







前言
结构体字节对齐相关的文章网络上有很多,看了其中几篇写的不错的之后,做了一点总结,仅供自己日后回忆,请网友忽略。看过众多关于字节对齐的博文中,写的我认为比较好的是实验室苏同学(ACM大神)写的http://c4fun.cn/blog/2014/01/11/struct-alignment/,本文有部分内容摘自这篇博客。另外Wiki上面的字节对齐讲的非常好,虽然是英文的。字节对齐的目的很简单,就是提高CPU读取的效率。例如,32位机,CPU一次可以读32位,那么一个4字节的数据的起始地址刚好在4的倍数上,那么CPU一次就可以读完,否则,CPU要读取两次。
内存对齐方法:
1、确定字节对齐值
1)基本数据自身对齐值:基本数据类型的自身对齐值,一般由编译器及系统决定;
2)结构体自身对齐值:取决于结构体成员中自身对齐值的最大值;
3)指定对齐值:通过#pragma pack(n)宏指定的对齐值;
4)有效对齐值:取决于自身对齐值和指定对齐值中的较小值。
Wiki上32位系统的字节对齐值。
- A char (one byte) will be 1-byte aligned.
- A short (two bytes) will be 2-byte aligned.
- An int (four bytes) will be 4-byte aligned.
- A long (four bytes) will be 4-byte aligned.
- A float (four bytes) will be 4-byte aligned.
- A double (eight bytes) will be 8-byte aligned on Windows and 4-byte aligned on Linux (8-byte with -malign-double compile time option).
- A long long (eight bytes) will be 8-byte aligned.
- A long double (ten bytes with C++Builder and DMC, eight bytes with Visual C++, twelve bytes with GCC) will be 8-byte aligned with C++Builder, 2-byte aligned with DMC, 8-byte aligned with Visual C++ and 4-byte aligned with GCC.
- Any pointer (four bytes) will be 4-byte aligned. (e.g.: char*, int*)
The only notable difference in alignment for a 64-bit system when compared to a 32-bit system is:
- A long (eight bytes) will be 8-byte aligned.
- A double (eight bytes) will be 8-byte aligned.
- A long double (eight bytes with Visual C++, sixteen bytes with GCC) will be 8-byte aligned with Visual C++ and 16-byte aligned with GCC.
- Any pointer (eight bytes) will be 8-byte aligned.
值得注意的是:
如果用#pragma pack(n)指定对齐值的话,真正的字节对齐值会取min(n,类型本身的对齐值)。
2.根据对齐值进行对齐
对齐方法遵循下面两条规则,源自C4FUN博文。(有的博文上是4条规则,化简了就是这两条)
1)假设结构体的起始位置为0,结束位置为n,n+1必须是结构体有效对齐值的倍数。(如int类型,假设起始位置为0,结束位置为3,则n+1=4一定为有效对齐值的倍数)
2)假设某成员的起始对齐值是m,m必须是该成员有效对齐值的倍数。
实验结果
#include <iostream>
typedef struct _C{
int _int_32;
char _char_8;
int* _ptr_64;
short _short_16;
}C;
typedef struct __C{
int _int_32;
char _char_8;
short _short_16;
int* _ptr_64;
}C_;
int main(int argc, const char * argv[])
{
std::cout <<"sizeof int ="<<sizeof(int)<<std::endl;
std::cout <<"sizeof char ="<<sizeof(char)<<std::endl;
std::cout <<"sizeof int*(pointer) ="<<sizeof(int*)<<std::endl;
std::cout <<"sizeof short ="<<sizeof(short)<<std::endl;
std::cout <<"sizeof _C ="<<sizeof(C)<<std::endl;
std::cout <<"sizeof __C ="<<sizeof(C_)<<std::endl;
return 0;
}
命令行输出:
sizeof int =4
sizeof char =1
sizeof int*(pointer) =8
sizeof short =2
sizeof _C =24
sizeof __C =16
从输出结果可以看出,第一个结构体的size为24字节,第二个位16字节。
分析结构体_C的内存布局:
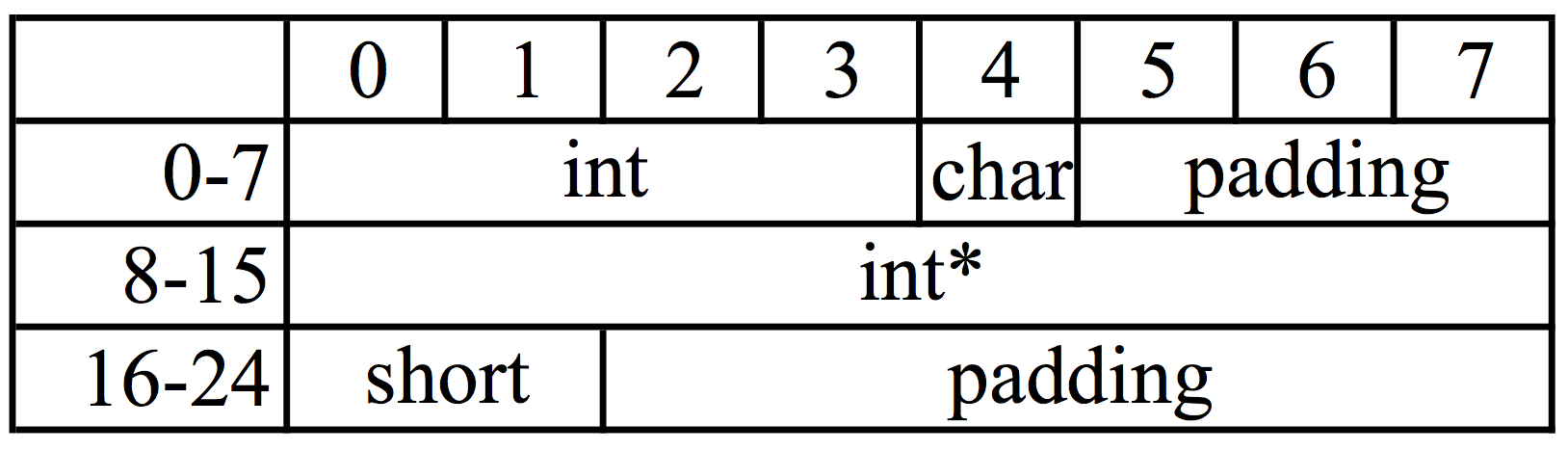
而结构体__C的内存布局:

结构体_C中为了为了满足规则1,在地址5-7位置处填补了3个padding字节。为了满足规则2,在地址18-24处,填补了6个字节的padding。而结构体__C中,将short的编排顺序改变之后,刚好满足了规则2。所以节省了8个字节。可见,有效的利用变量编排顺序,可以达到优化程序性能、缩小程序内存占用的目的,以后写结构体的时候不能随意编排顺序,应按照字节对齐的规则,以最节省空间的方式编排。

















 419
419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









