







实现延迟任务的方式有很多,各有利弊,有单机和分布式的。在这里做一个总结,在遇到这类问题的时候希望给大家一个参考和思路。
延迟任务有别于定式任务,定式任务往往是固定周期的,有明确的触发时间。而延迟任务一般没有固定的开始时间,它常常是由一个事件触发的,而在这个事件触发之后的一段时间内触发另一个事件。延迟任务相关的业务场景如下:
场景一:物联网系统经常会遇到向终端下发命令,如果命令一段时间没有应答,就需要设置成超时。
场景二:订单下单之后30分钟后,如果用户没有付钱,则系统自动取消订单。
下面我们来探讨一些方案,其实这些方案没有好坏之分,和系统架构一样,只有最适合。对于数据量较小的情况下,任意一种方案都可行,考虑的是简单明了和开发速度,尽量避免把系统搞复杂了。而对于数据量较大的情况下,就需要有一些选择,并不是所有的方案都适合了。
1. 数据库轮询
这是比较常见的一种方式,所有的订单或者所有的命令一般都会存储在数据库中。我们会起一个线程去扫数据库或者一个数据库定时Job,找到那些超时的数据,直接更新状态,或者拿出来执行一些操作。这种方式很简单,不会引入其他的技术,开发周期短。
如果数据量比较大,千万级甚至更多,插入频率很高的话,上面的方式在性能上会出现一些问题,查找和更新对会占用很多时间,轮询频率高的话甚至会影响数据入库。一种可以尝试的方式就是使用类似TBSchedule或Elastic-Job这样的分布式的任务调度加上数据分片功能,把需要判断的数据分到不同的机器上执行。
如果数据量进一步增大,那扫数据库肯定就不行了。另一方面,对于订单这类数据,我们也许会遇到分库分表,那上述方案就会变得过于复杂,得不偿失。
2. JDK延迟队列
Java中的DelayQueue位于java.util.concurrent包下,作为单机实现,它很好的实现了延迟一段时间后触发事件的需求。由于是线程安全的它可以有多个消费者和多个生产者,从而在某些情况下可以提升性能。DelayQueue本质是封装了一个PriorityQueue,使之线程安全,加上Delay功能,也就是说,消费者线程只能在队列中的消息“过期”之后才能返回数据获取到消息,不然只能获取到null。
之所以要用到PriorityQueue,主要是需要排序。也许后插入的消息需要比队列中的其他消息提前触发,那么这个后插入的消息就需要最先被消费者获取,这就需要排序功能。PriorityQueue内部使用最小堆来实现排序队列。队首的,最先被消费者拿到的就是最小的那个。使用最小堆让队列在数据量较大的时候比较有优势。使用最小堆来实现优先级队列主要是因为最小堆在插入和获取时,时间复杂度相对都比较好,都是O(logN)。
下面例子实现了未来某个时间要触发的消息。我把这些消息放在DelayQueue中,当消息的触发时间到,消费者就能拿到消息,并且消费,实现处理方法。示例代码:
-
/* -
* 定义放在延迟队列中的对象,需要实现Delayed接口 -
*/ -
public class DelayedTask implements Delayed { -
private int _expireInSecond = 0; -
public DelayedTask(int delaySecond) { -
Calendar cal = Calendar.getInstance(); -
cal.add(Calendar.SECOND, delaySecond); -
_expireInSecond = (int) (cal.getTimeInMillis() / 1000); -
} -
public int compareTo(Delayed o) { -
long d = (getDelay(TimeUnit.NANOSECONDS) - o.getDelay(TimeUnit.NANOSECONDS)); -
return (d == 0) ? 0 : ((d < 0) ? -1 : 1); -
} -
public long getDelay(TimeUnit unit) { -
//TODO Auto-generated method stub -
Calendar cal = Calendar.getInstance(); -
return _expireInSecond - (cal.getTimeInMillis() / 1000); -
} -
}
下面定义了三个延迟任务,分别是10秒,5秒和15秒。依次入队列,期望5秒钟后,5秒的消息先被获取到,然后每个5秒钟,依次获取到10秒数据和15秒的那个数据。
-
public static void main(String[] args) throws InterruptedException { -
//TODO Auto-generated method stub -
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); -
//定义延迟队列 -
DelayQueue<DelayedTask> delayQueue = new DelayQueue<DelayedTask>(); -
//定义三个延迟任务 -
DelayedTask task1 = new DelayedTask(10); -
DelayedTask task2 = new DelayedTask(5); -
DelayedTask task3 = new DelayedTask(15); -
