






随着DeepSeek爆火,面试中也越来越高频出现,因此训练营也更新了DeepSeek系列技术的深入拆解。包括MLA、MTP、专家负载均衡、FP8混合精度训练,Dual-Pipe等关键技术,力求做到全网最硬核的解析~
本文对主流大模型并行训练方式进行了简单介绍,并分析了其通信量以及编排方式。
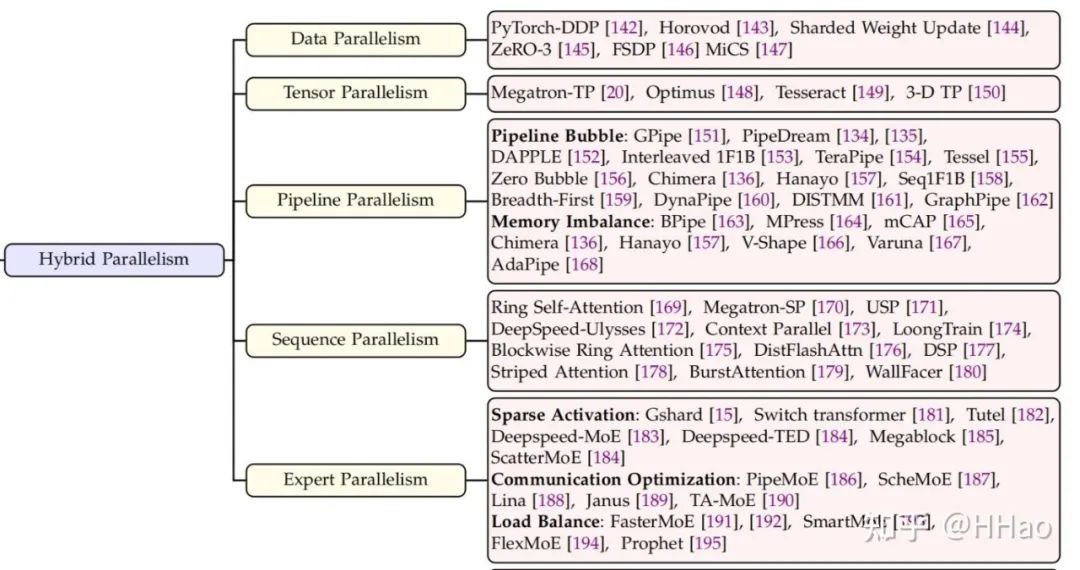
01 并行策略
目前主流的并行策略可以分为 5 种:
- DP 数据并行
- PP 流水线并行
- TP 张量并行
- SP 序列并行
- EP 专家并行
Efficient training of large language models on distributed infrastructures: a survey 中的 overview
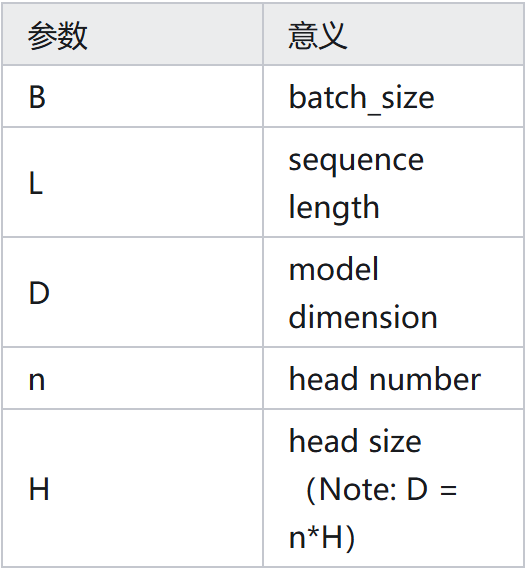
02前提
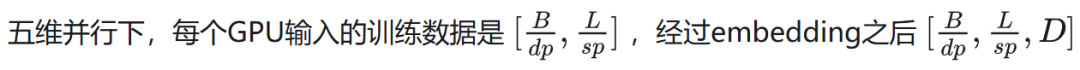
03数据并行 (Data parallelism)

