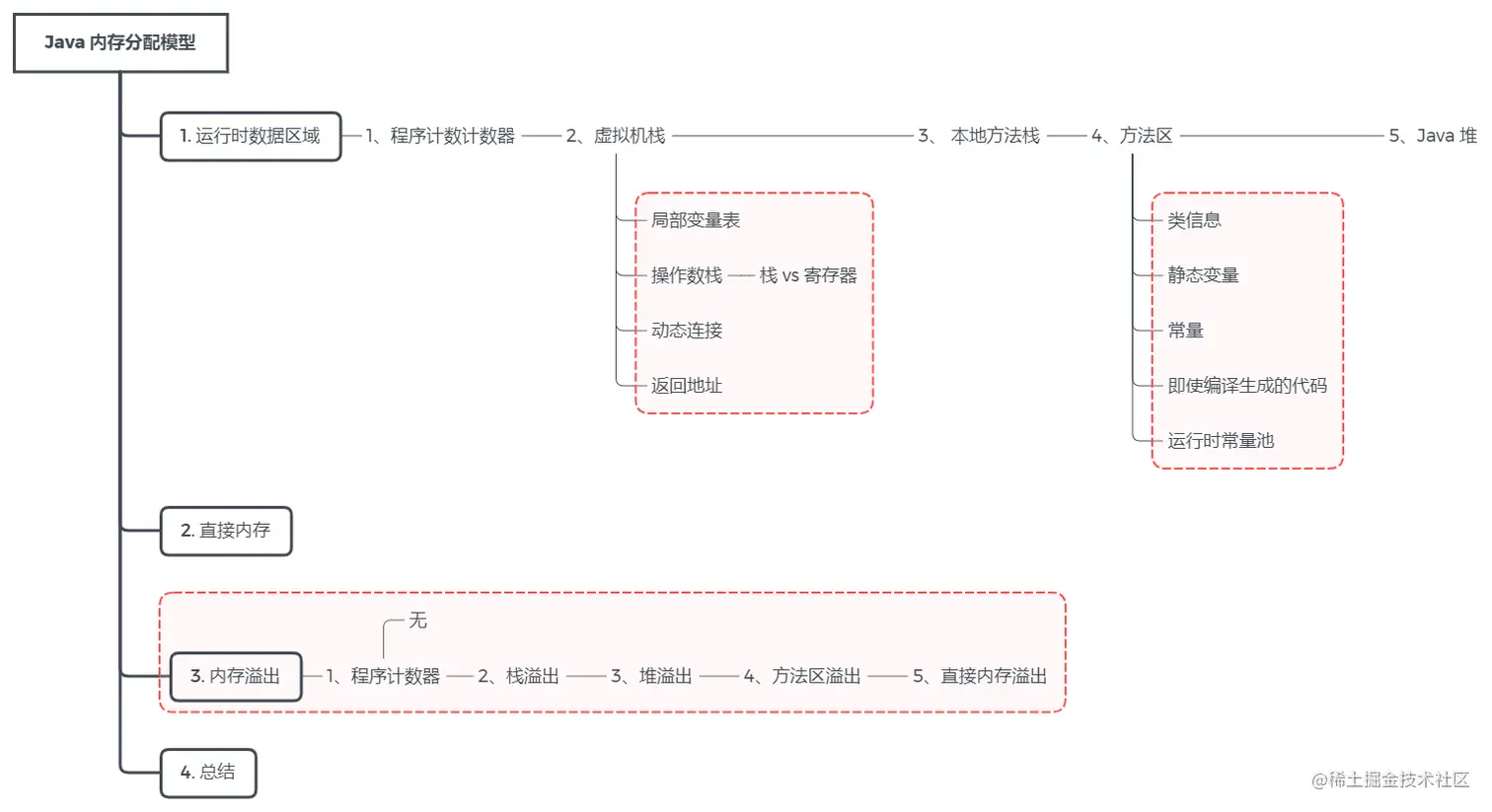
1. 运行时数据区域
根据《Java虚拟机规范》的规定,Java 虚拟机在执行程序时,会将内存划分为不同的数据区域:
| 内存区域 | 线程独占 |
|---|---|
| 程序计数寄存器 | 私有 |
| Java 虚拟机栈 | 私有 |
| 本地方法栈 | 私有 |
| Java 堆 | 共享 |
| 方法区 | 共享 |

—— 图片引用自网络
1.1 程序计数寄存器(Program Counter Register)
程序计数寄存器记录的是当前线程下一条准备执行执行的字节码行号。当虚拟机在进行顺序执行、分支、循环、函数调用或异常处理时,都会将「下一条字节码指令的行号」存储在程序计数器中。
为什么 Java 虚拟机需要这个程序计数器呢,这是为了保证正确地进行线程切换。操作系统的「时间片轮转机制」会为每个线程分配时间片,当一个线程的时间片用完,或者其他线程提前抢夺 CPU 时间片时,当前线程就会挂起,而将来挂起的线程获得时间片时,就需要通过程序计数器来恢复到正确的指令位置。
程序计数器只在执行 Java 方法时有意义,如果当前线程执行的是 native 方法,程序计数器的值是空(Undefined)。
1.2 虚拟机栈(Java Virtual MachineStack)
虚拟机栈描述的是 Java 方法执行的内存模型。虚拟机在执行方法时会创建一个栈帧(Stack Frame),每个方法从调用到结束的过程,都对应着一个栈帧入栈到出栈的过程。
- 入栈:创建对应的栈帧,压入虚拟机栈;
- 出栈:恢复上层方法中的局部变量表和操作数栈,如果有返回值,将返回值入栈,最后调整程序计数器指向方法调用指令的下一条执行。当所有栈帧都出栈后,线程结束。
提示: 栈的默认大小是 1M,可以用虚拟机参数
-Xss调整大小。
1.2.1 栈帧
栈帧是支持虚拟机进行方法调用和方法执行的数据结构,每个栈帧都包含四个区域:
- 1、局部变量表(Local Variable Table)
存放局部变量,当一个变量不再使用时,对应的空间会让出来给其他变量使用,这块区域的大小在编译时确定。
- 2、操作数栈(Operand Stack)
用于存放字节码指令的操作数,这块区域的大小在编译时确定。在虚拟机的具体实现中,这这块区域可能是寄存器,也可能是栈。所谓 “基于栈的解释执行”,这里的栈指的是操作数栈。
-
3、动态连接(Dynamic Linking)
-
4、返回地址
返回地址存放函数调用位置的下一行指令,用于在方法正常返回时返回到上一层方法继续执行。如果是异常返回的话,则是通过异常处理器表来确定。

—— 引用自 paul.pub/android-dal… 强波(华为)著
1.2.2 栈 vs 寄存器
在《Java虚拟机规范》中,操作数栈是一个栈数据结构,但在虚拟机的具体实现里,也可能是寄存器结构。
- 基于栈的解释执行 —— Java 虚拟机
- 基于寄存器的解释执行 —— Android 虚拟机(Dalvik & ART)
易错: 这里的栈和寄存器都是虚拟机的虚拟实现,和 CPU 中的数据寄存器并不是同一个概念。
基于寄存器的虚拟机栈帧中没有操作数栈和局部变量表,取而代之的是虚拟寄存器。与 Java 虚拟机相比,基于寄存器的 Android 虚拟机的指令数明显较少,同时也避免了操作数栈和局部变量表之间的数据移动。
1.2.3 栈的优化技术
- 编译优化:方法内联
方法内联的就是把目标方法的代码复制到调用位置,避免方法调用的出栈入栈行为。
- 栈帧数据共享
一般两个栈帧的内存区域是独立的,而在大多数虚拟机实现中,会将两个栈帧中的下层栈帧的「操作数栈」和上层栈帧的「部分局部变量」重叠,这样在方法调用的时候就不用进行额外的参数复制了。

—— 图片引用自网络
1.3 本地方法栈(Native Method Stacks)
与虚拟机栈类似,区别在于虚拟机栈执行 Java 方法,而本地方法栈执行 native 方法。当虚拟机调用 native 方法时,不会在虚拟机栈中创建栈帧,而是直接动态链接调用 native 方法。
提示: 《Java虚拟机规范》没有强制规定本地方法栈中方法语言、使用方式与数据结构,有的虚拟机(如 HotSpot)直接合并了虚拟机栈和本地方法栈。
1.4 方法区(Method Area)
1.4.1 方法区的数据
方法区主要存放虚拟机加载的类相关数据,包括:
- 类信息
- 静态变量
- 静态常量
- 运行时常量池
- 即时编译器生成的代码
「Class 文件常量池」和「运行时常量池」是比较容易混淆的概念。其实它们一个是静态的,一个是动态的。
「Class 文件常量池(Constant Pool Table)」是静态的,指的是编译后存放在 Class 文件常量池中的字面量 & 符号引用,而这些常量会在类加载之后进入运行时常量池。
「运行时常量池」是动态的,Java 不要求常量只能在编译时声明,在运行时同样可以将新的常量加入到常量池中。例如 String#intern()。
提示: 所谓字符串常量池属于运行时常量池的一部分。
1.4.2 方法区 ? 永生代 ? 元空间 ?
这三个概念也是比较容易混淆的,简单来说:方法区是虚拟机规定的运行时数据区域,永久代 & 元空间是方法区在不同虚拟机上的具体实现。
以 HotSpot 虚拟机为例:
在 JDK 1.7 之前,HotSpot 虚拟机使用永久代(Permanent Generation)来实现方法区,永久代中存储的都是生命周期较长的数据。永久代可以跟堆一起执行垃圾回收。不过在永久代执行垃圾回收的 “性价比” 并没有新生代高,一般新生代垃圾回收可以回收 70% ~ 95% 的空间,而永久代的垃圾回收率就远低于此。
从 JDK 1.8 开始,HotSpot 虚拟机使用元空间(Metadata)来实现方法区,并且使用了本地内存存储,扩展了方法区的内存上限。
为什么 HotSpot 要使用元空间来代替永久代呢?
因为永久代空间有限,经常出现不够用或者内存溢出异常。而使用本地内存就可以方便扩展方法区的大小。当然,元空间也不是完美的,因为机器总内存是有限的,使用大量的本地内存的话就会挤压堆内存的上限。
1.5 Java 堆(Java Heap)
堆是虚拟机上最大的一块内存,绝大多数对象都是存储在堆上的(Class 对象存储在方法区,满足逃逸分析的对象在栈上分配)。垃圾回收机制操作的主要区域也是堆。
堆和方法区都是线程共享的,为什么 Java 区分出两块区域呢?
这体现的是 动静分离 的思想,堆中存放的是生命周期比较短,经常需要进行垃圾回收的数据;而方法区中存放的是生命周期比较长的数据。将两种数据分开存储,有利于更高效地进行内存管理。
2. 直接内存 / 堆外内存 / 本地内存
这三个概念其实是相同的,直接内存(Direct Memory)不属于 Java 虚拟机规定的运行时数据区域。不受制于 Java 堆大小限制,但是受制于机器总内存。
在 JDK 1.4 NIO 中引入了基于通道(Channel)与缓冲区(Buffer)的 I/O 方式,可以直接通过 native 方法分配一块直接内存,并且创建一个 Java 层 DirectByteBuffer 对象供应用层访问。
3. 内存溢出
3.1 程序计数器
在《Java虚拟机规范》中,程序计数器是 JVM 中唯一不会发生 OOM 的区域。
3.2 栈溢出
虚拟机栈和本地方法栈类似,都可能抛出的两种异常:
- StackOverflowError 异常: 线程的栈帧深度大于虚拟机允许的最大深度;
- OutOfMemoryError 异常: 无法申请到足够内存时;
3.3 堆溢出
申请内存空间超出最大堆内存空间时发生堆溢出。应检查是否存在某些对象生命周期过长、持有状态时间过长、存储结构设计不合理等情况,尽量减少冗余 / 不必要的内存消耗。
3.4 方法区溢出
有两种情况会导致方法区内存溢出:
- 1、运行时常量池溢出
- 2、加载的类信息溢出
3.5 直接内存溢出
与堆一样,申请的直接内存超过直接内存容量时,也会发生内存溢出。
ByteBuffer.allocateDirect(128*1024*1024)java.lang.OutofMemoryError : Direct buffer memory4. 总结
-
1、程序计数器是线程私有,描述的是当前线程下一条需要执行的字节码指令行号;
-
2、虚拟机栈描述的是 Java 方法执行的内存模型;
-
3、本地方法栈与虚拟机栈类似,区别在于虚拟机栈执行 Java 方法,而本地方法栈执行 native 方法;
-
4、堆是虚拟机上最大的一块内存,绝大多数对象都是存储在堆上的,垃圾回收机制操作的主要区域也是堆;
-
5、方法区主要存放虚拟机加载的类相关数据。
二、垃圾回收机制
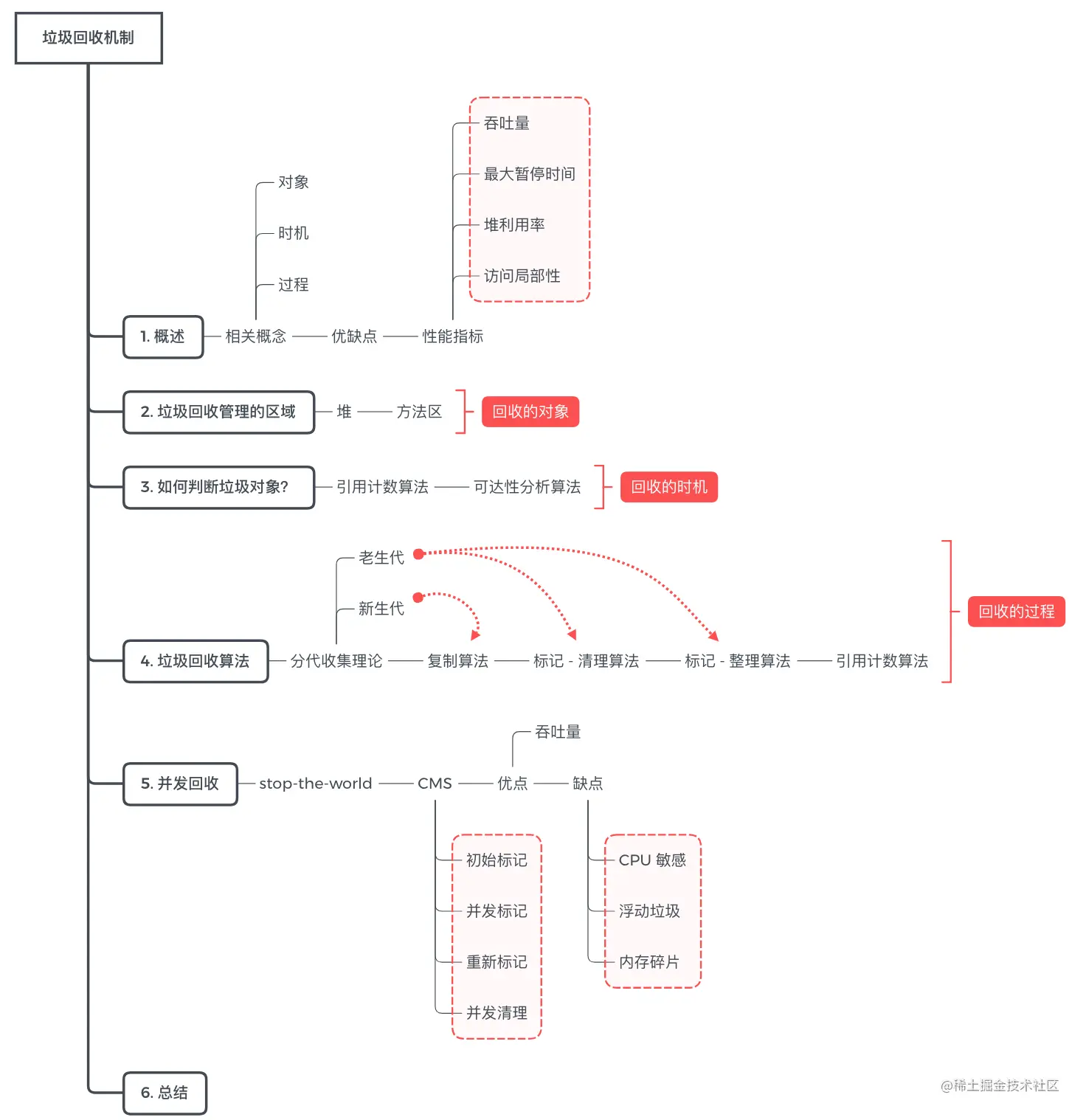
前置知识
这篇文章的内容会涉及以下前置 / 相关知识,贴心的我都帮你准备好了,请享用~
-
Java 内存分配模型: Java 虚拟机 | 内存分配模型
-
虚拟机中的对象: Java 虚拟机 | 拿放大镜看对象
1. 垃圾回收概述
垃圾回收机制(Garbage Collection,GC) 是一种自动的内存管理机制,即:当内存中的对象不再需要时,就自动释放以让出存储空间。
垃圾回收机制是 Java 虚拟机的重要特性之一,同时也是面试重要考点之一。在实践中,由于 GC 会占用程序运行资源,欲进行更有深度的内存性能优化也需要对垃圾回收机制有一定理解。
在讨论垃圾回收机制的时候,需要讨论的以下三个问题,你可以带着这三个问题阅读后面的内容,思路会更清晰。
- 回收的对象: 哪些对象 / 区域需要回收?