delayQueue.add(task1); -
delayQueue.add(task2); -
delayQueue.add(task3); -
System.out.println(sdf.format(new Date()) + " start"); -
while(delayQueue.size() != 0) { -
//如果没到时间,该方法会返回 -
DelayedTask task = delayQueue.poll();
-
if(task != null) { -
Date now = new Date(); -
System.out.println(sdf.format(now)); -
} -
Thread.sleep(1000); -
} -
}
输出结果如下图:
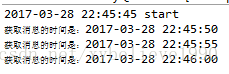
DelayQueue是一种很好的实现方式,虽然是单机,但是可以多线程生产和消费,提高效率。拿到消息后也可以使用异步线程去执行下一步的任务。如果有分布式的需求可以使用Redis来实现消息的分发,如果对消息的可靠性有非常高的要求可以使用消息中间件:
使用DelayQueue需要考虑程序挂掉之后,内存里面未处理消息的丢失带来的影响。
3. JDK ScheduledExecutorService
JDK自带的一种线程池,它能调度一些命令在一段时间之后执行,或者周期性的执行。文章开头的一些业务场景主要使用第一种方式,即,在一段时间之后执行某个操作。代码例子如下:
-
public static void main(String[] args) { -
// TODO Auto-generated method stub -
ScheduledExecutorService executor = Executors.newScheduledThreadPool(100); -
for(inti = 10; i > 0; i--) { -
executor.schedule(new Runnable() { -
public void run() { -
//TODO Auto-generated method stub -
System.out.println("Work start, thread id:" + Thread.currentThread().getId() + " " + sdf.format(new Date())); -
} -
}, i, TimeUnit.SECONDS); -
} -
}
执行结果:
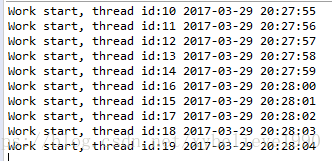
ScheduledExecutorService的实现类ScheduledThreadPoolExecutor提供了一种并行处理的模型,简化了线程的调度。DelayedWorkQueue是类似DelayQueue的实现,也是基于最小堆的、线程安全的数据结构,所以会有上例排序后输出的结果。
ScheduledExecutorService比上面一种DelayQueue更加实用。因为,一般来说,使用DelayQueue获取消息后触发事件都会实用多线程的方式执行,以保证其他事件能准时进行。而ScheduledThreadPoolExecutor就是对这个过程进行了封装,让大家更加方便的使用。同时在加强了部分功能,比如定时触发命令。
4. 时间轮
时间轮是一种非常惊艳的数据结构。其在Linux内核中使用广泛,是Linux内核定时器的实现方法和基础之一。按使用场景,大致可以分为两种时间轮:原始时间轮和分层时间轮。分层时间轮是原始时间轮的升级版本,来应对时间“槽”数量比较大的情况,对内存和精度都有很高要求的情况。我们延迟任务的场景一般只需要用到原始时间轮就可以了。
原始时间轮:如下图一个轮子,有8个“槽”,可以代表未来的一个时间。如果以秒为单位,中间的指针每隔一秒钟转动到新的“槽”上面,就好像手表一样。如果当前指针指在1上面,我有一个任务需要4秒以后执行,那么这个执行的线程回调或者消息将会被放在5上。那如果需要在20秒之后执行怎么办,由于这个环形结构槽数只到8,如果要20秒,指针需要多转2圈。位置是在2圈之后的5上面(20 % 8 + 1)。这个圈数需要记录在槽中的数据结构里面。这个数据结构最重要的是两个指针,一个是触发任务的函数指针,另外一个是触发的总第几圈数。时间轮可以用简单的数组或者是环形链表来实现。
相比DelayQueue的数据结构,时间轮在算法复杂度上有一定优势。DelayQueue由于涉及到排序,需要调堆,插入和移除的复杂度是O(lgn),而时间轮在插入和移除的复杂度都是O(1)。
时间轮比较好的开源实现是Netty的
-
//创建Timer, 精度为100毫秒, -
HashedWheelTimer timer = new HashedWheelTimer(); -
System.out.println(sdf.format(new Date())); -
MyTask task1 = new MyTask(); -
MyTask task2 = new MyTask(); -
MyTask task3 = new MyTask(); -
timer.newTimeout(task1, 5, TimeUnit.SECONDS); -
timer.newTimeout(task2, 10, TimeUnit.SECONDS); -