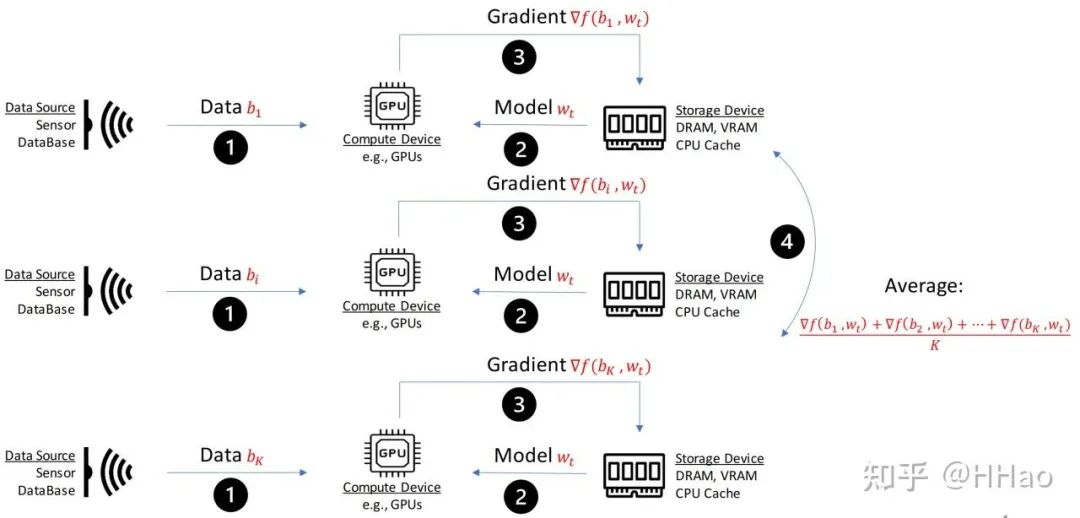
3.1 通信量

3.2 通信模式
Backward:Allreduce
3.3 流量编排
DP 通信次数较少,总通信量相对较低,且可以与反向计算 Overlap (ZeRO/FSDP 等实现方式),通常编排到 Spine/Inter-pod switch (clos 架构) 或 leaf switch (multi-rail 架构)。
04流水线并行(Pipeline parallelism)
对模型进行切分的一种方式,将模型按照 transformer layer 进行切分。
如 Meta LLaMa3 中 126 transformer 层,被切到 16 个 PP 组中,第一个和最后一个 PP 组中为 7 层(第一个 PP 要做 embedding/位置编码等,最后一个 PP 组需要做 loss 计算),其余 8 层。
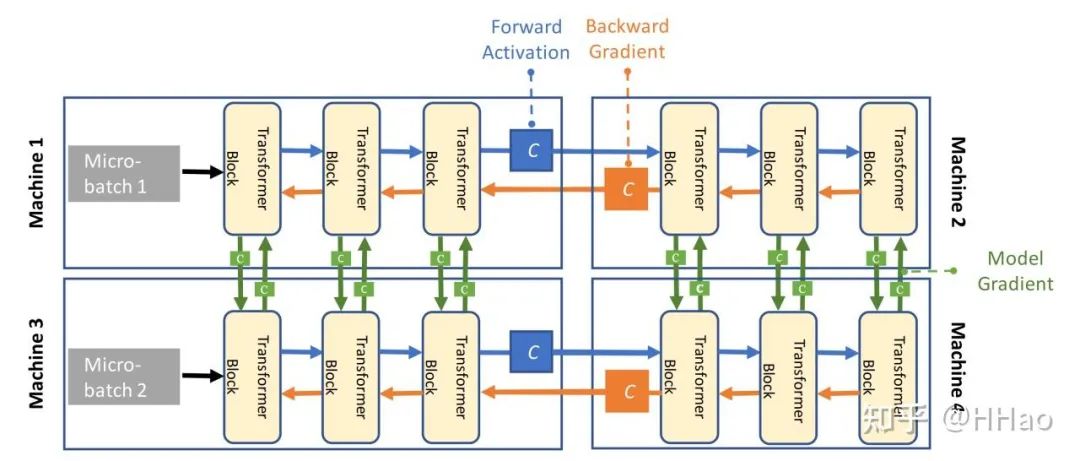
采自 hkust 课程 PPT