- 回收的时机: 什么时候触发 GC?
- 回收的过程: 如何回收?
1.1 GC 相关概念
这一节,我们先罗列一些 GC 相关知识中比较重要的概念:
| 概念 | 描述 |
|---|---|
| collector | 表示程序中负责垃圾回收的模块 |
| mutator | 表示程序中除了 collector 以外的模块 |
| 增量式回收(Incremental Collection) | 每次 GC 只针对堆的一部分,而不是整个堆,大幅减少了停顿时间 |
| 分代回收(Generational GC) | 增量式回收的实现方式之一,将堆分为新生代、老生代和永生代等部分 |
| 并行回收(Parallel Collection) | collector 中有多个垃圾回收线程 |
| 并发回收(Concurrent Collection) | 指垃圾回收工作的某个阶段,collector 线程和 mutator 可以同时执行。 这样避免了 collector 线程工作时需要暂停 mutator 线程(stop-the-world) |
1.2 垃圾回收的优缺点
-
优点: 不再需要为每个 new 操作编写对应的 delete / free 操作,程序不容易出现内存泄漏或内存溢出问题;
-
风险: 垃圾回收处理程序本身也占用系统资源(CPU 资源 / 内存),增大程序暂停时间。
1.3 GC 算法性能指标
在介绍垃圾回收算法之前,我们先来定义评价垃圾回收方法的性能指标:
| 指标 | 定义 | 描述 |
|---|---|---|
| 吞吐量(throughput) | 指单位时间内的处理能力 | 吞吐量=运行用户代码时间垃圾回收频率∗单次垃圾回收时间吞吐量 = \frac{运行用户代码时间} {垃圾回收频率 * 单次垃圾回收时间}吞吐量=垃圾回收频率∗单次垃圾回收时间运行用户代码时间 |
| 最大暂停时间(pause time) | 指因执行 GC 而暂停执行程序的最长时间 | / |
| 堆利用率(space overhead) | 指有效使用的堆空间占整个堆的比例 | 影响因素:对象头大小 + 回收算法 |
| 访问局部性 | 指回收方法是否倾向于访问局部内存 | 访问局部内存更容易命中 CPU 缓存行 |
提示: 若不理解 “访问局部性” 的概念,可联想快速排序和堆排序的性能对比,前者的访问局部性更优。
2. 垃圾回收管理的区域(回收的对象)
根据《Java虚拟机规范》的规定,Java 虚拟机所管理的内存将会包括以下区域:
| 运行时数据区域 | 线程独占 | 描述 |
|---|---|---|
| 程序计数寄存器 | 私有 | 存储下一条字节码指令的内存地址 |
| Java 虚拟机栈 | 私有 | 存储线程栈帧(Stack Frame ) 栈帧包含:局部变量表、操作数栈、动态连接、返回地址等信息 |
| 本地方法栈 | 私有 | 存储本地方法栈帧 |
| Java 堆 | 共享 | 大多数对象的存储区域 |
| 方法区 | 共享 | 存储类型信息、常量、类静态变量、即使编译器编译后的代码缓存等 |
并不是 Java 虚拟机管理的所有区域都需要垃圾回收,线程独占的区域会随着线程结束而销毁,不需要垃圾回收。因此垃圾回收机制需要管理的区域是:
-
堆: 垃圾对象;
-
方法区: 废弃的常量和不再使用的类型。
3. 如何判定垃圾对象?(回收的时机)
判断对象是否为垃圾对象的方法可以分为两种:引用计数 & 可达性分析。以判断方法为划分,后文所讲的垃圾回收算法也可以划分为 引用计数式 & 追踪式 两大类。
3.1 引用计数算法(Reference Counting)
3.1.1 判定方法
在分配对象时,会额外为对象分配一段空间,用于记录指向该对象的引用个数。如果有一个新的引用指向该对象,则计数器加 1;当一个引用不再指向该对象,则计数器减 1 。当计数器的值为 0 时,则该对象为垃圾对象。
3.1.2 优点
- 1、及时性:当对象变成垃圾后,程序可以立刻感知,马上回收;而在可达性分析算法中,直到执行 GC 才能感知;
- 2、最大暂停时间短:GC 可与应用交替运行。
3.1.3 缺点
- 1、计数器值更新频繁:大多数情况下,对象的引用状态会频繁更新,更新计数器值的任务会变得繁重;
- 2、堆利用率降低:计数器至少占用 32 位空间(取决于机器位数),导致堆的利用率降低;
- 3、实现复杂;
- 4、(致命缺陷)无法回收循环引用对象。
易错: 引用计数法是算法简单,实现较难。
3.2 可达性分析算法(Reachability Analysis)
3.2.1 判定方法
从 GC 根节点(GC Root)为起点,根据引用关系形成引用链。当一个对象存在到 GC Root 的引用链,则为存活对象,否则为垃圾对象。在 Java 中,GC Root 主要包括:
- 1、Java 虚拟机栈中引用的对象(即栈帧中的本地变量表);
- 2、本地方法栈中引用的对象;
- 3、方法区中类静态变量引用的对象;
- 4、方法区常量池中引用的对象;
- 5、同步锁(synchronized 关键字)持有的对象;
3.2.2 优点
- 1、可回收循环引用对象;
- 2、实现简单。
3.2.3 缺点
- 1、最大停顿时间长:在 GC 期间,整个应用停顿(stop-the-world,STW);
- 2、回收不及时:直到执行 GC 才能感知垃圾对象;
3.3 小结
| 判定方法 | 优点 | 缺点 |
|---|---|---|
| 引用计数 | 1、及时性 2、最大暂停时间短 | 1、计数器值更新频繁 2、堆利用率降低 3、实现复杂 4、无法回收循环引用对象 |
| 可达性分析 | 1、可回收循环引用对象 2、实现简单 | 1、最大停顿时间长 2、回收不及时 |
由于引用计数式 GC 存在 「无法回收循环引用对象」 的致命缺陷,工业实现上还是追踪式 GC 占据了主流,后面我主要介绍的也是追踪式 GC。
4. 垃圾回收算法(回收的过程)
从原理上,垃圾回收算法可以分为以下四类基础算法,其它的垃圾回收算法其实是对基础算法的改进或组合。
| 时间 | 早期提出者 | 算法 | 类别 |
|---|---|---|---|
| 1960年 | Lisp 之父 John McCarthy | 标记 - 清理算法 | 追踪式 |
| 1960年 | George E. Collins | 引用计数算法 | 引用计数式 |
| 1969年 | Fenichel | 复制算法 | 追踪式 |
| 1974年 | Edward Lueders | 标记 - 整理算法 | 追踪式 |
在实践中,当代绝大多数垃圾收集器都采用了 “分代收集模型” ,该模型的经验前提是:
- 1、绝大多数对象都是朝生夕死,无法熬过第一次垃圾回收;
- 2、熬过了多次垃圾回收的对象,往往越难被回收。
在上述事实经验的基础上,虚拟机往往使用了 动静分离 的设计思想:将新对象和难以回收的老对象存储在不同的区域,新对象存放在新生代,难回收的对象存在老年代。并且针对不同区域的特性采用不同的垃圾回收算法。

—— 图片引用自网络
-
1、新生代: 新生代中的对象存活率低,只要付出少量的复制成本就能完成回收过程,因此选用复制算法;
-
2、老生代: 老生代中的对象存活率高,并且没有额外空间进行分配担保,因此选用 “标记 - 清理” 或 “标记 - 整理” 算法。
4.1 标记 - 清理算法(Mark-Sweep)
4.1.1 算法回收过程
标记 - 清理算法的回收过程主要分为两个阶段:
-
标记(Mark)阶段: 遍历整个堆,标记出垃圾对象(也可以标记存活对象);
-
清理(Sweep)阶段: 遍历整个堆,将垃圾对象分块链接空闲列表。

4.1.2 优点
实现简单;
4.1.3 缺点
- 1、执行效率不稳定:Java 堆中对象越多,标记和清理的过程可能会越耗时;
- 2、内存碎片化(fragmentation):回收过程会逐渐产生很多不连续的小内存,当小内存不足以分配对象内存时,又会触发一次垃圾回收动作(GC for Alloc)。
4.2 复制算法(Copying)
4.2.1 算法回收过程
复制算法的回收过程要点如下:
- 1、将堆分为大小相同的两个空间:from 区和 to 区;
- 2、对象的内存分配只使用 from 区,当 from 区占满时,将存活对象全部复制到 to 区;
- 3、复制完成后互换 from 区和 to 区的指针。
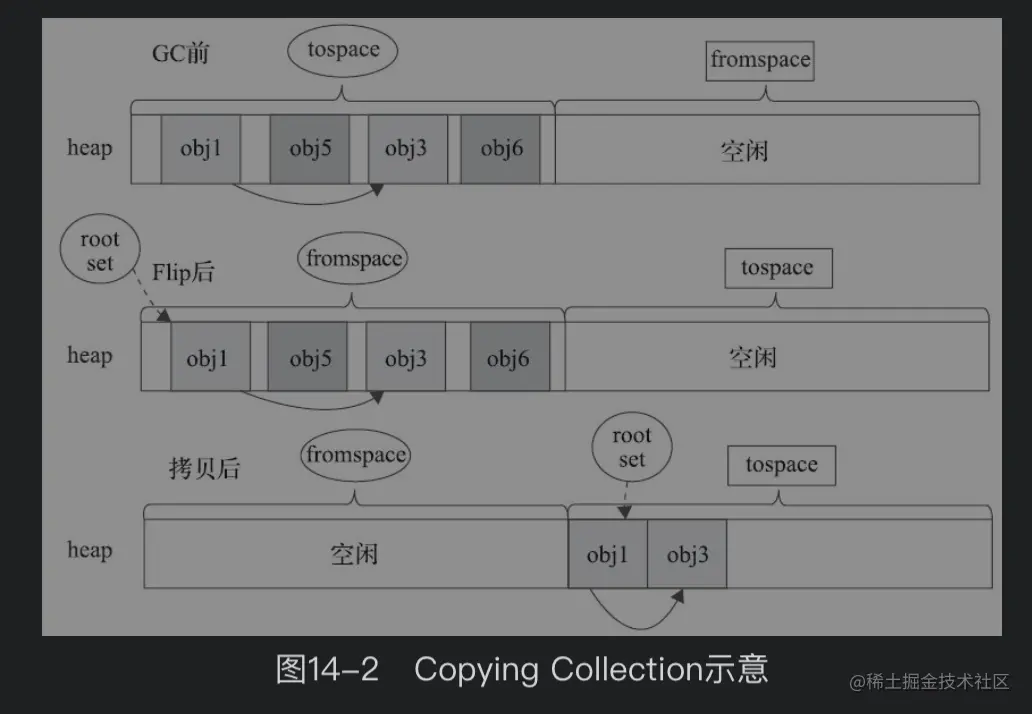
—— 图片引用自 weread.qq.com/web/reader/… 邓凡平 著
4.2.2 优点
- 1、快速分配对象:空闲分块是一个连续内存空间,不需要向标记-清理算法那样遍历空闲列表;
- 2、避免内存碎片化:存活对象和新分配对象都被压缩到 tospace 的一端,避免出现很多不连续的小内存。
4.2.3 缺点
- 1、堆利用率低:把堆做二等分只能利用其中的一半,堆利用率最高仅为 50 %。
4.2.4 改进
- 1、将新生代分为:一块 Eden 区和两块 Survivor 区,对应的比例为 8:1:1;
- 2、对象只在 Eden 区分配,当 Eden 区占满后,将 Eden 区和 from Survivor 区的存活对象全部赋值到 to Survivor 区;
- 3、复制完成后互换 from Survivor 区和 to Survivor 区的指针。
改进后堆利用率提升到最高 90%。
4.3 标记 - 整理算法(Mark-Compact)
4.3.1 算法回收过程
标记 - 清除算法与标记 - 整理算法的本质差异在于是否移动对象。标记 - 整理算法的回收过程主要分为两个阶段:
-
标记(Mark)阶段: 遍历整个堆,标记出垃圾对象(这个步骤与标记 - 清理算法相同);
-
整理(Compact)阶段: 将所有存活对象移动(压缩)到堆的一端,然后直接清理掉边界以外的内存。
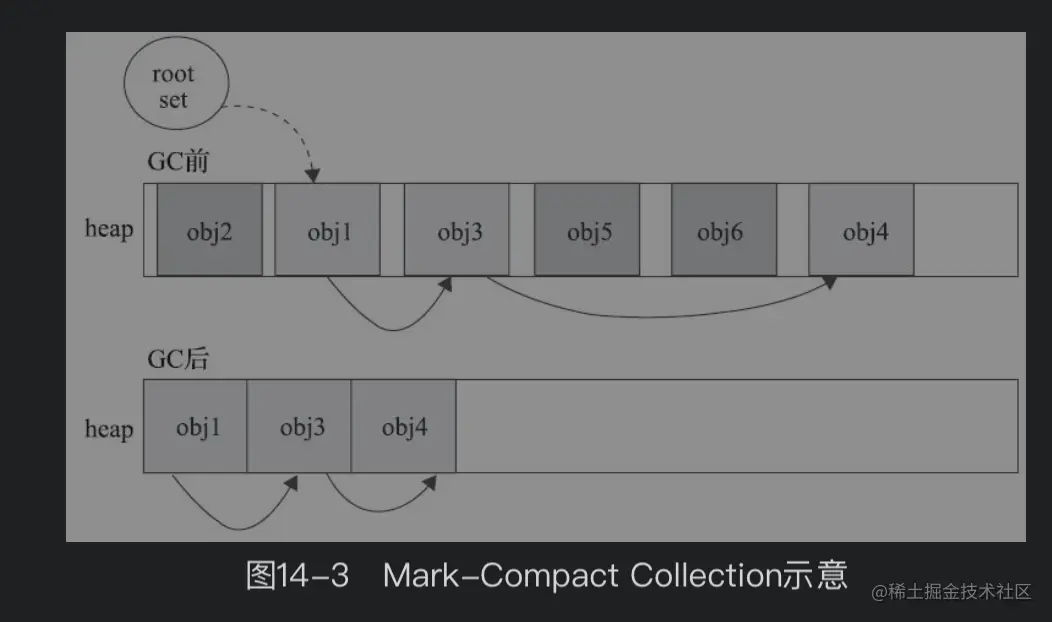
—— 图片引用自 weread.qq.com/web/reader/… 邓凡平 著
4.3.2 优点
- 1、避免内存碎片化,堆利用率高,吞吐量更高;
- 2、快速分配对象:空闲分块是一个连续内存空间,不需要向标记-清理算法那样遍历空闲列表;
4.3.3 缺点
- 1、移动对象比清理对象更耗时,导致 GC 停顿时间(Stop-the-world)时间更长。
5. 并发回收
5.1 stop-the-world 现象
在标准的垃圾回收算法中,在垃圾回收线程(collector)进行标记 - 清理 / 整理 / 复制的过程中需要暂停所有的用户线程(mutator),这是为了保证能够彻底清理所有垃圾对象。
但是这种做法却会导致虚拟机的吞吐量降低(吞吐量=运行用户代码时间垃圾回收频率∗单次垃圾回收时间吞吐量 = \frac{运行用户代码时间} {垃圾回收频率 * 单次垃圾回收时间}吞吐量=垃圾回收频率∗单次垃圾回收时间运行用户代码时间)。
5.2 CMS 垃圾收集器
在追求响应速度的系统上,希望垃圾收集器暂停时间尽可能小,为此发展出了允许回收线程与用户线程并发运行的垃圾收集器 —— CMS(Concurrent Mark Sweep,并发标记清除)。
CMS 垃圾收集器的主要工作过程分为 4 个步骤:
-
1、初始标记(短暂 stop-the-world): 仅仅标记被 GC Root 直接引用的对象,由于 GC Root 相对较少,这个过程速度很块;
-
2、并发标记(耗时): 继续遍历 GC Root 引用链上的对象,这个过程比较耗时,所以采用并发处理;
-
3、重新标记(短暂 stop-the-world): 为了修正并发标记期间用户线程导致的引用关系变化,需要暂停用户线程重新标记;