timer.newTimeout(task3, 15, TimeUnit.SECONDS); -
//阻塞main线程 -
try{ -
System.in.read(); -
} catch(IOException e) { -
//TODO Auto-generated catch block -
e.printStackTrace(); -
}
其中HashedWheelTimer有多个构造函数。其中:
ThreadFactory :创建线程的类,默认Executors.defaultThreadFactory()。
TickDuration:多少时间指针顺时针转一格,单位由下面一个参数提供。
TimeUnit:上一个参数的时间单位。
TicksPerWheel:时间轮上的格子数。
如果一个任务要在120s后执行,时间轮是默认参数的话,那么这个任务在时间轮上需要经过
120000ms / (512 * 100ms) = 2轮
120000ms % (512 * 100ms) = 176格。
在使用HashedWheelTimer的过程中,延迟任务的实现最好使用异步的,HashedWheelTimer的任务管理和执行都在一个线程里面。如果任务比较耗时,那么指针就会延迟,导致整个任务就会延迟。
4. Quartz
quartz是一个企业级的开源的任务调度框架,quartz内部使用TreeSet来保存Trigger,如下图。Java中的TreeSet是使用TreeMap实现,TreeMap是一个红黑树实现。红黑树的插入和删除复杂度都是logN。和最小堆相比各有千秋。最小堆插入比红黑树快,删除顶层节点比红黑树慢。

相比上述的三种轻量级的实现功能丰富很多。有专门的任务调度线程,和任务执行线程池。quartz功能强大,主要是用来执行周期性的任务,当然也可以用来实现延迟任务。但是如果只是实现一个简单的基于内存的延时任务的话,quartz就稍显庞大。
5. Redis ZSet
Redis中的ZSet是一个有序的Set,内部使用HashMap和跳表(SkipList)来保证数据的存储和有序,HashMap里放的是成员到score的映射,而跳跃表里存放的是所有的成员,排序依据是HashMap里存的score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
-
public class ZSetTest { -
private JedisPool jedisPool = null; -
//Redis服务器IP -
private String ADDR = "10.23.22.42"; -
//Redis的端口号 -
private int PORT = 6379; -
private SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); -
public void intJedis() { -
jedisPool = new JedisPool(ADDR, PORT); -
} -
public static void main(String[] args) { -
//TODO Auto-generated method stub -
ZSetTest zsetTest = new ZSetTest(); -
zsetTest.intJedis(); -
zsetTest.addItem(); -
zsetTest.getItem(); -
zsetTest.deleteZSet(); -
} -
public void deleteZSet() { -
Jedis jedis = jedisPool.getResource(); -
jedis.del("zset_test"); -
} -
public void addItem() { -
Jedis jedis = jedisPool.getResource(); -
Calendar cal1 = Calendar.getInstance(); -
cal1.add(Calendar.SECOND, 10); -
int second10later = (int) (cal1.getTimeInMillis() / 1000); -
Calendar cal2 = Calendar.getInstance(); -
cal2.add(Calendar.SECOND, 20); -
int second20later = (int) (cal2.getTimeInMillis() / 1000); -
Calendar cal3 = Calendar.getInstance(); -
cal3.add(Calendar.SECOND, 30); -
int second30later = (int) (cal3.getTimeInMillis() / 1000); -
Calendar cal4 = Calendar.getInstance(); -
cal4.add(Calendar.SECOND, 40); -
int second40later = (int) (cal4.getTimeInMillis() / 1000); -
Calendar cal5 = Calendar.getInstance(); -
cal5.add(Calendar.SECOND, 50); -