4.1 通信量

4.2 通信模式
fwd/bwd:P2P
4.3 流量编排
PP 通信次数少,通信量低,且可以通过多级流水分 micro batch 的方式和前向计算 Overlap。
一般被编排到 spine switch (clos/muti-rail)。工业界实现中,相当 DP 流量,编排更内层。
05张量并行(Tensor parallelism)
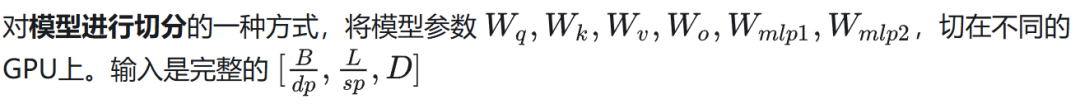
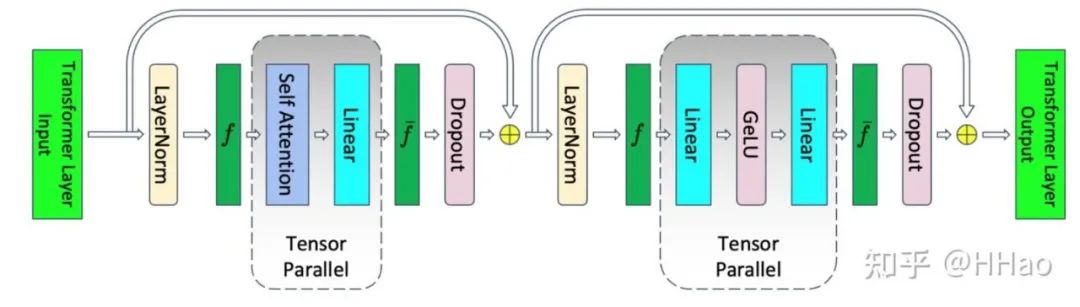
Megatron 中 TP 的实现
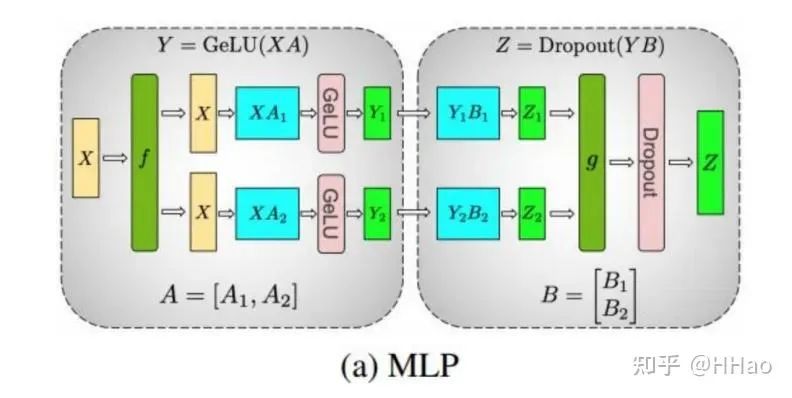
对 MLP 进行切分,第一个 MLP A 纵切,第二个 MLP B 横切
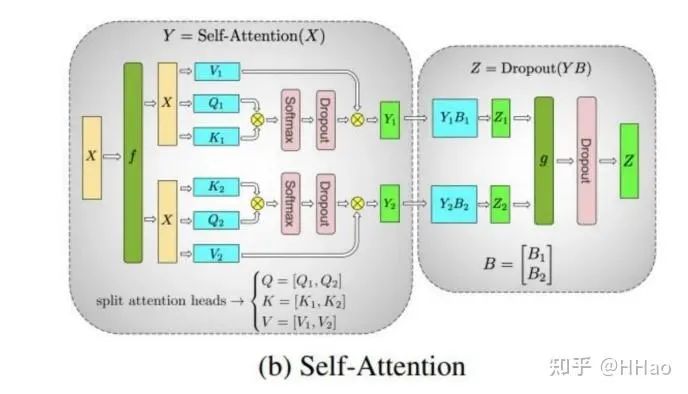
对 Attention 中的多头进行切分,将不同的头切分到不同的 GPU 上
5.1 通信量
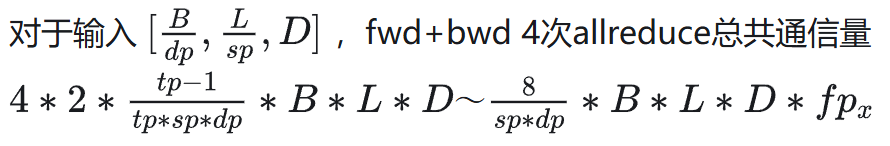