-
4、并发清除(耗时) 由于清除对象的过程比较耗时,所以采用并发处理。
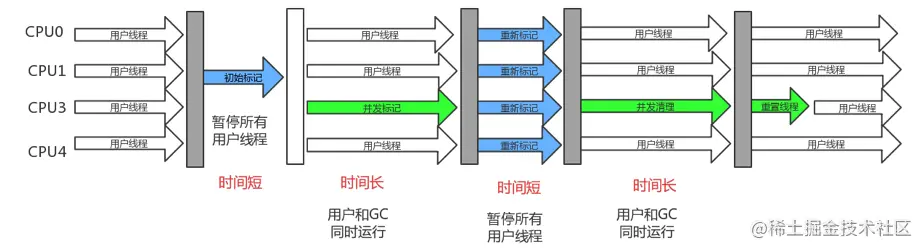
—— 图片引用自网络
5.3 CMS 的优点
- 1、缩短了系统 stop-the-world 时间,提高了吞吐量;
5.4 CMS 的缺点
- 1、CPU 敏感: 采用了并发策略,系统整体上会占用更多 CPU 资源;
- 2、浮动垃圾: 由于并发清理的过程中用户线程还在运行,CMS 无法回收这个阶段中用户线程产生的垃圾,这一部分垃圾称为 “浮动垃圾”。由于浮动垃圾的存在,垃圾收集器需要预留出一部分空间来允许浮动垃圾的产生,如果预留的空间还不足以存放浮动垃圾,就会出现 Concurrent Mode Failure,此时需要临时启动非并发清理方案来代替 CMS;
- 3、内存碎片: 采用标记 - 清理算法,会产生内存碎片。
6. 总结
-
1、垃圾回收算法的性能指标主要有:吞吐量、最大暂停时间、堆利用率、访问局部性。在理解垃圾回收机制的过程中,可以带着 “回收的对象” & “回收的时机” & “回收的过程” 三个问题来理解;
-
2、垃圾回收机制管理的区域有堆和方法区;
-
3、判断垃圾对象的算法分为引用计数算法和可达性分析算法,两者各有优缺点;
-
4、垃圾回收算法可以分为四类基本算法:引用计数算法、标记-清理算法、标记-整理算法和复制算法。其它的垃圾回收算法都是对基础算法的改进或组合。比如主流的虚拟机垃圾回收算法采用分代回收模型:即在新生代选用复制算法(对象存活率低),而老生代选用 “标记 - 清理” 或 “标记 - 整理” 算法(对象存活率高,并且没有额外空间进行分配担保);
-
5、在标准的垃圾回收算法中,垃圾回收过程会 stop-the-world。使用并发收集可以降低系统的暂停时间,提供吞吐量。
三、对象的创建过程
前置知识
这篇文章的内容会涉及以下前置 / 相关知识,贴心的我都帮你准备好了,请享用~
-
Java 内存分配模型: Java 虚拟机 | 内存分配模型
-
垃圾回收: Java 虚拟机 | 垃圾回收机制
-
类加载: Java 虚拟机 | 类加载机制
1. 对象的创建过程
在 Java 中创建对象的一般方式是使用 new 关键字,编译后会生成以 new 字节码指令开始的多条指令,例如:
javascript
复制代码
源代码: String str = new String(); 字节码: 0 new #26 <java/lang/String> 3 dup 4 invokespecial #27 <java/lang/String.<init>> 7 astore_0

—— 图片引用自网络
提示: 这里讨论的对象是指一般的对象,即使用 new 创建的对象。
1.1 检查加载 & 类加载
根据常量池索引#26找到类的符号引用<java/lang/String>,并且检查类是否被类加载器加载过,如果没有需要先执行类加载过程(加载 & 解析 & 初始化)。
1.2 分配内存
1.2.1 分配方式
Java 对象需要一块连续的堆内存空间,分配方式有 指针碰撞 & 空闲列表。指针碰撞法要求 Java 堆是绝对规整的,而空闲列表法不要求 Java 堆是绝对规整的。
- 指针碰撞
所有已分配内存压缩到堆的一端,剩下一端为空闲的内存,两块区域使用一个 分配指针 作为分界指示器。当需要分配对象内存时,只需要把指针向挪动与对象大小相等的距离,将该区域划分给对象。
- 空闲列表
虚拟机会维护一个列表记录哪些内存时空闲的。当需要对象内存时,需要遍历空闲列表找到一块足够大的空间划分给对象。
1.2.2 并发安全
由于 Java 堆是线程共享的,而创建对象(分配内存)的行为在虚拟机中是非常频繁的,那么就需要考虑多线程并发分配内存的问题,解决方法有:CAS 操作 & 分配缓冲:
- CAS 操作
采用自旋 CAS 操作实现更改指针操作的线程安全性;
- TLAB 分配缓冲
每个线程在 Java 堆中预先分配一小块内存,即 本地线程分配缓冲(Thread Local Allocation Buffer,TLAB),让每个线程使用专属的分配指针来分配空间,其他线程无法在这个区域中分配,这样就较少了线程同步开销。
通过虚拟机参数-XX+UseTLAB来控制是否启用 TLAB 功能。
提示: TLAB 中的中的对象空间依然是所有线程共享的,只是其他线程无法在这个区域分配对象。
1.3 初始化零值
将实例数据的值初始化为零值(例如 int 为 0 ,boolean 为 false,引用类型为 null)。
1.4 设置对象头
设置对象头信息,包括 Mark Work & 类型指针 & 数组长度。
1.5 执行 构造函数
执行 构造函数, 由编译器生成,包括成员变量初始值、实例代码块和对象构造函数。
2. 对象的内存布局
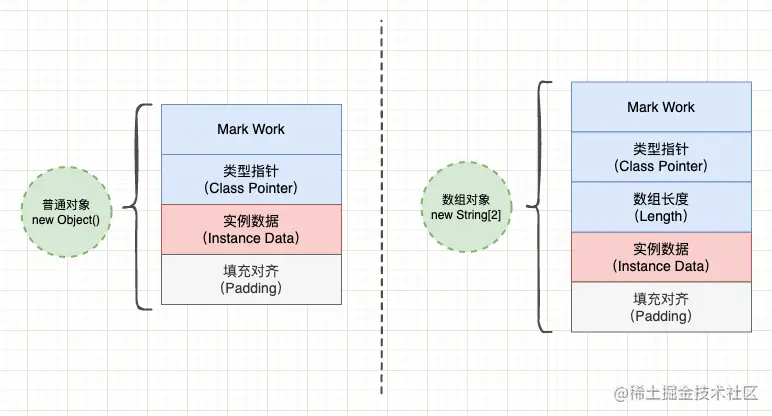
对象的内存布局主要包含 3 个区域:对象头 & 实例数据 & 对齐填充。其中对象头主要包含 Mark Work 标志位,如果采用「直接指针」的对象访问,那么对象头里还包含类型指针。如果是数组对象,那么对象头还包含数组的长度。实例数据区存储了「本类声明的实例字段」和「从父类继承的实例字段」(类字段存储在方法区)。

2.1 对象头(Header)
对象头包含 Mark Work & 类型指针 & 数组长度。
2.1.1 Mark Work
由于对象头里的信息是与对象实例数据无关的额外存储成本,Mark Word 被设计为一个有状态的数据结构,可以根据对象的状态 复用。
2.1.2 类型指针(Class Pointer)
- 定义: 指向方法区中的类型元数据,可选,取决于对象的访问定位方式;
- 长度: 在 32 位机器上占用 4 个字节,在 64 位机器上占 8 个字节。虚拟机(默认)通过 指针压缩 将长度压缩到 4 个字节,通过以下虚拟机参数控制。
-XX:+UseCompressedClassPointers -XX:+UseCompressedOops
- 注意: 并不是所有虚拟机实现都将类型指针存在对象数据上。具体取决于虚拟机使用的 对象的访问定位 方式,如果是使用 直接指针 的方式,对象的内存布局就必须放置访问类型数据的指针。
2.1.3 数组长度
- 定义: 指数组对象的长度,注意这里的长度指的是元素个数,非占用内存空间(可选,只有数组对象才有);
- 长度: 4 个字节;
- 描述: 普通 Java 对象的大小可以通过元数据信息确定,但是对于数组对象来说,无法通过元数据的信息确定数组的长度。因此,如果对象是一个
Java数组,那么对象头中会有一块记录数组长度的区域。例如:
源码:
char [] str = new char[2];
System.out.println(ClassLayout.parseInstance(str).toPrintable());
------------------------------------------------------
JOL:
[C object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 41 00 00 f8 (01000001 00000000 00000000 11111000) (-134217663)
12 4 (object header) 【数组长度:2】02 00 00 00 (00000010 00000000 00000000 00000000) (2)
16 4 char [C.<elements> N/A
20 4 (loss due to the next object alignment)
Instance size: 24 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
可以看到,对象头中有一块 4 字节的区域,值为2,表示该数组长度为 2。
2.2 实例数据(Instance Data)
实例数据是对象的有效信息,可以理解为报文段中的 payload。对象的实例数据包括:
- 本类声明的实例字段
- 从父类继承的实例字段
但不包括类级字段(存储在方法区)。
2.3 对齐填充(Padding)
HotSpot 虚拟机对象的大小必须按 8 字节对齐,如果对象占用空间不是 8 字节的倍数,则需要增加对齐填充数据。直观来看,“无效” 的填充数据使得对象占用空间加大,增大了虚拟机的内存消耗。那么为什么要这么做呢? Editting...
2.4 实验
JOL(Java Object Layout) 是 OpenJDK 提供的用于分析对象内存布局的工具,地址:JOL。主要的局限性是只支持 HotSpot / OpenJDK 虚拟机,如果在其他虚拟机上使用会报错:
java.lang.IllegalStateException: Only HotSpot/OpenJDK VMs are supported
现在,我们使用JOL分析 new Object() 在 HotSpot 虚拟机上的内存布局:
步骤一:添加依赖
implementation 'org.openjdk.jol:jol-core:0.11'
步骤二:创建对象
Object obj = new Object();
步骤三:打印对象内存布局
1. 输出虚拟机与对象内存布局相关的信息
System.out.println(VM.current().details());
2. 输出对象内存布局信息
System.out.println(ClassLayout.parseInstance(obj).toPrintable());
输出结果如下:
# Running 64-bit HotSpot VM.
# Using compressed oop with 3-bit shift.
# Using compressed klass with 3-bit shift.
# Objects are 8 bytes aligned.
# Field sizes by type: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
# Array element sizes: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
java.lang.Object object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) e5 01 00 f8 (11100101 00000001 00000000 11111000) (-134217243)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
其中关于虚拟机的信息:
Running 64-bit HotSpot VM.表示运行在64位的 HotSpot 虚拟机Using compressed oop with 3-bit shift.指针压缩Using compressed klass with 3-bit shift.指针压缩Objects are 8 bytes aligned.表示对象按 8 字节对齐Field sizes by type: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes],依次表示引用、boolean、byte、char、short、int、float、long、double类型占用的长度,见源码:
HotspotUnsafe.java
public String details() {
// ...