int second50later = (int) (cal5.getTimeInMillis() / 1000); -
jedis.zadd("zset_test", second50later, "e"); -
jedis.zadd("zset_test", second10later, "a"); -
jedis.zadd("zset_test", second30later, "c"); -
jedis.zadd("zset_test", second20later, "b"); -
jedis.zadd("zset_test", second40later, "d"); -
System.out.println(sdf.format(new Date()) + " add finished."); -
} -
public void getItem() { -
Jedis jedis = jedisPool.getResource(); -
while(true) { -
try { -
Set<Tuple> set = jedis.zrangeWithScores("zset_test", 0, 0); -
String value = ((Tuple) set.toArray()[0]).getElement(); -
int score = (int) ((Tuple) set.toArray()[0]).getScore(); -
Calendar cal = Calendar.getInstance(); -
int nowSecond = (int) (cal.getTimeInMillis() / 1000); -
if (nowSecond >= score) { -
jedis.zrem("zset_test", value); -
System.out.println(sdf.format(new Date()) + " removed value:" + value); -
} -
if(jedis.zcard("zset_test") <= 0) -
{ -
System.out.println(sdf.format(new Date()) + " zset empty "); -
return; -
} -
Thread.sleep(1000); -
} catch(InterruptedException e) { -
//TODO Auto-generated catch block -
e.printStackTrace(); -
} -
} -
} -
}
在用作延迟任务的时候,可以在添加数据的时候,使用zadd把score写成未来某个时刻的unix时间戳。消费者使用zrangeWithScores获取优先级最高的(最早开始的的)任务。注意,zrangeWithScores并不是取出来,只是看一下并不删除,类似于Queue的peek方法。程序对最早的这个消息进行验证,是否到达要运行的时间,如果是则执行,然后删除zset中的数据。如果不是,则继续等待。
由于zrangeWithScores 和 zrem是先后使用,所以有可能有并发问题,即两个线程或者两个进程都会拿到一样的一样的数据,然后重复执行,最后又都会删除。如果是单机多线程执行,或者分布式环境下,可以使用Redis事务,也可以使用由Redis实现的分布式锁,或者使用下例中Redis Script。你可以在Redis官方的Transaction 章节找到事务的相关内容。
使用Redis的好处主要是:
1. 解耦:把任务、任务发起者、任务执行者的三者分开,逻辑更加清晰,程序强壮性提升,有利于任务发起者和执行者各自迭代,适合多人协作。
2. 异常恢复:由于使用Redis作为消息通道,消息都存储在Redis中。如果发送程序或者任务处理程序挂了,重启之后,还有重新处理数据的可能性。
3. 分布式:如果数据量较大,程序执行时间比较长,我们可以针对任务发起者和任务执行者进行分布式部署。特别注意任务的执行者,也就是Redis的接收方需要考虑分布式锁的问题。
6. Jesque
Jesque是Resque的java实现,Resque是一个基于Redis的Ruby项目,用于后台的定时任务。Jesque实现延迟任务的方法也是在Redis里面建立一个ZSet,和上例一样的处理方式。上例提到在使用ZSet作为优先级队列的时候,由于zrangeWithScores 和 zrem没法保证原子性,所有在分布式环境下会有问题。在Jesque中,它使用的Redis Script来解决这个问题。Redis Script可以保证操作的原子性,相比事务也减少了一些网络开销,性能更加出色。
7. RabbitMQ TTL和DXL
使用RabbitMQ的TTL和DXL实现延迟队列在这里不做详细的介绍。
综上所述,解决延迟队列有很多种方法。选择哪个解决方案也需要根据不同的数据量、实时性要求、已有架构和组件等因素进行判断和取舍。对于比较简单的系统,可以使用数据库轮训的方式。数据量稍大,实时性稍高一点的系统可以使用JDK延迟队列(也许需要解决程序挂了,内存中未处理任务丢失的情况)。如果需要分布式横向扩展的话推荐使用Redis的方案。但是对于系统中已有RabbitMQ,那RabbitMQ会是一个更好的方案。















 2879
2879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