5.2 通信模式
fwd/bwd: Allreduce
5.3 流量编排
通信频繁,总通信量大,编排在 High bandwidth domain,比如单 Server 内 Nvlink。
06序列并行 (Sequence parallelism)
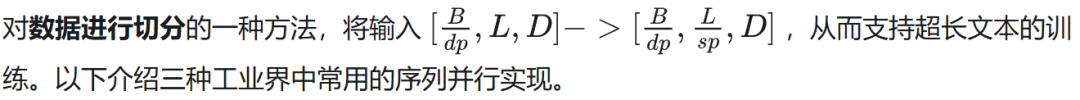
6.1 TP-SP Megatron
注意到在 TP 中,Layernorm 层和 Droupout 层没有被切分并行,因为其在 D 维度上存在依赖,而L维度上不存在依赖,故考虑将数据在 L 维度进行切分后并行,并行度 SP=TP。
该方式更像是一种 TP 的拓展实现,而不是传统意义上的拆分 L 维度来计算 attention。
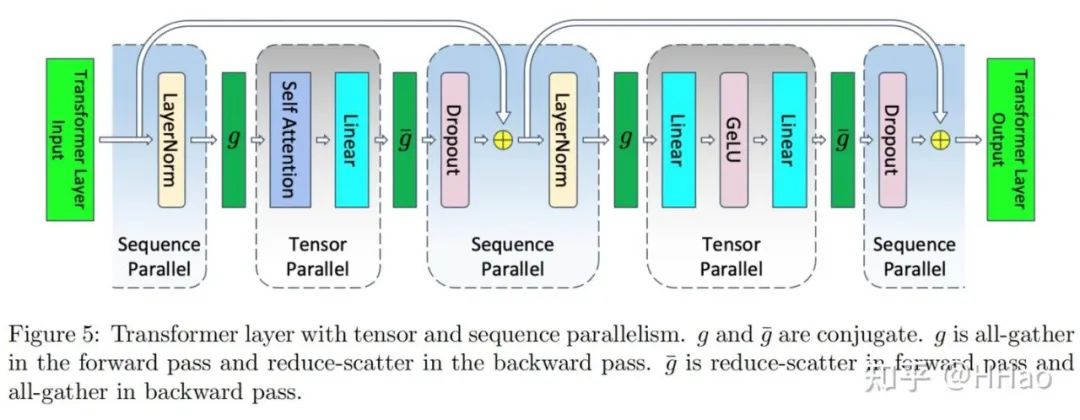
Megatron 中 TP-sp 的实现
6.1.1 通信量
Megatron 中为了减少单 GPU 存储消耗,选择反向计算的时候重新计算完整输入而不是存,多引入 2 次 allgather。