out.printf("# %-19s: %d, %d, %d, %d, %d, %d, %d, %d, %d [bytes]%n",
"Field sizes by type",
oopSize,
sizes.booleanSize,
sizes.byteSize,
sizes.charSize,
sizes.shortSize,
sizes.intSize,
sizes.floatSize,
sizes.longSize,
sizes.doubleSize
);
}
Array element sizes: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes],依次表示数组元素长度
3. 对象的访问定位
我们都知道 Java 的类型可以分为基础数据类型与引用类型(Reference)。对于引用类型变量,在虚拟机栈上存储的只是 Reference,而对象真正的实例数据是存储在堆上。通过 Reference 访问对象实例数据的方式分为分为 句柄访问 & 直接指针访问:
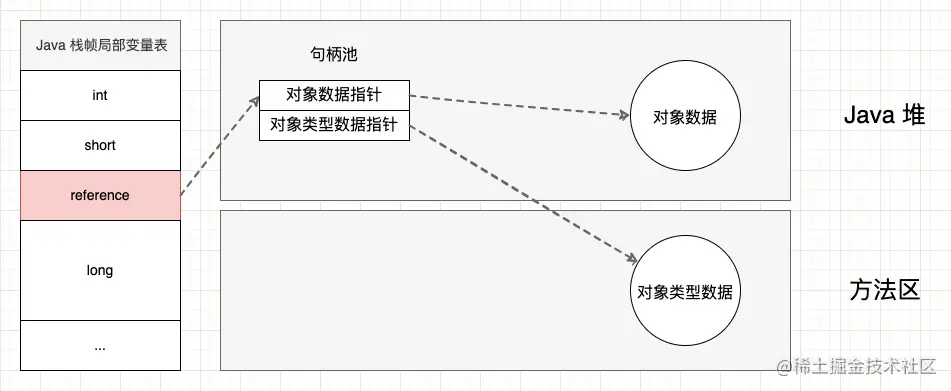
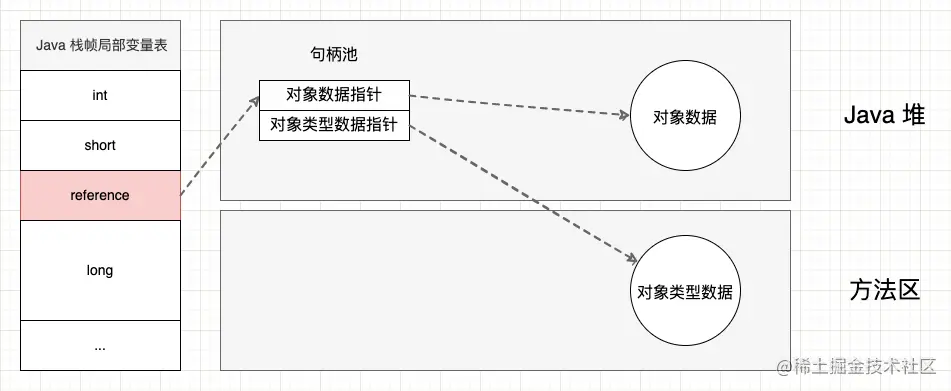
3.1 句柄访问
在 Java 堆中单独划分一块区域作为句柄池,Reference 中存储是对象的句柄。句柄中存储的是对象实例数据与类型数据的地址。
句柄访问的优点是句柄中对象实例数据和类型数据的地址是稳定的,当对象在垃圾收集是被移动时,只需要修改实例数据的指针,而 Reference 本身不需要修改。
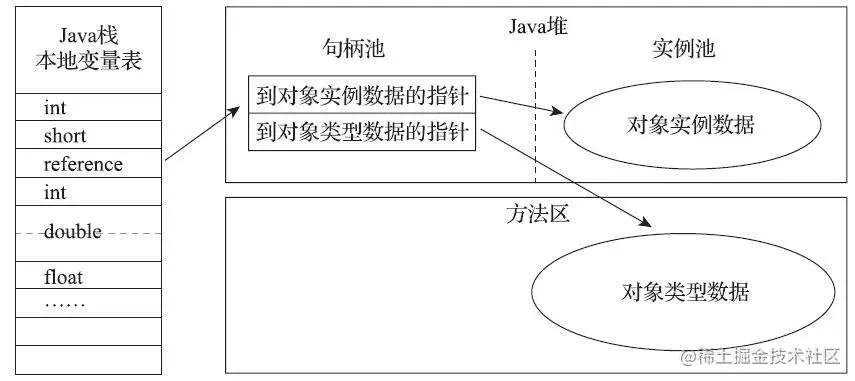
引用自《深入理解Java虚拟机(第3版本)》—— 周志明 著
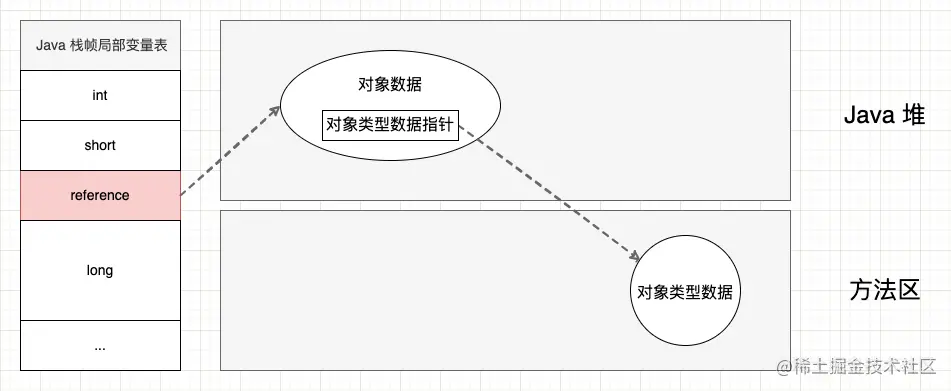
3.2 直接指针访问
Reference 中存储的是指向对象的地址,对象内存中有一块是实例数据,另外有一个指针指向类型数据,这个指针就是 第 2.1.2 节 中的类型指针(Class Pointer)
直接指针访问的优点是速度更快,因为节省了一次指针的访问。由于在 Java 虚拟机中对象访问的频率非常高,所以直接指针访问的优势更明显。
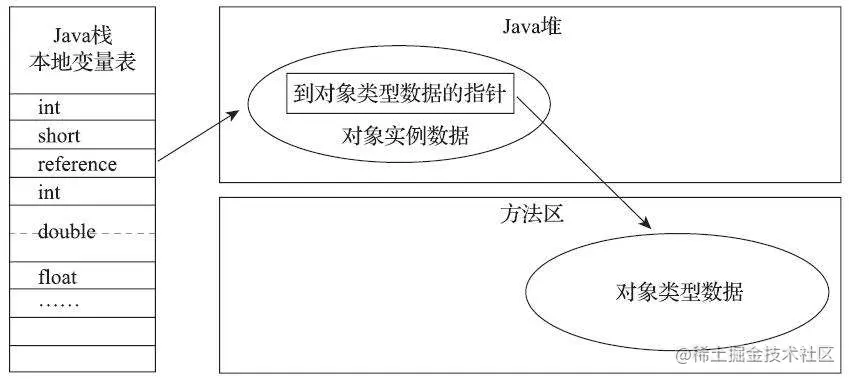
引用自《深入理解Java虚拟机(第3版本)》—— 周志明 著
4. 对象的存活判断
判断对象是否为垃圾对象的方法可以分为两种:引用计数 & 可达性分析。
4.1 引用计数算法(Reference Counting)
4.1.1 判定方法
引用计数法指创建对象时额外分配一个引用计数器,用于记录指向该对象的引用个数。如果有一个新的引用指向该对象,则计数器加 1;当一个引用不再指向该对象,则计数器减 1 。当计数器的值为 0 时,则该对象为垃圾对象。
4.1.2 优点
1、及时性:当对象变成垃圾后,程序可以立刻感知,马上回收;而在可达性分析算法中,直到执行 GC 才能感知;
2、最大暂停时间短:GC 可与应用交替运行。
4.1.3 缺点
1、计数器值更新频繁:大多数情况下,对象的引用状态会频繁更新,更新计数器值的任务会变得繁重;
2、堆利用率降低:计数器至少占用 32 位空间(取决于机器位数),导致堆的利用率降低;
3、实现复杂;
4、(致命缺陷)无法回收循环引用对象。
易错: 引用计数法是算法简单,实现较难。
4.2 可达性分析算法(Reachability Analysis)
4.2.1 判定方法
可达性分析法指根据引用关系形成一条引用链,当一个对象存在到 GC Root 的引用链时,则为存活对象,否则判定为垃圾对象。在 Java 中,GC Root 主要包括:
1、Java 虚拟机栈帧中的本地变量表
2、本地方法栈中引用的对象
3、方法区类静态变量引用的对象
4、方法区常量池中引用的对象
5、同步锁(synchronized 关键字)持有的对象
4.2.2 优点
1、可回收循环引用对象; 2、实现简单。
4.2.3 缺点
1、最大停顿时间长:在 GC 期间,整个应用停顿(stop-the-world,STW);
2、回收不及时:只有执行 GC 才能感知垃圾对象;
4.3 小结
| 判定方法 | 优点 | 缺点 |
|---|---|---|
| 引用计数 | 1、及时性 2、最大暂停时间短 | 1、计数器值更新频繁 2、堆利用率降低 3、实现复杂 4、无法回收循环引用对象 |
| 可达性分析 | 1、可回收循环引用对象 2、实现简单 | 1、最大停顿时间长 2、回收不及时 |
由于引用计数式 GC 存在 「无法回收循环引用对象」 的致命缺陷,工业实现上还是追踪式 GC 占据了主流。
更多内容:垃圾回收: Java 虚拟机 | 垃圾回收机制
5. 对象的引用类型
不同引用类型的作用不尽相同,这一点很多文章没有明确指出。软引用 & 弱引用提供了更加灵活地控制对象生存期的能力,而虚引用提供了感知对象垃圾回收的能力。 除了虚引用之外,Object#finalize() 也提供了感知对象被垃圾回收的能力。
| 引用类型 | Class | 作用 | 对象 GC 时机(不考虑 GC 策略) |
|---|---|---|---|
| 强引用 | 无 | / | GC Root 可达就不会回收 |
| 软引用 | SoftReference | 灵活控制生存期 | 空闲内存不足以分配新对象时 |
| 弱引用 | WeakReference | 灵活控制生存期 | 每次GC |
| 虚引用 | PhantomReference | 感知对象垃圾回收 | 每次GC |
提示: 对象是否被 GC,不仅仅取决于引用类型,还取决于当次 GC 采用的策略。
更多内容:引用: Java | 引用类型 & Finalizer 机制
6. 对象的分配策略
6.1 对象的分配区域
几乎所有对象都分配在 Java 堆,除此之外还可以分配在:
- 方法区:Class 对象、字符串常量池中的 String
- 栈:满足逃逸分析的对象直接在栈上分配
6.2 逃逸分析
逃逸分析(Escape Analysis)是分析对象的引用是否逃逸到当前栈帧或者其它线程,如果一个对象不会逃逸,则可以直接在栈上分配,而不是分配在 Java 堆。当对象在栈上分配时,当前方法结束之后对象的生命周期也结束了,不需要参与垃圾回收,可以提高虚拟机的执行效率。
通过JVM参数可指定是否开启逃逸分析:-XX:+DoEscapeAnalysis
6.3 对象的分配原则
- 1、对象优先在 Eden 区分配
大多数情况下,新生对象在 Eden 区分配,当 Eden 区没有足够空间时,虚拟机发起一次 Minor GC。
- 2、大对象直接在 Tenured 区分配
大对象占用内容较多,如果分配在 Eden 区的话,容易提前发生垃圾回收,同时 GC 的时候也会大量复制内存,所以大对象直接在 Tenured 区分配。
- 3、对象年龄动态提升
在对象头中有一个字段标记对象的年龄,如果对象经过一次 Minor GC 之后依然存活,并且 Survivor 区能够容纳的话,那么对象会被复制到 Survivor 区,并且对象的年龄加 1。当对象的年龄增加到一定程度时,就是晋升到 Tenured 区。
四、对象的内存分为哪几个部分?
学习路线图:
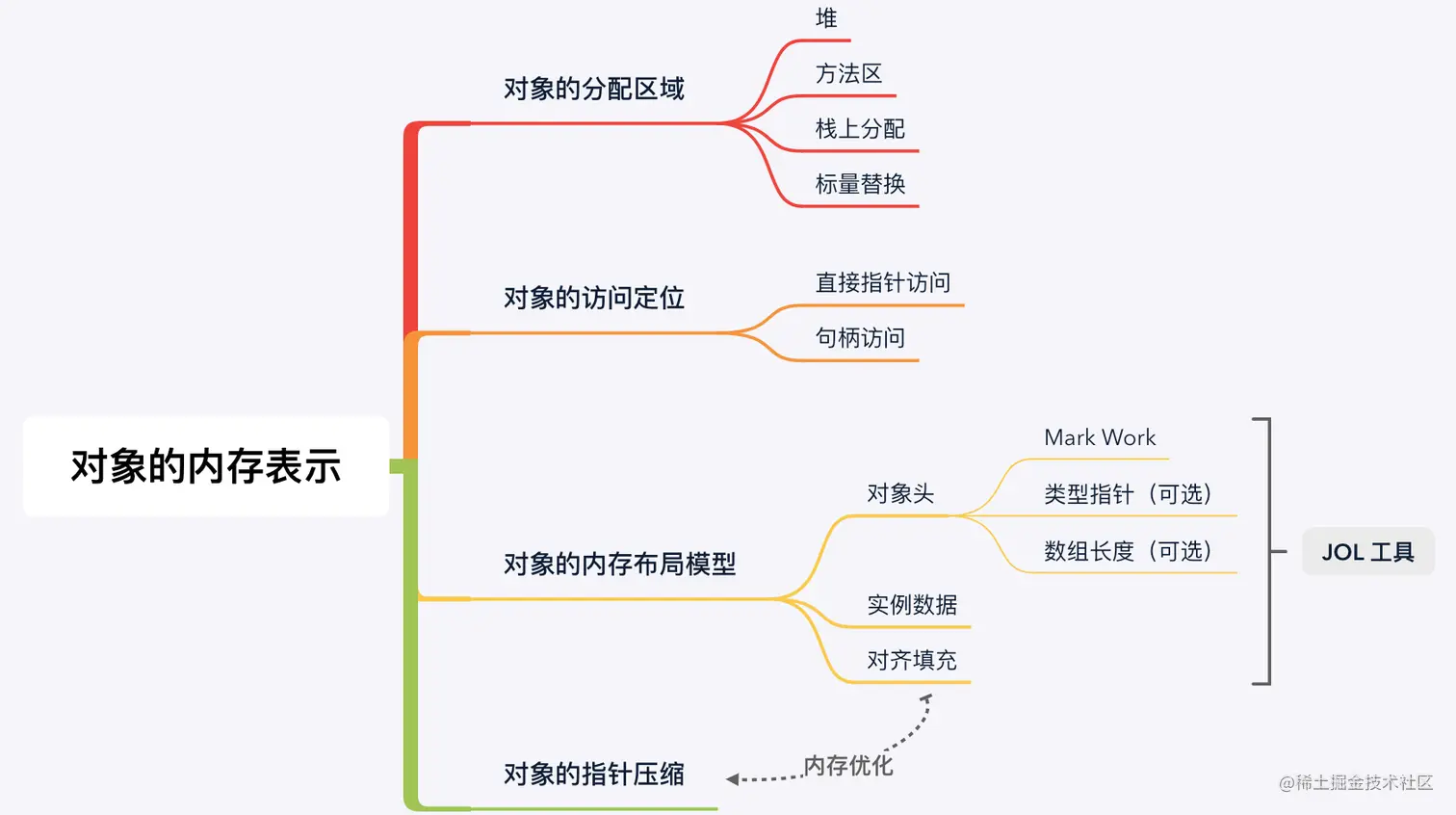
1. 对象在哪里分配?