USP: A Unified Sequence Parallelism Approach forLong Context Generative AI 中的通信量分析
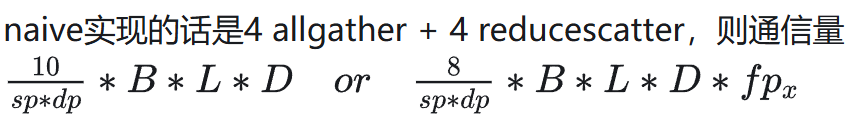
6.1.2 通信模式
all-gather 和 reduce-scatter
6.1.3 流量编排
和 TP 一致,Server 内 Nvlink 优先,TP 组即 SP 组。
6.2 Ulysses Deepspeed

**总体思想:**每个 GPU 上全部 head 的部分 QKV —all2all→每个 GPU 上部分 head 的完整 QKV;多 GPU 分布式 attention 计算→每个 GPU 算一部分 head 的 attention。
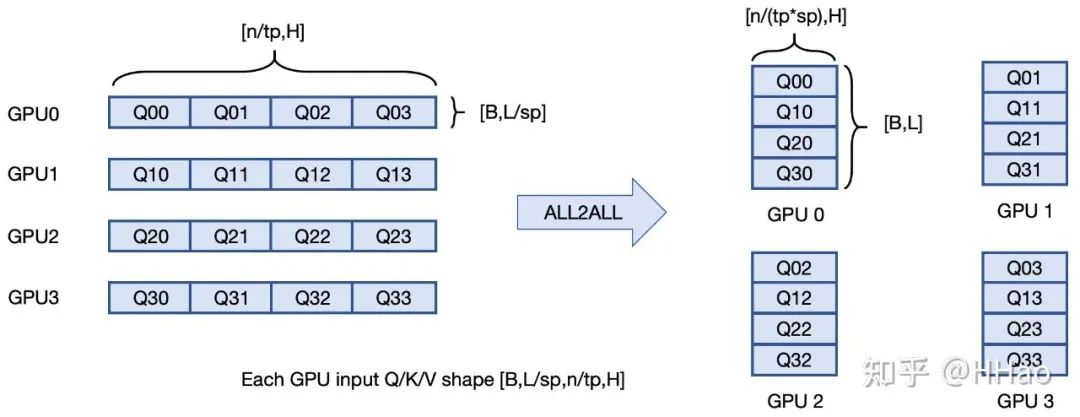
比较抽象,all2all 发送过程
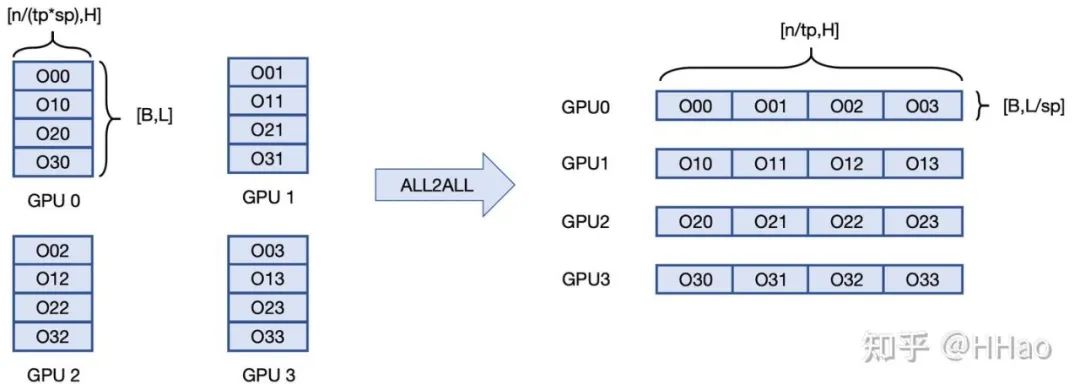
all2all 发回
6.2.1 通信量
QKVO 前向 4 次 all2all,dQ dK dV dO 反向 4 次 all2all。
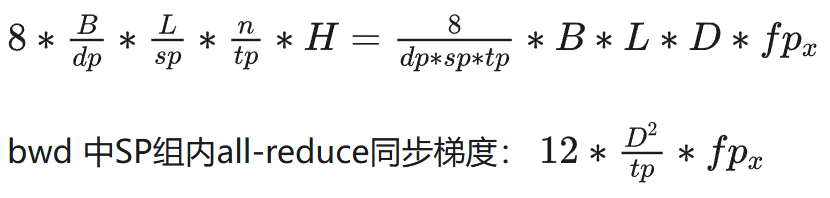
6.2.2 通信模式
fwd+bwd:all2all (qkvo),Allreduce 同步梯度。
6.2.3 流量编排
通信次数多,单次流量小,all2all 需要高 bisection 带宽,尽量编排到 HBD,不够就 leaf/spine switch。
6.3 Context Parallelism Megatron

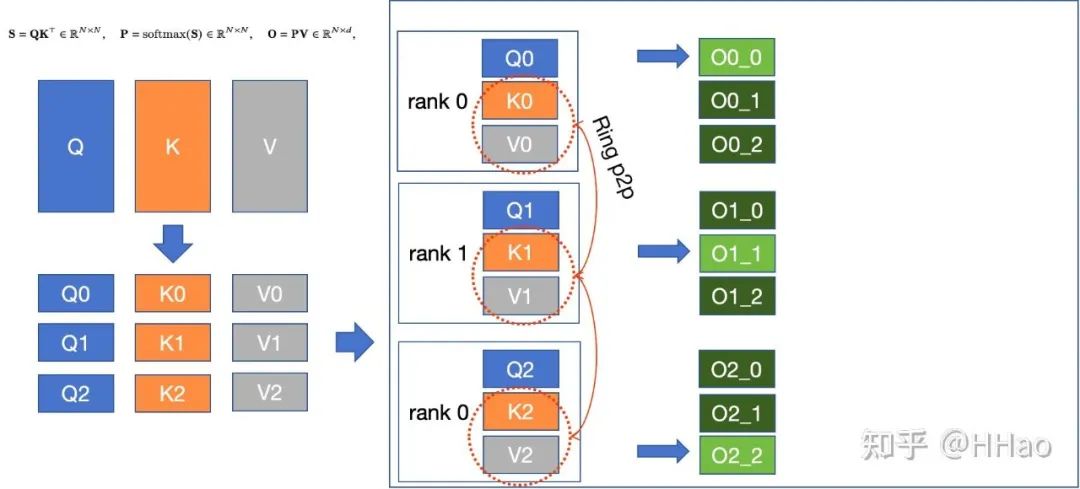
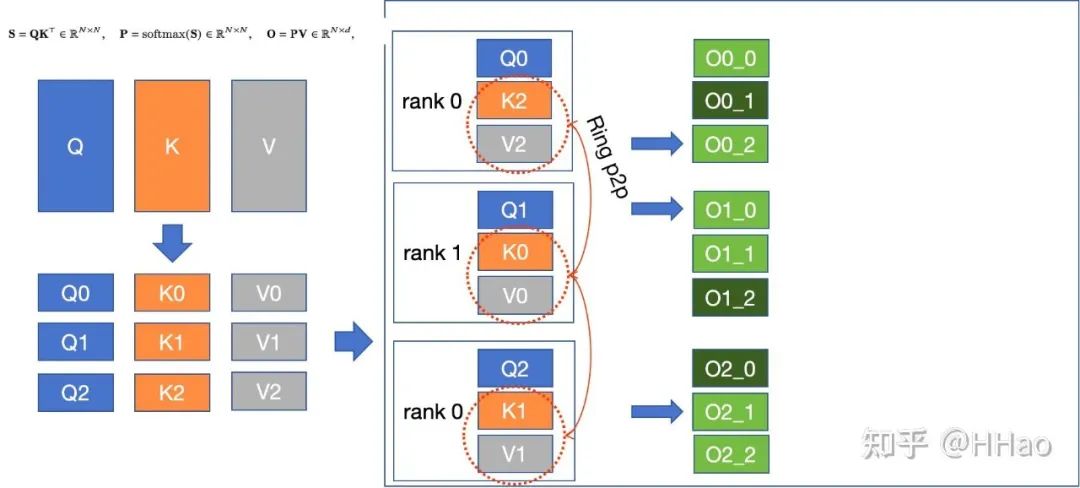
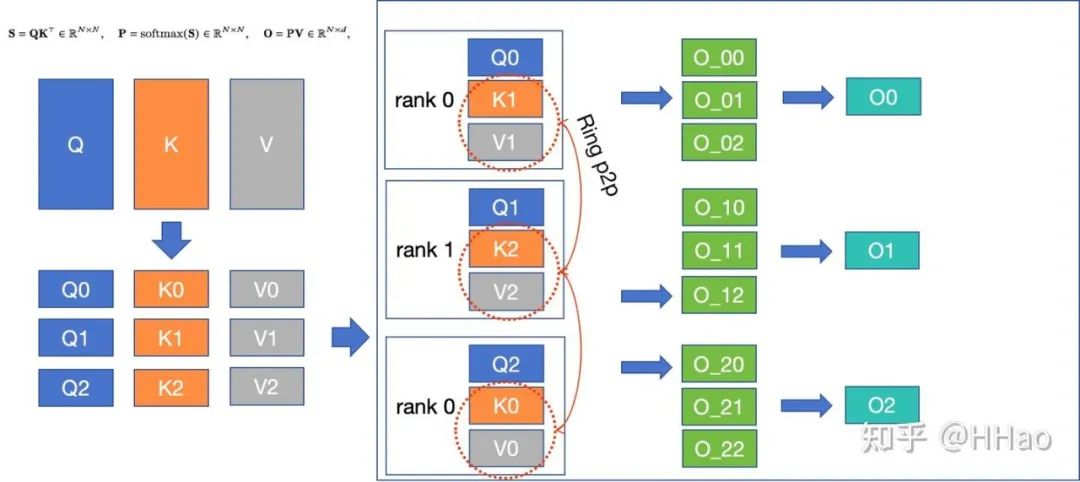
6.3.1 通信量
fwd+bwd 2(sp-1)次 P2P,每次传 kv/dk dv,通信量。