在 Java 虚拟机中,Java 堆和方法区是分配对象的主要区域,但是也存在一些特殊情况,例如 TLAB、栈上分配、标量替换等。 这些特殊情况的存在是虚拟机为了进一步优化对象分配和回收的效率而采用的特殊策略,可以作为知识储备。
- 1、Java 堆(Heap): Java 堆是绝大多数对象的分配区域,现代虚拟机会采用分代收集策略,因此 Java 堆又分为新生代、老生代和永生代。如果新生代使用复制算法,又可以分为 Eden 区、From Survivor 区和 To Survivor 区。除了这些每个线程都可以分配对象的区域,如果虚拟机开启了 TLAB 策略,那么虚拟机会在堆中为每个线程预先分配一小块内存,称为线程本地分配缓冲(Thread Local Allocation Buffer,TLAB)。在 TLAB 上分配对象不需要同步锁定,可以加快对象分配速度(TLAB 中的对象依然是线程共享读取的,只是不允许其他线程在该区域分配对象);
- 2、方法区(Method Area): 方法区也是线程共享的区域,堆中存放的是生命周期较短的对象,而方法区中存放的是生命周期较长的对象,通常是一些支撑虚拟机执行的必要对象,将两种对象分开存储体现的是动静分离的思想,有利于内存管理。存储在方法区中的数据包括已加载的 Class 对象、静态字段(本质上是 Class 对象中的实例字段,下文会解释)、常量池(例如 String.intern())和即时编译代码等;
- 3、栈上分配(Stack Allocation): 如果 Java 虚拟机通过逃逸分析后判断一个对象的生命周期不会逃逸到方法外,那么可以选择直接在栈上分配对象,而不是在堆上分配。栈上分配的对象会随着栈帧出栈而销毁,不需要经过垃圾收集,能够缓解垃圾收集器的压力。
- 4、标量替换(Scalar Replacement): 在栈上分配策略的基础上,虚拟机还可以选择将对象分解为多个局部变量再进行栈上分配,连对象都不创建。
2. 对象的访问定位
Java 类型分为基础数据类型(int 等)和引用类型(Reference),虽然两者都是数值,但却有本质的区别:基础数据类型本身就代表数据,而引用本身只是一个地址,并不代表对象数据。那么,虚拟机是如何通过引用定位到实际的对象数据呢?具体访问定位方式取决于虚拟机实现,目前有 2 种主流方式:
- 1、直接指针访问: 引用内部持有一个指向对象数据的直接指针,通过该指针就可以直接访问到对象数据。采用这种方式的话,就需要在对象数据中额外使用一个指针来指向对象类型数据;
- 2、句柄访问: 引用内部持有一个句柄,而句柄内部持有指向对象数据和类型数据的指针(句柄位于 Java 堆中句柄池)。使用这种方式的话,就不需要在对象数据中记录对象类型数据的指针。
使用句柄的优点是当对象在垃圾收集过程中移动存储区域时,虚拟机只需要改变句柄中的指针,而引用保持稳定。而使用直接指针的优点是只需要一次指针跳转就可以访问对象数据,访问速度相对更快。以 Sun HotSpot 虚拟机而言,采用的是直接指针方式,而 Android ART 虚拟机采用的是句柄方式。
// Android ART 虚拟机源码体现:
// Handles are memory locations that contain GC roots. As the mirror::Object*s within a handle are
// GC visible then the GC may move the references within them, something that couldn't be done with
// a wrap pointer. Handles are generally allocated within HandleScopes. Handle is a super-class
// of MutableHandle and doesn't support assignment operations.
template<class T>
class Handle : public ValueObject {
...
}
直接指针访问:
句柄访问:
关于 Java 引用类型的深入分析,见 吊打面试官:说一下 Java 的四种引用类型
3. 使用 JOL 分析对象内存布局
这一节我们演示使用 JOL(Java Object Layout) 来分析 Java 对象的内存布局。JOL 是 OpenJDK 提供的对象内存布局分析工具,不过它只支持 HotSpot / OpenJDK 虚拟机,在其他虚拟机上使用会报错:
错误日志
java.lang.IllegalStateException: Only HotSpot/OpenJDK VMs are supported
3.1 使用步骤
现在,我们使用 JOL 分析 new Object() 在 HotSpot 虚拟机上的内存布局,模板程序如下:
示例程序
// 步骤一:添加依赖
implementation 'org.openjdk.jol:jol-core:0.11'
// 步骤二:创建对象
Object obj = new Object();
// 步骤三:打印对象内存布局
// 1. 输出虚拟机与对象内存布局相关的信息
System.out.println(VM.current().details());
// 2. 输出对象内存布局信息
System.out.println(ClassLayout.parseInstance(obj).toPrintable());
输出日志
# Running 64-bit HotSpot VM.
# Using compressed oop with 3-bit shift.
# Using compressed klass with 3-bit shift.
# Objects are 8 bytes aligned.
# Field sizes by type: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
# Array element sizes: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
java.lang.Object object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) e5 01 00 f8 (11100101 00000001 00000000 11111000) (-134217243)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
其中关于虚拟机的信息:
Running 64-bit HotSpot VM.表示运行在 64 位的 HotSpot 虚拟机;Using compressed oop with 3-bit shift.指针压缩(后文解释);Using compressed klass with 3-bit shift.指针压缩(后文解释);Objects are 8 bytes aligned.表示对象按 8 字节对齐(后文解释);Field sizes by type: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]:依次表示引用、boolean、byte、char、short、int、float、long、double 类型占用的长度;Array element sizes: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]:依次表示数组元素长度。
我将 Java 对象的内存布局总结为以下基本模型:
3.2 对象内存布局的基本模型
在 Java 虚拟机中,对象的内存布局主要由 3 部分组成:
- 1、对象头(Header): 包括对象的运行时状态信息 Mark Work 和类型指针(直接指针访问方式),数据对象还会记录数组元素个数;
- 2、实例数据(Instance Data): 普通对象的实例数据包括当前类声明的实例字段以及父类声明的实例字段,而 Class 对象的实例数据包括当前类声明的静态字段和方法表等;
- 3、对齐填充(Padding): HotSpot 虚拟机对象的大小必须按 8 字节对齐,如果对象实际占用空间不足 8 字节的倍数,则会在对象末尾增加对齐填充。
关于方法表的作用,见 重载与重写。
4. 对象内存布局详解
这一节开始,我们详细解释对象内存布局的模型。
4.1 对象头(Header)
- Mark Work: Mark Work 是对象的运行时状态信息,包括哈希码、分代年龄、锁状态、偏向锁信息等。由于 Mark Work 是与对象实例数据无关的额外存储成本,因此虚拟机选择将其设计为带状态的数据结构,会根据对象当前的不同状态而定义不同的含义;
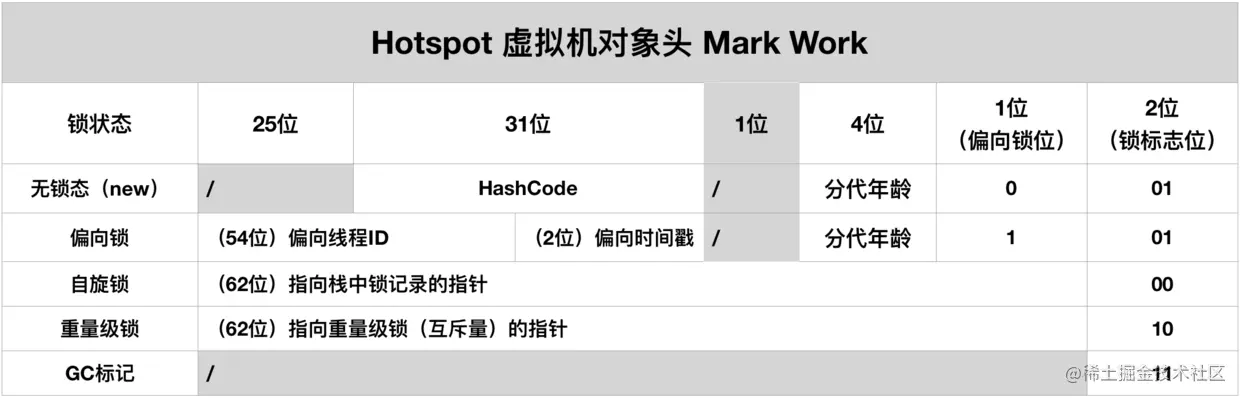
- 类型指针(Class Pointer): 指向对象类型数据的指针,只有虚拟机采用直接指针的对象访问定位方式才需要在对象上记录类型指针,而采用句柄的对象访问定位方式不需要此指针;
- 数组长度: 数组类型的元素长度是不能提前确定的,但在创建对象后又是固定的,所以数组对象的对象头中会记录数组对象中实际元素的个数。
以下演示查看数组对象的对象头中的数组长度字段:
示例程序
char [] str = new char[2];
System.out.println(ClassLayout.parseInstance(str).toPrintable());
输出日志
[C object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 41 00 00 f8 (01000001 00000000 00000000 11111000) (-134217663)
12 4 (object header) 【数组长度:2】02 00 00 00 (00000010 00000000 00000000 00000000) (2)
16 4 char [C.<elements> N/A
20 4 (loss due to the next object alignment)
Instance size: 24 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
可以看到,对象头中有一块 4 字节的区域,显示该数组长度为 2。
4.2 实例数据(Instance Data)
普通对象和 Class 对象的实例数据区域是不同的,需要分开讨论:
- 1、普通对象: 包括当前类声明的实例字段以及父类声明的实例字段,不包括类的静态字段;
- 2、Class 对象: 包括当前类声明的静态字段和方法表等
其中,父类声明的实例字段会放在子类实例字段之前,而字段间的并不是按照源码中的声明顺序排列的,而是相同宽度的字段会分配在一起:引用类型 > long/double > int/float > short/char > byte/boolean。如果虚拟机开启 CompactFields 策略,那么子类较窄的字段有可能插入到父类变量的空隙中。

4.3 对齐填充(Padding)
HotSpot 虚拟机对象的大小必须按 8 字节对齐,如果对象实际占用空间不足 8 字节的倍数,则会在对象末尾增加对齐填充。 对齐填充不仅能够保证对象的起始位置是规整的,同时也是实现指针压缩的一个前提。
5. 什么是指针压缩?
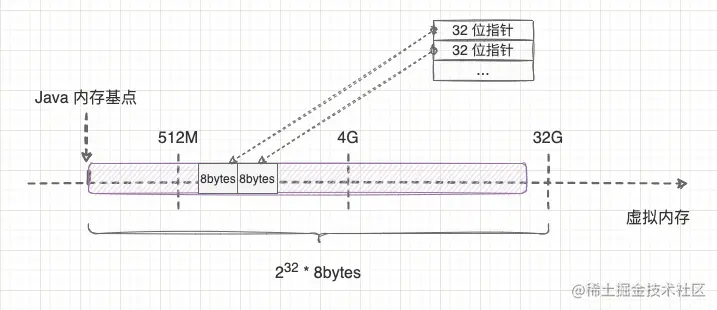
我们都知道 CPU 有 32 位和 64 位的区别,这里的位数决定了 CPU 在内存中的寻址能力,32 位的指针可以表示 4G 的内存空间,而 64 位的指针可以表示一个非常大的天文数字。但是,目前市场上计算机的内存中不可能有这么大的空间,因此 64 位指针中很多高位比特其实是被浪费掉的。 为了提高内存利用效率,Java 虚拟机会采用指针压缩的方式,让 32 位指针不仅可以表示 4G 内存空间,还可以表示略大于 4G (不超过 32 G)的内存空间。这样就可以在使用较大堆内存的情况下继续使用 32 位的指针变量,从而减少程序内存占用。 但是,32 位指针怎么可能表示超过 4G 内存空间?我们把 64 位指针的高 32 位截断之后,剩下的 32 位指针也最多只能表示 4G 空间呀?
在解释这个问题之前,我先解释下为什么 32 位指针可以表示 4G 内存空间呢? 细心的同学会发现,你用 2322^{32}232 计算也只是得到 512M 而已,那么 4G 是怎么计算出来的呢?其实啊,操作系统中最小的内存分配单位是字节,而不是比特位,操作系统无法按位访问内存,只能按字节访问内存。因此,32 位指针其实是表示 232bytes2^{32}bytes232bytes ,而不是 232bits2^{32}bits232bits,算起来就是 4G 内存空间。

理解了 4G 的计算问题后,再解释 32 位指针如何表示 32G 内存空间就很简单了。 这就拐回到上一节提到的对象 8 字节对齐了。操作系统将 8 个比特位组合成 1 个字节,等于说只需要标记每 8 个位的编号,而 Java 虚拟机在保证对象按 8 字节对齐后,也可以只需要标记每 8 个字节的编号,而不需要标记每个字节的编号。因此,32 位指针其实是表示 232∗8bytes2^{32}*8bytes232∗8bytes,算起来就是 32G 内存空间了。如下图所示:
提示: 在上文使用 JOL 分析对象内存布局时,输入日志
Using compressed oop with 3-bit shift.就表示对象是按 8 字节对齐,指针按 3 位位移。
那对象对齐填充继续放大的话,32 位指针是不是可以表示更大的内存空间了?对。 同理,对齐填充放大到 16 位对齐,则可以表示 64G 空间,放大到 32 位对齐,则可以表示 128G 空间。但是,放大对齐填充等于放大了每个对象的平大小,对齐越大填充的空间会越快抵消指针压缩所减少的空间,得不偿失。因此,Java 虚拟机的选择是在内存空间超过 32G 时,放弃指针压缩策略,而不是一味增大对齐填充。
6. 总结
到这里,对象的内存布局就将完了。我们讲到了对象的分配区域、对象数据的访问定位方式以及对象内部的布局形式。
五、Java 的四种引用类型
学习路线图:

1. 认识 Java 引用
1.1 Java 四大引用类型
Java 引用是 Java 虚拟机为了实现更加灵活的对象生命周期管理而设计的对象包装类,一共有四种引用类型,分别是强引用、软引用、弱引用和虚引用。我将它们的区别概括为 3 个维度:
- 维度 1 - 对象可达性状态的区别: 强引用指向的对象是强可达的,而其他引用指向的对象都是弱可达的。当一个对象存在到 GC Root 的引用链时,该对象被认为是强可达的。只有强可达的对象才会认为是存活的对象,才能保证在垃圾收集的过程中不会被回收;
- 维度 2 - 垃圾回收策略的区别: 除了影响对象的可达性状态,不同的引用类型还会影响垃圾收集器回收对象的激进程度:
- 强引用: 强引用指向的对象不会被垃圾收集器回收;
- 软引用: 软引用是相对于强引用更激进的策略,软引用指向的对象在内存充足时会从垃圾收集器中豁免,起到类似强引用的效果,但在内存不足时还是会被垃圾收集器回收。那么软引用通常是用于实现内存敏感的缓存,当有足够空闲内存时保留内存,当空闲内存不足时清理缓存,避免缓存耗尽内存;
- 弱引用和虚引用: 弱引用和虚引用是相对于软引用更激进的策略,弱引用指向的对象无论在内存是否充足的时候,都会被垃圾收集器回收;
- 维度 3 - 感知垃圾回收时机: 虚引用主要的作用是提供了一个感知对象被垃圾回收的机制。在虚拟机即将回收对象之前,如果发现对象还存在虚引用,则会在回收对象后会将引用加入到关联的引用队列中。程序可以通过观察引用队列的方式,来感知到对象即将被垃圾回收的时机,再采取必要的措施。例如 Java Cleaner 工具类,就是基于虚引用实现的回收工具类。需要特别说明的是,并不是只有虚引用才能与引用队列关联,软引用和弱引用都可以与引用队列关联,只是说虚引用唯一的作用就是感知对象垃圾回收时机。
除了我们熟悉的四大引用,虚拟机内部还设计了一个 @hide 的FinalizerReference 引用,用于支持 Java Finalizer 机制,更多内容见 Finalizer 机制。
1.2 指针、引用和句柄有什么区别?
引用、指针和句柄都具有指向对象地址的含义,可以将它们都简单地理解为一个内存地址。只有在具体的问题中,才需要区分它们的含义:
- 1、引用(Reference): 引用是 Java 虚拟机为了实现灵活的对象生命周期管理而实现的对象包装类,引用本身并不持有对象数据,而是通过直接指针或句柄 2 种方式来访问真正的对象数据;
- 2、指针(Point): 指针也叫直接指针,它表示对象数据在内存中的地址,通过指针就可以直接访问对象数据;
- 3、句柄(Handler): 句柄是一种特殊的指针,句柄持有指向对象实例数据和类型数据的指针。使用句柄的优点是让对象在垃圾收集的过程中移动存储区域的话,虚拟机只需要改变句柄中的指针,而引用持有的句柄是稳定的。缺点是需要两次指针访问才能访问到对象数据。
直接指针访问:

句柄访问:
2. 引用使用方法
这一节我们来讨论如何将引用与引用队列的使用方法。
2.1 使用引用对象
- 1、创建引用对象: 直接通过构造器创建引用对象,并且直接在构造器中传递关联的实际对象和引用队列。引用队列可以为空,但虚引用必须关联引用队列,否则没有意义;
- 2、获取实际对象: 在实际对象被垃圾收集器回收之前,通过
Reference#get()可以获取实际对象,在实际对象被回收之后 get() 将返回 null,而虚引用调用 get() 方法永远是返回 null; - 3、解除关联关系: 调用
Reference#clear()可以提前解除关联关系。
get() 和 clear() 最终是调用 native 方法,我们在后文分析。
SoftReference.java
// 已简化
public class SoftReference<T> extends Reference<T> {
public SoftReference(T referent) {
super(referent);
}
public SoftReference(T referent, ReferenceQueue<? super T> q) {
super(referent, q);
}
}
WeakReference.java
public class WeakReference<T> extends Reference<T> {
public WeakReference(T referent) {
super(referent);
}
public WeakReference(T referent, ReferenceQueue<? super T> q) {
super(referent, q);
}
}
PhantomReference.java
public class PhantomReference<T> extends Reference<T> {
// 虚引用 get() 永远返回 null
public T get() {
return null;
}
// 虚引用必须管理引用队列,否则没有意义
public PhantomReference(T referent, ReferenceQueue<? super T> q) {
super(referent, q);
}
}
Reference.java
// 引用对象公共父类
public abstract class Reference<T> {
// 虚拟机内部使用
volatile T referent;
// 关联引用队列
final ReferenceQueue<? super T> queue;
Reference(T referent) {
this(referent, null);
}
Reference(T referent, ReferenceQueue<? super T> queue) {
this.referent = referent;
this.queue = queue;
}
// 获取引用指向的实际对象
public T get() {
// 调用 Native 方法
return getReferent();
}
@FastNative
private final native T getReferent();
// 解除引用与实际对象的关联关系
public void clear() {
// 调用 Native 方法
clearReferent();
}
@FastNative
native void clearReferent();
...
}
2.2 引用队列使用模板
以下为 ReferenceQueue 的使用模板,主要分为 2 个阶段:
- 阶段 1: 创建引用队列实例,并在创建引用对象时关联该队列;
- 阶段 2: 对象在被垃圾回收后,引用对象会被加入引用队列(根据下文源码分析,引用对象在进入引用队列的时候,实际对象已经被回收了)。通过观察
ReferenceQueue#poll()的返回值可以感知对象垃圾回收的时机。
示例程序
// 阶段 1:
// 创建对象
String strongRef = new String("abc");
// 1、创建引用队列
ReferenceQueue<String> referenceQueue = new ReferenceQueue<>();
// 2、创建引用对象,并关联引用队列
WeakReference<String> weakRef = new WeakReference<>(strongRef, referenceQueue);
System.out.println("weakRef 1:" + weakRef);
// 3、断开强引用
strongRef = null;
System.gc();
// 阶段 2:
// 延时 5000 是为了提高 "abc" 被回收的概率
view.postDelayed(new Runnable() {
@Override
public void run() {
System.out.println(weakRef.get()); // 输出 null
// 观察引用队列
Reference<? extends String> ref = referenceQueue.poll();
if (null != ref) {
System.out.println("weakRef 2:" + ref);
// 虽然可以获取到 Reference 对象,但无法获取到引用原本指向的对象
System.out.println(ref.get()); // 输出 null
}
}
}, 5000);
程序输出
I/System.out: weakRef 1:java.lang.ref.WeakReference@3286da7
I/System.out: null
I/System.out: weakRef 2:java.lang.ref.WeakReference@3286da7
I/System.out: null
ReferenceQueue 中大部分 API 是面向 Java 虚拟机内部的,只有 ReferenceQueue#poll() 是面向开发者的。它是非阻塞 API,在队列有数据时返回队头的数据,而在队列为空时直接返回 null。
ReferenceQueue.java
public Reference<? extends T> poll() {
synchronized (lock) {
if (head == null)
return null;
return reallyPollLocked();
}
}
2.3 工具类 Cleaner 使用模板
Cleaner 是虚引用的工具类,用于实现在对象被垃圾回收时额外执行一段清理逻辑,本质上只是将虚引用和引用队列等代码做了简单封装而已。以下为 Cleaner 的使用模板:
示例程序
// 1、创建对象
String strongRef = new String("abc");
// 2、创建清理逻辑
CleanerThunk thunk = new CleanerThunk();
// 3、创建 Cleaner 对象(本质上是一个虚引用)
Cleaner cleaner = Cleaner.create(strongRef, thunk);
private class CleanerThunk implements Runnable {
@Override
public void run() {
// 清理逻辑
}
}
Cleaner.java
// Cleaner 只不过是虚引用的工具类而已
public class Cleaner extends PhantomReference<Object> {
...
}
3. 引用实现原理分析
从这一节开始,我们来深入分析 Java 引用的实现原理,相关源码基于 Android 9.0 ART 虚拟机。
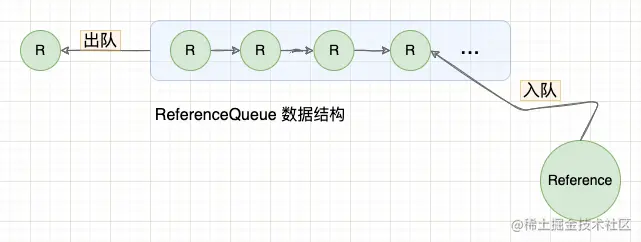
3.1 ReferenceQueue 数据结构
ReferenceQueue 是基于单链表实现的队列,元素按照先进先出的顺序出队(Java OpenJDK 和 Android 中的 ReferenceQueue 实现略有区别,OpenJDK 以先进后出的顺序出队,而 Android 以先进先出的顺序出队)。
Reference.java
public abstract class Reference<T> {
// 关联的引用队列
final ReferenceQueue<? super T> queue;
// 单链表后继指针
Reference queueNext;
}
ReferenceQueue.java
public class ReferenceQueue<T> {
// 入队
boolean enqueue(Reference<? extends T> reference) {
synchronized (lock) {
if (enqueueLocked(reference)) {
lock.notifyAll();
return true;
}
return false;
}
}
// 出队
public Reference<? extends T> poll() {
synchronized (lock) {
if (head == null)
return null;
return reallyPollLocked();
}
}
// 入队
private boolean enqueueLocked(Reference<? extends T> r) {
// 处理 Cleaner 逻辑
if (r instanceof Cleaner) {
Cleaner cl = (sun.misc.Cleaner) r;
cl.clean();
r.queueNext = sQueueNextUnenqueued;
return true;
}
// 尾插法
if (tail == null) {
head = r;
} else {
tail.queueNext = r;
}
tail = r;
tail.queueNext = r;
return true;
}
// 出队
private Reference<? extends T> reallyPollLocked() {
if (head != null) {
Reference<? extends T> r = head;
if (head == tail) {
tail = null;
head = null;
} else {
head = head.queueNext;
}
r.queueNext = sQueueNextUnenqueued;
return r;
}
return null;
}
}
3.2 引用对象与实际对象的关联
在上一节我们提到 Reference#get() 和 Reference#clear() 可以获取或解除关联关系,它们是在 Native 层实现的。最终可以看到关联关系是在 ReferenceProcessor 中维护的,ReferenceProcessor内部我们先不分析了。
对应的 Native 层方法:
namespace art {
// 对应 Java native 方法 Reference#getReferent()
static jobject Reference_getReferent(JNIEnv* env, jobject javaThis) {
ScopedFastNativeObjectAccess soa(env);
ObjPtr<mirror::Reference> ref = soa.Decode<mirror::Reference>(javaThis);
ObjPtr<mirror::Object> const referent = Runtime::Current()->GetHeap()->GetReferenceProcessor()->GetReferent(soa.Self(), ref);
return soa.AddLocalReference<jobject>(referent);
}
// 对应 Java native 方法 Reference#clearReferent()
static void Reference_clearReferent(JNIEnv* env, jobject javaThis) {
ScopedFastNativeObjectAccess soa(env);
ObjPtr<mirror::Reference> ref = soa.Decode<mirror::Reference>(javaThis);
Runtime::Current()->GetHeap()->GetReferenceProcessor()->ClearReferent(ref);
}
// 动态注册 JNI 函数
static JNINativeMethod gMethods[] = {
FAST_NATIVE_METHOD(Reference, getReferent, "()Ljava/lang/Object;"),
FAST_NATIVE_METHOD(Reference, clearReferent, "()V"),
};
void register_java_lang_ref_Reference(JNIEnv* env) {
REGISTER_NATIVE_METHODS("java/lang/ref/Reference");
}
} // namespace art
3.3 引用对象入队过程分析
引用对象加入引用队列的过程发生在垃圾收集器的处理过程中,我将相关流程概括为 2 个阶段:
- 阶段 1: 在垃圾收集的标记阶段,垃圾收集器会标记在本次垃圾收集中豁免的对象(包括强引用对象、FinalizerReference 对象以及不需要在本次回收的 SoftReference 软引用对象)。当一个引用对象指向的实际对象没有被标记时,说明该对象除了被引用对象引用之外已经不存在其他引用关系。那么垃圾收集器会解除引用对象与实际对象的关联关系,并且将引用对象暂存到一个全局链表
unenqueued中,随后 notify 正在等待类对象的线程 (阶段 1 实际的处理过程更复杂,我们稍后再详细分析);
ReferenceQueue.java
// 临时的全局链表
public static Reference<?> unenqueued = null;
// 从 Native 层调用
static void add(Reference<?> list) {
synchronized (ReferenceQueue.class) {
// 此处使用尾插法将 list 加入全局链表 unenqueued,代码略
// 唤醒等待类锁的线程
ReferenceQueue.class.notifyAll();
}
}
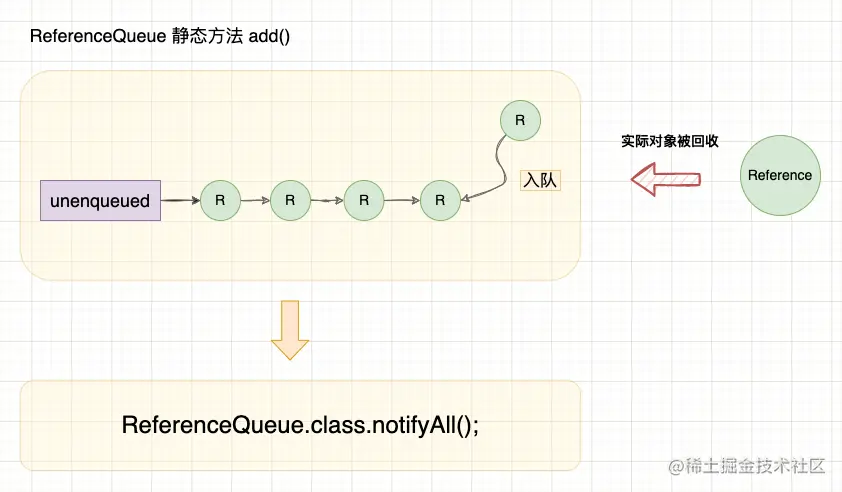
那么,谁在等待这个类对象呢?其实,在虚拟机启动时,会启动一系列守护线程,其中就包括处理引用入队的 ReferenceQueueDaemon 线程和 Finalizer 机制的 FinalizerDaemon 线程,这里唤醒的正是ReferenceQueueDaemon 线程。
源码摘要如下:
void Runtime::StartDaemonThreads() {
// 调用 java.lang.Daemons.start()
Thread* self = Thread::Current();
JNIEnv* env = self->GetJniEnv();
env->CallStaticVoidMethod(WellKnownClasses::java_lang_Daemons, WellKnownClasses::java_lang_Daemons_start);
}
public static void start() {
// 启动四个守护线程:
// ReferenceQueueDaemon:处理引用入队
ReferenceQueueDaemon.INSTANCE.start();
// FinalizerDaemon:处理 Finalizer 机制
FinalizerDaemon.INSTANCE.start();
FinalizerWatchdogDaemon.INSTANCE.start();
HeapTaskDaemon.INSTANCE.start();
}
- 阶段 2:
ReferenceQueueDaemon线程会使用等待唤醒机制轮询消费这个全局链表unenqueued,如果链表不为空则将引用对象投递到对应的引用队列中,否则线程会进入等待。
Daemons.java
private static class ReferenceQueueDaemon extends Daemon {
private static final ReferenceQueueDaemon INSTANCE = new ReferenceQueueDaemon();
ReferenceQueueDaemon() {
super("ReferenceQueueDaemon");
}
// 阶段 2:轮询 unenqueued 全局链表
@Override public void runInternal() {
while (isRunning()) {
Reference<?> list;
// 2.1 同步块
synchronized (ReferenceQueue.class) {
// 2.2 检查 unenqueued 全局链表是否为空
while (ReferenceQueue.unenqueued == null) {
// 2.3 为空则等待 ReferenceQueue.class 类锁
ReferenceQueue.class.wait();
}
list = ReferenceQueue.unenqueued;
ReferenceQueue.unenqueued = null;
}
// 2.4 投递引用对象
// 为什么放在同步块之外:因为 list 已经从静态变量 unenqueued 剥离处理,不用担心其他线程会插入新的引用,所以可以放在 synchronized{} 块之外
ReferenceQueue.enqueuePending(list);
}
}
}
private static class FinalizerDaemon extends Daemon {
...