6.3.2 通信模式
P2P 和 Allreduce。
6.3.3 流量编排
通信次数多,单次流量中,最好编排到 HBD,不够就 leaf/spine switch。
07专家并行(Expert parallelism)
针对 MoE 模型训练的特有的并行方式,对模型进行切分。
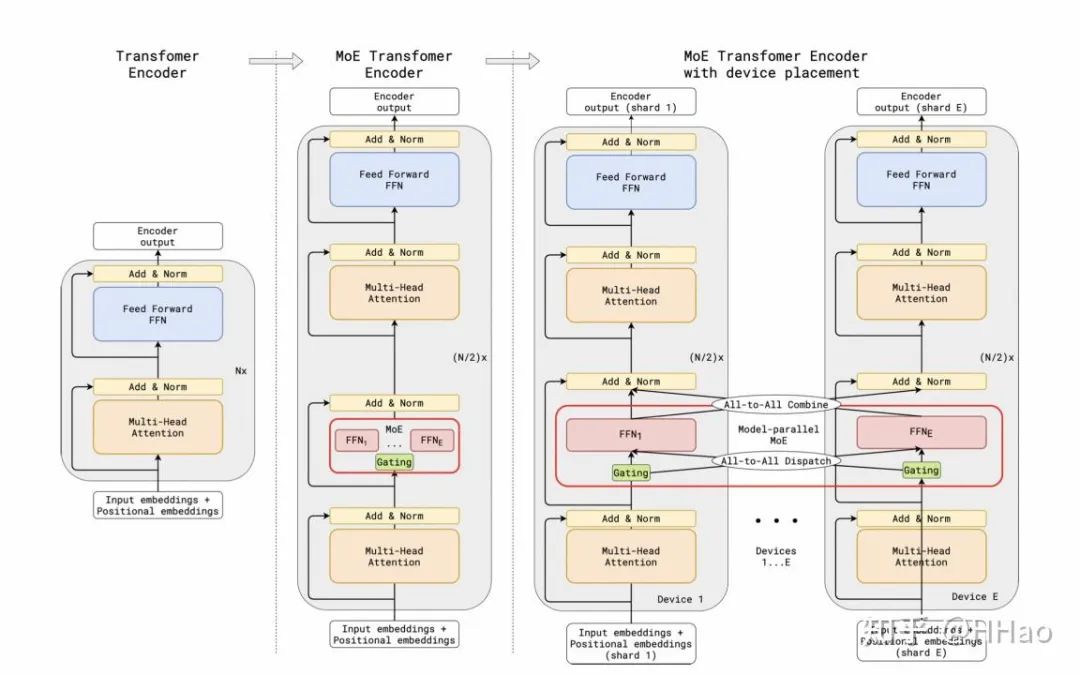
6.4.1 通信量
假设 EP 组内负载均衡能够做到极致,token 均分到每一个 EP 组 rank。前后向分别 2 次 all2all。
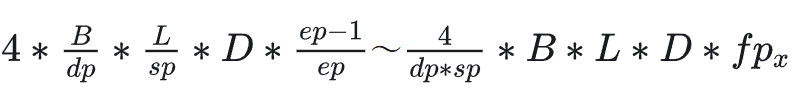
EP 和 TP 一起使用时会存在冗余的通信,可以使用 Group-wise 的 all2all 优化方式,将 TP 组内的 all2all 省略,转化成 TP 组内的 all gather。
6.4.2 通信模式
fwd/bwd 2 次 all2all。
6.4.3 流量编排
前后向时每专家层 2 次,需要 all2all,要求 bisetion 带宽,但量 group-wise 后相对 TP/SP 少,无 SP 时最好能编排到 HBD,有 SP 时可以编排到 leaf/spine switch。
08总结
以华为 UB-mesh 论文中的数据为例子,该表的数据是来自于华为训练一个 2T 参数的 MoE 模型的流量统计(猜测此 2T 模型专家数较少,可能类似于 GPT4-2T 的模型,只有 16 专家,导致 EP 小,TP 大)。
我们根据此表可以得知华为的编排是:TP>SP>EP>PP>DP。
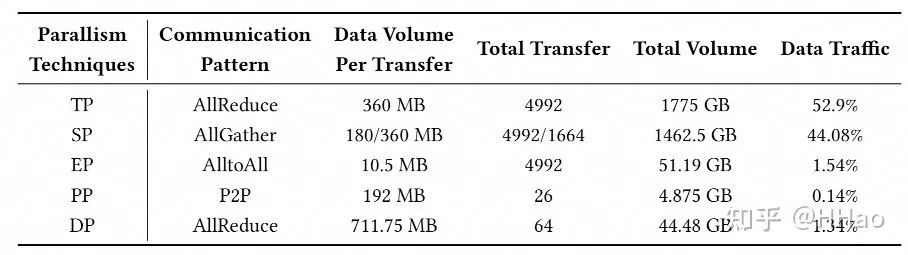
UB-Mesh 训练 MoE-2T 的流量分析
以上分析都是比较笼统且粗略的计算,具体模型还需具体分析,实现中对通信的优化/overlap 方式会导致通信量/编排存在变化。
比如 Deepseek v3 的 EP 实现中是 FP8 Dispatch + BF16 Combine,此时通信量计算不能一概而论。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
0基础如何入门大模型?
大模型目前在人工智能领域可以说正处于一种“炙手可热”的状态,吸引了很多人的关注和兴趣,也有很多新人小白想要学习入门大模型,那么,如何入门大模型呢?
下面给大家分享一份2025最新版的大模型学习路线,帮助新人小白更系统、更快速的学习大模型!
有需要完整版学习路线,可以微信扫描下方二维码,或点击下方链接免费领取!
**读者福利 |** 👉2024最新《AGI大模型学习资源包》免费分享 **(安全链接,放心点击)**