}
ReferenceQueue.java
// 2.4 投递引用对象
public static void enqueuePending(Reference<?> list) {
Reference<?> start = list;
do {
ReferenceQueue queue = list.queue;
if (queue == null) {
// 2.4.1 没有关联的引用队列,则不需要投递
Reference<?> next = list.pendingNext;
list.pendingNext = list;
list = next;
} else {
// 2.4.2 为了避免反复加锁,这里选择一次性投递相同引用队列的对象
synchronized (queue.lock) {
do {
Reference<?> next = list.pendingNext;
list.pendingNext = list;
// 2.4.3 引用对象入队
queue.enqueueLocked(list);
list = next;
} while (list != start && list.queue == queue);
// 2.4.4 唤醒 queue.lock,跟 remove(...) 有关
queue.lock.notifyAll();
}
}
} while (list != start);
}
至此,引用对象已经加入 ReferenceQueue 中的双向链表,等待消费者调用 ReferenceQueue#poll() 消费引用对象。
使用一张示意图概括整个过程:
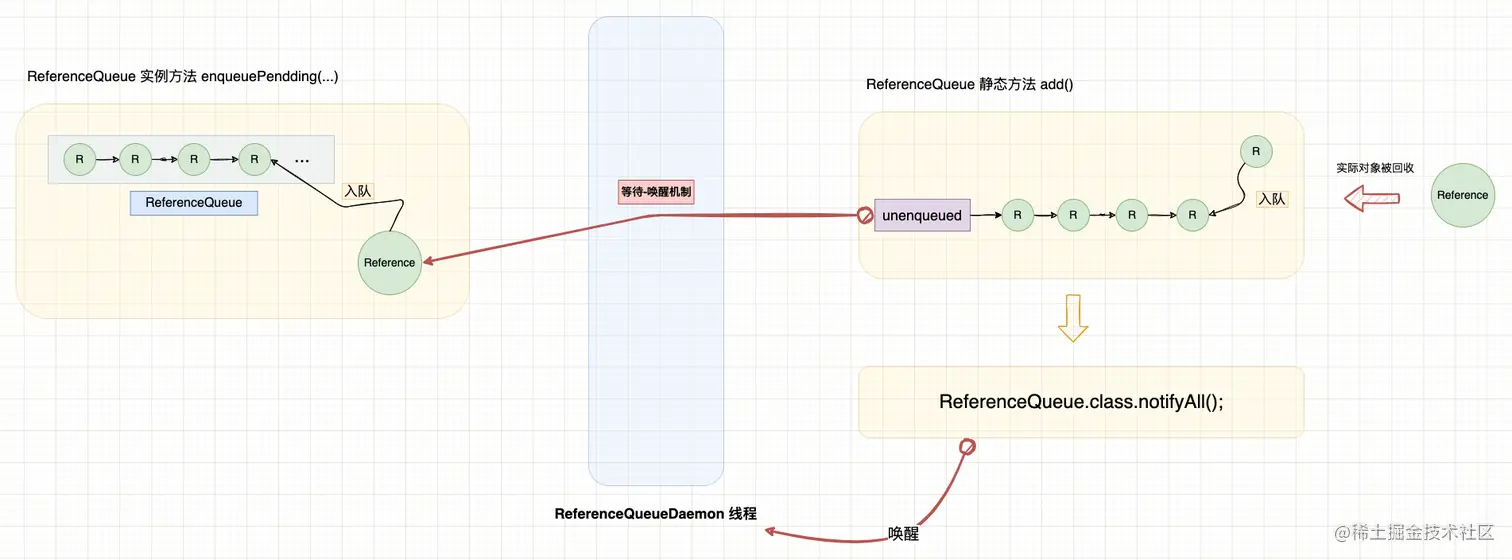
现在,我们回过头来详细分析 阶段 1 中的执行过程: ART 虚拟机存在多种垃圾收集算法,我们以 CMS 并发标记清除算法为例进行分析。先简单回顾下 CMS 并发标记清除算法分为 4 个阶段:
- 初始标记(暂停 mutator 线程): 仅仅标记被 GC Root 直接引用的对象,由于 GC Root 相对较少,这个过程相对比较短;
- 并发标记(恢复 mutator 线程): 对初始标记得到的对象继续递归遍历,这个过程相对耗时。由于此时 mutator 线程和 collector 线程是并发运行的,所以很可能会改变对象的可达性状态,因此这里会记录 mutator 线程所做的修改;
- 重标记(暂停 mutator 线程): 由于并发标记阶段可能会改变对象的可达性状态,因此需要重新标记。但是并不是重新从 GC Root 递归遍历所有对象,而是会根据记录的修改行为缩小追踪范围,所以耗时相对比较短;
- 并发清理(恢复 mutator 线程): 标记工作完成后,进行释放内存操作,这个过程相对耗时。
源码摘要如下:
void MarkSweep::RunPhases() {
// 1、初始标记(只处理 GC Root 直接引用的对象)
MarkRoots(self);
// 2、并发标记(基于初始标记记录的可达对象)
MarkReachableObjects();
// 3.1 重标记(只处理 GC Root 直接引用的对象)
ReMarkRoots();
// 3.2 重标记(只处理并发标记记录的脏对象)
RecursiveMarkDirtyObjects(true/* 是否暂停 */, ...);
// 4. 并发清除
ReclaimPhase();
}
标记阶段: 在垃圾收集的并发标记阶段,会从 GC Root 进行递归遍历。每次找到一个引用类型对象,并且其指向的实际对象没有被标记(说明该对象除了被引用对象引用之外已经不存在其他引用关系),那么将该引用对象加入到 ReferenceProcessor 中对应的临时队列中。
方法调用链:
MarkReachableObjects→RecursiveMark→ProcessMarkStack→ScanObject→DelayReferenceReferentVisitor#operator→DelayReferenceReferent→ReferenceProcessor::DelayReferenceReferent
void ReferenceProcessor::DelayReferenceReferent(ObjPtr<mirror::Class> klass,
ObjPtr<mirror::Reference> ref,
collector::GarbageCollector* collector) {
mirror::HeapReference<mirror::Object>* referent = ref->GetReferentReferenceAddr();
// IsNullOrMarkedHeapReference:判断引用指向的实际对象是否被标记
if (!collector->IsNullOrMarkedHeapReference(referent, /*do_atomic_update*/true)) {
Thread* self = Thread::Current();
// 不同引用类型分别加入不同的队列中
if (klass->IsSoftReferenceClass()) {
// 软引用待处理队列
soft_reference_queue_.AtomicEnqueueIfNotEnqueued(self, ref);
} else if (klass->IsWeakReferenceClass()) {
// 弱引用待处理队列
weak_reference_queue_.AtomicEnqueueIfNotEnqueued(self, ref);
} else if (klass->IsFinalizerReferenceClass()) {
// Fianlizer 引用待处理队列
finalizer_reference_queue_.AtomicEnqueueIfNotEnqueued(self, ref);
} else if (klass->IsPhantomReferenceClass()) {
// 虚引用待处理队列
phantom_reference_queue_.AtomicEnqueueIfNotEnqueued(self, ref);
}
}
}
清理阶段: 在垃圾收集器清理阶段,依次处理临时队列中的引用对象,解除引用对象与实际对象的关联关系,所有解绑的引用对象都会被记录到另一个临时队列 cleared_references_ 中。
方法调用链:
ReclaimPhase→ProcessReferences→ReferenceProcessor::ProcessReferences→ReferenceQueue#ClearWhiteReferences
// Process reference class instances and schedule finalizations.
void ReferenceProcessor::ProcessReferences(bool concurrent,
TimingLogger* timings,
bool clear_soft_references,
collector::GarbageCollector* collector) {
...
// 软引用
soft_reference_queue_.ClearWhiteReferences(&cleared_references_, collector);
// 弱引用
weak_reference_queue_.ClearWhiteReferences(&cleared_references_, collector);
// FinalizeReference(EnqueueFinalizerReferences 在下篇文章分析)
finalizer_reference_queue_.EnqueueFinalizerReferences(&cleared_references_, collector);
// 虚引用
phantom_reference_queue_.ClearWhiteReferences(&cleared_references_, collector);
}
void ReferenceQueue::ClearWhiteReferences(ReferenceQueue* cleared_references,
collector::GarbageCollector* collector) {
while (!IsEmpty()) {
ObjPtr<mirror::Reference> ref = DequeuePendingReference();
mirror::HeapReference<mirror::Object>* referent_addr = ref->GetReferentReferenceAddr();
// IsNullOrMarkedHeapReference:判断引用指向的实际对象是否被标记
if (!collector->IsNullOrMarkedHeapReference(referent_addr, /*do_atomic_update*/false)) {
// 解除引用关系
ref->ClearReferent<false>();
// 加入另一个临时队列 cleared_references_
cleared_references->EnqueueReference(ref);
}
DisableReadBarrierForReference(ref);
}
}
回收对象后: 在实际对象被回收后,调用最终会将临时队列 cleared_references 传递到 Java 层的静态方法 ReferenceQueue#add(),从而存储到 Java 层的 unenqueued 变量中,之后就是交给 ReferenceQueueDaemon 线程处理。
方法调用链:
Heap::CollectGarbageInternal→ReferenceProcessor#EnqueueClearedReferences→ ClearedReferenceTask#Run
class ClearedReferenceTask : public HeapTask {
public:
explicit ClearedReferenceTask(jobject cleared_references) : HeapTask(NanoTime()), cleared_references_(cleared_references) {
}
virtual void Run(Thread* thread) {
ScopedObjectAccess soa(thread);
jvalue args[1];
// 调用 Java 层 ReferenceQueue#add 方法
args[0].l = cleared_references_;
InvokeWithJValues(soa, nullptr, WellKnownClasses::java_lang_ref_ReferenceQueue_add, args);
soa.Env()->DeleteGlobalRef(cleared_references_);
}
private:
const jobject cleared_references_;
};
至此,阶段 1 分析完毕。
3.4 FinalizeReference 引用的处理
为了实现对象的 Finalizer 机制,虚拟机设计了 FinalizerReference 引用类型,FinalizeReference 引用的处理过程与其他引用类型是相同的。主要区别在于 阶段 1 中解除引用对象与实际对象的关联关系后,会把实际对象暂存到 FinalizeReference 的 zombie 字段中。 阶段 2 的处理是完全相同的,ReferenceQueueDaemon 线程会将 FinalizeReference 投递到关联的引用对象中。随后,守护线程 FinalizerDaemon 会轮询观察引用队列,并执行实际对象上的 finalize() 方法。
更多内容分析,见 Finalizer 机制
4. 总结
小结以下引用管理中最主要的环节:
- 1、在实际对象被回收后,引用对象会暂存到全局临时队列
unenqueued队列; - 2、守护线程
ReferenceQueueDaemon会轮询unenqueued队列,将引用对象分别投递到关联的引用队列中; - 3、守护线程
FinalizerDaemon会轮询观察引用队列,并执行实际对象上的 finalize() 方法。
使用一张示意图概括整个过程:
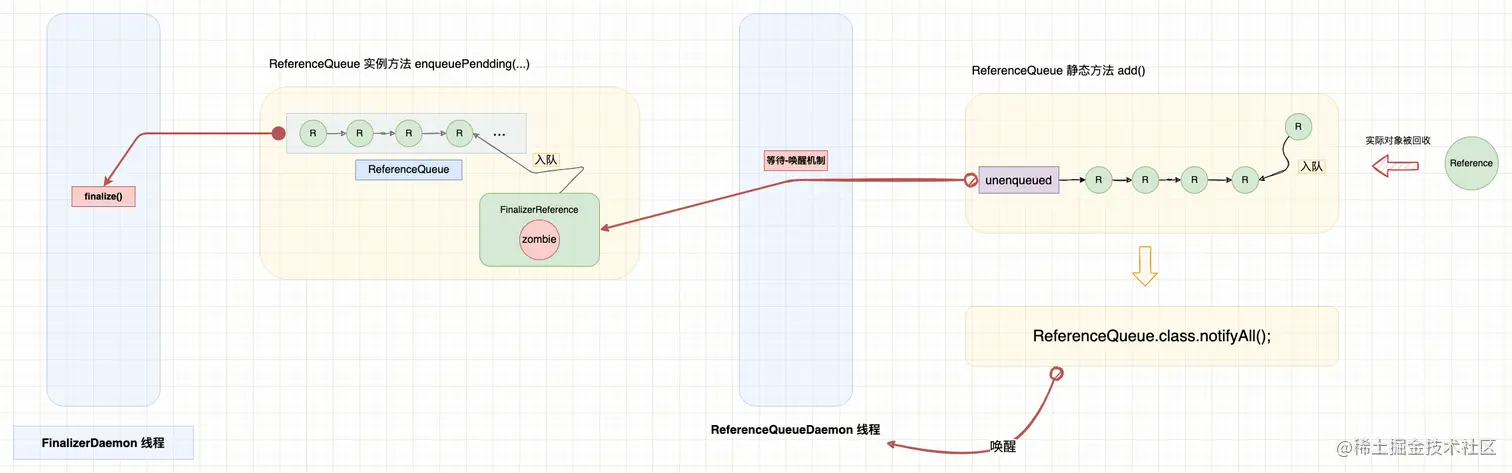
下一篇文章里,我们将更深入地分析 Java Finalizer 机制的实现原理,以及分析 Finalizer 存在的问题。例如为什么 Finalizer 机制是不稳定和危险的。
六、为什么 finalize() 方法只会执行一次?
学习路线图:

1. 认识 Finalizer 机制
1.1 为什么要使用 Finalizer 机制?
Java 的 Finalizer 机制的作用在一定程度上是跟 C/C++ 析构函数类似的机制。当一个对象的生命周期即将终结时,也就是即将被垃圾收集器回收之前,虚拟机就会调用对象的 finalize() 方法,从而提供了一个释放资源的时机。
1.2 Finalizer 存在的问题
虽然 Java Finalizer 机制是起到与 C/C++ 析构函数类似的作用,但两者的定位是有差异的。C/C++ 析构函数是回收对象资源的正常方式,与构造函数是一一对应的,而 Java Finalizer 机制是不稳定且危险的,不被推荐使用的,因为 Finalizer 机制存在以下 3 个问题:
- 问题 1 - Finalizer 机制执行时机不及时: 由于执行 Finalizer 机制的线程是一个守护线程,它的执行优先级是比用户线程低的,所以当一个对象变为不可达对象后,不能保证一定及时执行它的 finalize() 方法。因此,当大量不可达对象的 Finalizer 机制没有及时执行时,就有可能造成大量资源来不及释放,最终耗尽资源;
- 问题 2 - Finalizer 机制不保证执行: 除了执行时机不稳定,甚至不能保证 Finalizer 机制一定会执行。当程序结束后,不可达对象上的 Finalizer 机制有可能还没有运行。假设程序依赖于 Finalizer 机制来更新持久化状态,例如释放数据库的锁,就有可能使得整个分布式系统陷入死锁;
- 问题 3 - Finalizer 机制只会执行一次: 如果不可达对象在 finalize() 方法中被重新启用为可达对象,那么在它下次变为不可达对象后,不会再次执行 finalize() 方法。这与 Finalizer 机制的实现原理有关,后文我们将深入虚拟机源码,从源码层面深入理解。
1.3 什么时候使用 Finalizer 机制?
由于 Finalizer 机制存在不稳定性,因此不应该将 Finalizer 机制作为释放资源的主要策略,而应该作为释放资源的兜底策略。程序应该在不使用资源时主动释放资源,或者实现 AutoCloseable 接口并通过 try-with-resources 语法确保在有异常的情况下依然会释放资源。而 Finalizer 机制作为兜底策略,虽然不稳定但也好过忘记释放资源。
不过,Finalizer 机制已经被标记为过时,使用 Cleaner 机制作为释放资源的兜底策略(本质上是 PhantomReference 虚引用)是相对更好的选择。虽然 Cleaner 机制也存在相同的不稳定性,但总体上比 Finalizer 机制更好。
2. Finalizer 机制原理分析
从这一节开始,我们来深入分析 Java Finalizer 机制的实现原理,相关源码基于 Android 9.0 ART 虚拟机。
2.1 引用实现原理回顾
在上一篇文章中,我们分析过 Java 引用类型的实现原理,Java Finalizer 机制也是其中的一个环节,我们先对整个过程做一次简单回顾。
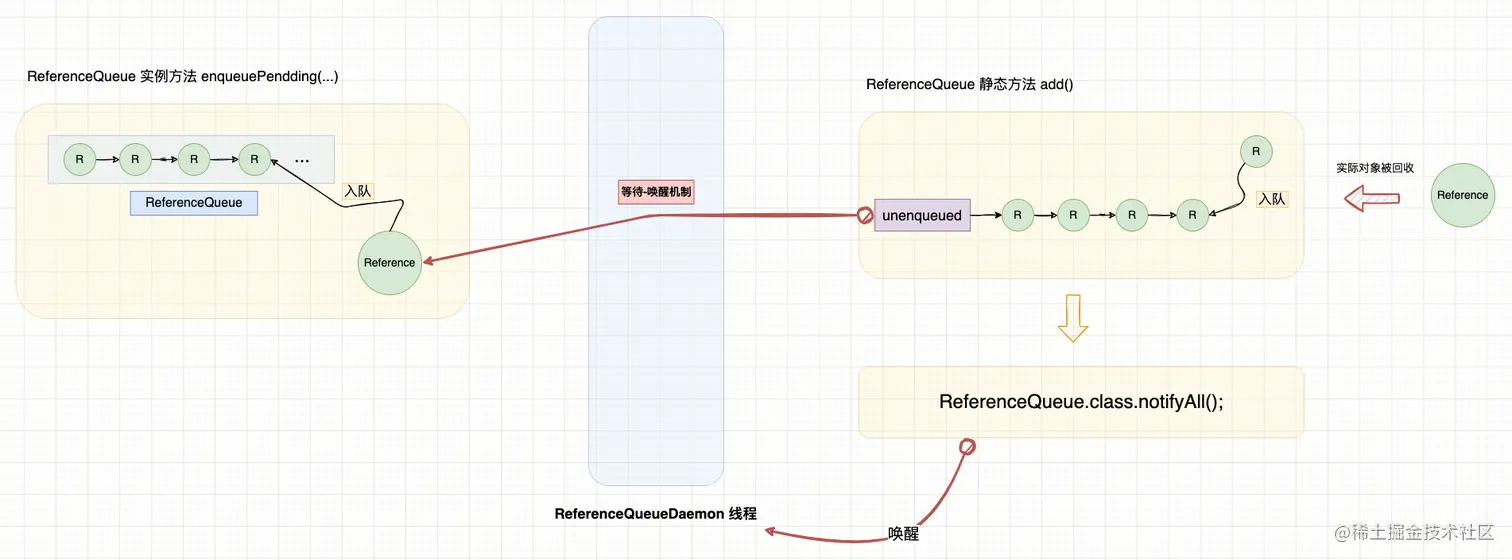
2.2 创建 FinalizerReference 引用对象
我们都知道 Java 有四大引用类型,除此之外,虚拟机内部还设计了 @hide 的 FinalizerReference 类型来支持 Finalizer 机制。Reference 引用对象是用来实现更加灵活的对象生命周期管理而设计的对象包装类,Finalizer 机制也与对象的生命周期有关,因此存在这样 “第 5 种引用类型” 也能理解。
在虚拟机执行类加载的过程中,会将重写了 Object#finalize() 方法的类型标记为 finalizable 类型。每次在创建标记为 finalizable 的对象时,虚拟机内部会同时创建一个关联的 FinalizerReference 引用对象,并将其暂存到一个全局的链表中 (如果不存在全局的变量中,没有强引用持有的 FinalizerReference 本身在下次 GC 直接就被回收了)。
void Heap::AddFinalizerReference(Thread* self, ObjPtr<mirror::Object>* object) {
ScopedObjectAccess soa(self);
ScopedLocalRef<jobject> arg(self->GetJniEnv(), soa.AddLocalReference<jobject>(*object));
jvalue args[1];
args[0].l = arg.get();
// 调用 Java 层静态方法 FinalizerReference#add
InvokeWithJValues(soa, nullptr, WellKnownClasses::java_lang_ref_FinalizerReference_add, args);
*object = soa.Decode<mirror::Object>(arg.get());
}
FinalizerReference.java
// 关联的引用队列
public static final ReferenceQueue<Object> queue = new ReferenceQueue<Object>();
// 全局链表头指针(使用一个双向链表持有 FinalizerReference,否则没有强引用的话引用对象本身直接就被回收了)
private static FinalizerReference<?> head = null;
private FinalizerReference<?> prev;
private FinalizerReference<?> next;
// 从 Native 层调用
public static void add(Object referent) {
// 创建 FinalizerReference 引用对象,并关联引用队列
FinalizerReference<?> reference = new FinalizerReference<Object>(referent, queue);
synchronized (LIST_LOCK) {
// 头插法加入全局单链表
reference.prev = null;
reference.next = head;
if (head != null) {
head.prev = reference;
}
head = reference;
}
}
public static void remove(FinalizerReference<?> reference) {
// 从双向链表中移除,代码略
}
2.3 在哪里执行 finalize() 方法?
根据我们对引用队列的理解,当我们在创建引用对象时关联引用队列,可以实现感知对象回收时机的作用。当引用指向的实际对象被垃圾回收后,引用对象会被加入引用队列。那么,是谁在消费这个引用队列呢?
在虚拟机启动时,会启动一系列守护线程,其中除了处理引用入队的 ReferenceQueueDaemon 线程,还包括执行 Finalizer 机制的 FinalizerDaemon 线程。FinalizerDaemon 线程会轮询观察引用队列,并执行实际对象上的 finalize() 方法。
提示: FinalizerDaemon 是一个守护线程,因此 finalize() 的执行优先级低。
public static void start() {
// 启动四个守护线程
ReferenceQueueDaemon.INSTANCE.start();
FinalizerDaemon.INSTANCE.start();
FinalizerWatchdogDaemon.INSTANCE.start();
HeapTaskDaemon.INSTANCE.start();
}
// 已简化
private static class FinalizerDaemon extends Daemon {
private static final FinalizerDaemon INSTANCE = new FinalizerDaemon();
// 这个队列就是 FinalizerReference 关联的引用队列
private final ReferenceQueue<Object> queue = FinalizerReference.queue;
FinalizerDaemon() {
super("FinalizerDaemon");
}
@Override public void runInternal() {
while (isRunning()) {
// 1、从引用队列中取出引用
FinalizerReference<?> finalizingReference = (FinalizerReference<?>)queue.poll();
// 2、执行引用所指向对象 Object#finalize()
doFinalize(finalizingReference);
// 提示:poll() 是非阻塞的,FinalizerDaemon 是与 FinalizerWatchDogDaemon 配合实现等待唤醒机制的
}
@FindBugsSuppressWarnings("FI_EXPLICIT_INVOCATION")
private void doFinalize(FinalizerReference<?> reference) {
// 2.1 移除 FinalizerReference 对象
FinalizerReference.remove(reference);
// 2.2 取出引用所指向的对象(不可思议,为什么不为空呢?)
Object object = reference.get();
// 2.3 解除关联关系
reference.clear();
// 2.4 调用 Object#finalize()
object.finalize();
}
}
这里你有发现问题吗,当普通的引用对象在进入引用队列时,虚拟机已经解除了引用对象与实际对象的关联,此时调用 Reference#get() 应该返回 null 才对。 但 FinalizerReference#get() 居然还能拿到实际对象,实际对象不是已经被回收了吗!? 这只能从源码中寻找答案。
2.4 FinalizerReference 引用对象入队过程
由于标记为 finalizable 的对象在被回收之前需要调用 finalize() 方法,因此这一类对象的回收过程比较特殊,会经历两次 GC 过程。我将整个过程概括为 3 个阶段:
- 阶段 1 - 首次 GC 过程: 当垃圾收集器发现对象变成不可达对象时,会解绑实际对象与引用对象的关联关系。当实际对象被清除后,会将引用对象加入关联的引用队列(这个部分我们在上一篇文章中分析过了)。然而,finalizable 对象还需要调用 finalize() 方法,所以首次 GC 时还不能回收实际对象。为此,垃圾收集器会主动将原本不可达的实际对象重新标记为可达对象,使其从本次垃圾收集中豁免,并且将实际对象临时保存到 FinalizerReference 的
zombie字段中。实际对象与 FinalizerReference 的关联关系依然会解除,否则会陷入死循环永远无法回收; - 阶段 2 - FinalizerDaemon 执行 finalize() 方法: FinalizerDaemon 守护线程消费引用队列时,调用
ReferenceQueue#get()只是返回暂存在zombie字段中的实际对象而已,其实此时关联关系早就解除了(这就是为什么 FinalizerReference#get() 还可以获得实际对象)。 - 阶段 3 - 二次 GC: 由于实际对象和 FinalizerReference 已经没有关联关系了,第二次回收过程跟普通对象相同。前提是 finalize() 中将实际对象重新变成可达对象,那么二次 GC 不会那么快执行,要等到它重新变为不可达状态。
提示: 这就是为什么 finalize() 方法只会执行一次,因为执行 finalize() 时实际对象和 FinalizerReference 已经解除关联了,后续的垃圾回收跟普通的非 finalizable 对象一样。
源码摘要如下:
垃圾收集器清理过程:
方法调用链:
ReclaimPhase→ProcessReferences→ReferenceProcessor::ProcessReferences→ReferenceQueue::EnqueueFinalizerReferences
void ReferenceQueue::EnqueueFinalizerReferences(ReferenceQueue* cleared_references, collector::GarbageCollector* collector) {
while (!IsEmpty()) {
ObjPtr<mirror::FinalizerReference> ref = DequeuePendingReference()->AsFinalizerReference();
mirror::HeapReference<mirror::Object>* referent_addr = ref->GetReferentReferenceAddr();
// IsNullOrMarkedHeapReference:判断引用指向的实际对象是否被标记
if (!collector->IsNullOrMarkedHeapReference(referent_addr, /*do_atomic_update*/false)) {
// MarkObject:重新标记位可达对象
ObjPtr<mirror::Object> forward_address = collector->MarkObject(referent_addr->AsMirrorPtr());
// 将实际对象暂存到 zombie 字段
ref->SetZombie<false>(forward_address);
// 解除关联关系(普通引用对象亦有此操作)
ref->ClearReferent<false>();
// 将引用对象加入 cleared_references 队列(普通引用对象亦有此操作)
cleared_references->EnqueueReference(ref);
}
DisableReadBarrierForReference(ref->AsReference());
}
}
实际对象暂存在 zombie 字段中:
FinalizerReference.java
// 由虚拟机维护,用于暂存实际对象
private T zombie;
// 2.2 取出引用所指向的对象(其实是取 zombie 字段)
@Override public T get() {
return zombie;
}
// 2.3 解除关联关系,实际上虚拟机内部早就解除关联关系了,这里只是返回暂存在 zombie 中的实际对象
@Override public void clear() {
zombie = null;
}
至此,Finalizer 机制实现原理分析完毕。
使用一张示意图概括整个过程:
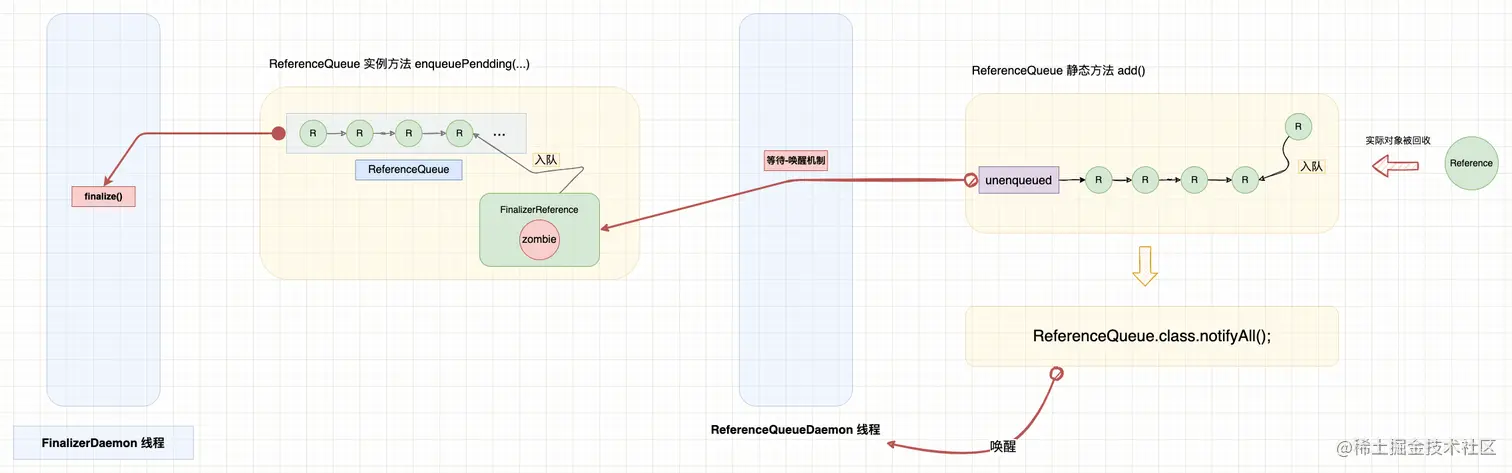
3. 总结
总结一下 Finalizer 机制最主要的环节:
- 1、为了实现对象的 Finalizer 机制,虚拟机设计了
FinalizerReference引用类型。重写了Object#finalize()方法的类型在类加载过程中会被标记位 finalizable 类型,每次创建对象时会同步创建关联的 FinalizerReference 引用对象; - 2、不可达对象在即将被垃圾收集器回收时,虚拟机会解除实际对象与引用对象的关联关系,并将引用对象加入关联的引用队列中。然而,由于 finalizable 对象还需要执行 finalize() 方法,因此垃圾收集器会主动将对象标记为可达对象,并将实际对象暂存到 FinalizerReference 的
zombie字段中; - 3、守护线程
ReferenceQueueDaemon会轮询全局临时队列unenqueued队列,将引用对象分别投递到关联的引用队列中 - 4、守护线程
FinalizerDaemon会轮询观察引用队列,并执行实际对象上的 finalize() 方法。














 510
510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