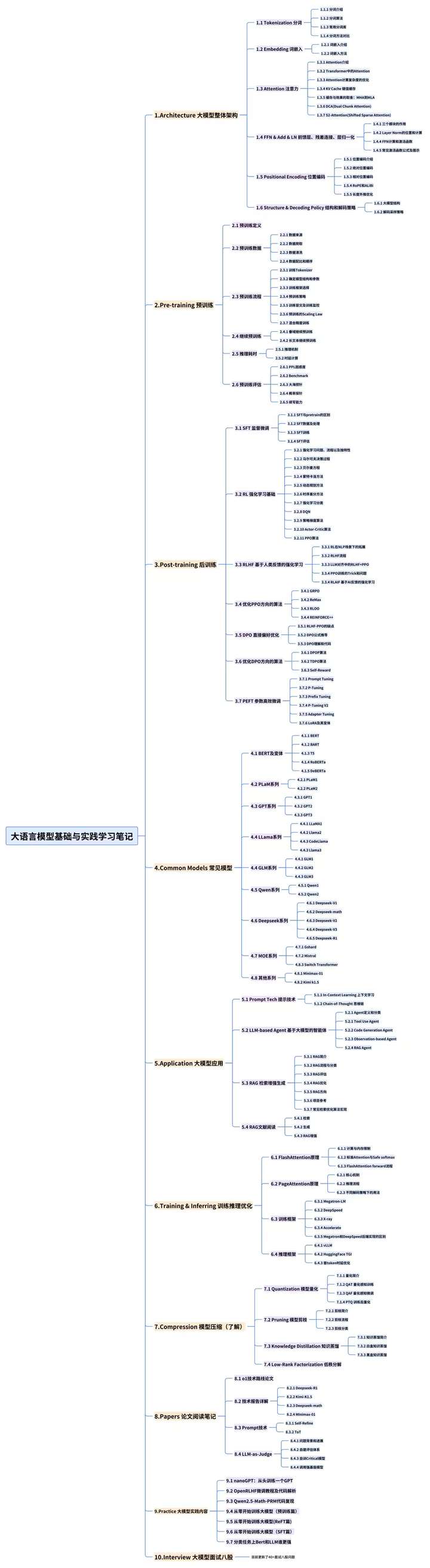
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。

👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

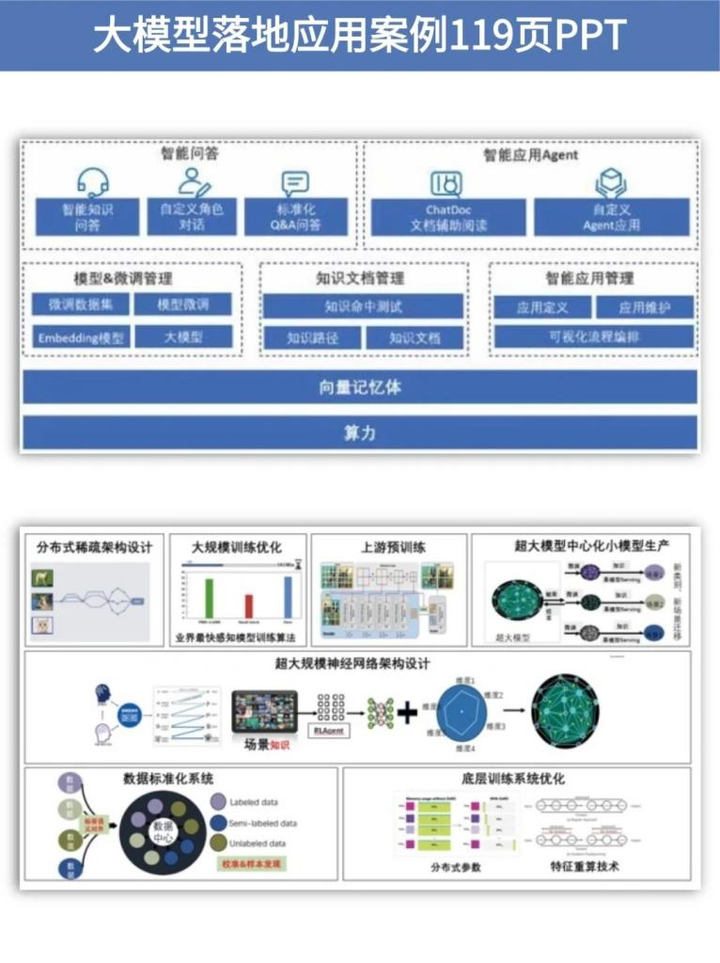
👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)
👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)

👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈 • 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以点击下方链接免费领取 【保证100%免费】

**读者福利 |** 👉2024最新《AGI大模型学习资源包》免费分享 **(安全链接,放心点击)**



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}