






在人工智能飞速发展的当下,大模型成为众人瞩目的焦点。今天,我们就基于复旦大学《大规模语言模型:从理论到实践》,深入探索大模型的奥秘。
一、大模型是什么?
大规模语言模型(LLM),是用包含数百亿以上参数的深度神经网络构建的语言模型,通常采用自监督学习方法,在大量无标注文本上进行训练。它就像一个知识渊博的学者,通过海量阅读(文本训练)积累知识,从而具备强大的语言处理能力。
二、大模型的发展历程
-
基础模型阶段(2018 - 2021年)
:这一时期,研究聚焦于语言模型本身,出现了仅编码器、编码器 - 解码器、仅解码器等架构,为后续发展奠定了基础。
-
能力探索阶段(2019 - 2022年)
:由于大模型难以针对特定任务微调,研究人员开始探索新途径。他们尝试在零样本或少量样本基础上,利用生成式框架对大量任务进行有监督微调,挖掘大模型的潜在能力。
-
突破发展阶段(2022年11月至今)
:ChatGPT的发布开启了新篇章。它凭借一个简单对话框,就能实现问题回答、文稿撰写、代码生成、数学解题等多种功能,让人们看到了大模型的巨大潜力。
三、大模型的建模流程
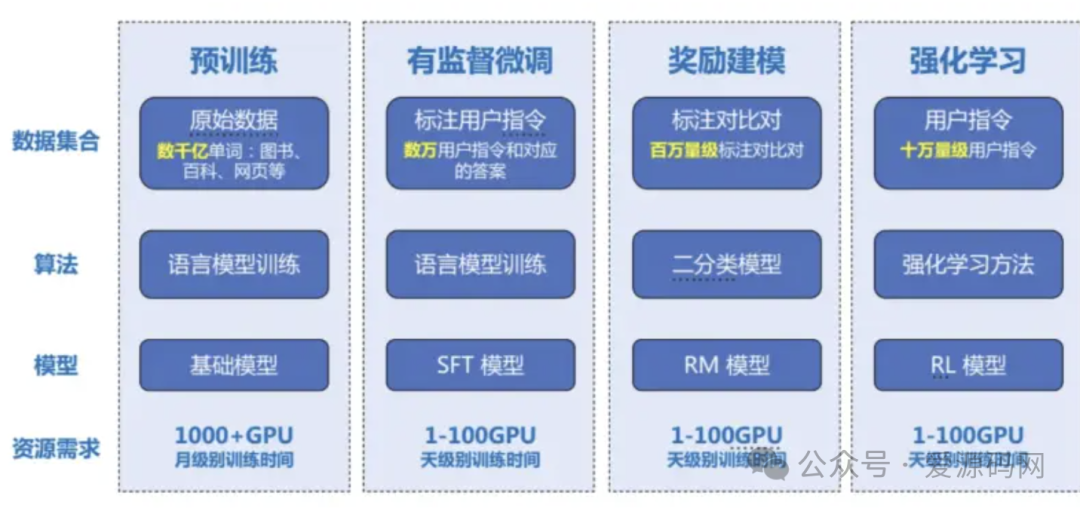
-
预训练
:使用海量原始数据(如图书、百科、网页等,包含数千亿单词),通过语言模型训练,让模型学习语言的统计规律和语义信息。
-
有监督微调
:利用百万量级标注对比对,对模型进行微调,使其更符合特定任务需求。
-
奖励建模
:通过标注用户指令(十万量级用户指令,数万用户指令和对应答案),训练二分类模型(RM模型),评估模型生成结果的优劣,为强化学习提供奖励信号。
-
强化学习
:基于奖励信号,使用强化学习方法(RL模型)进一步优化模型,提升模型性能。
四、核心模型——Transformer
Google提出的Transformer模型是大模型的核心。它由词元嵌入、位置编码、多层多头自注意力、位置感知前馈网络、残差连接和归一化等部分组成。
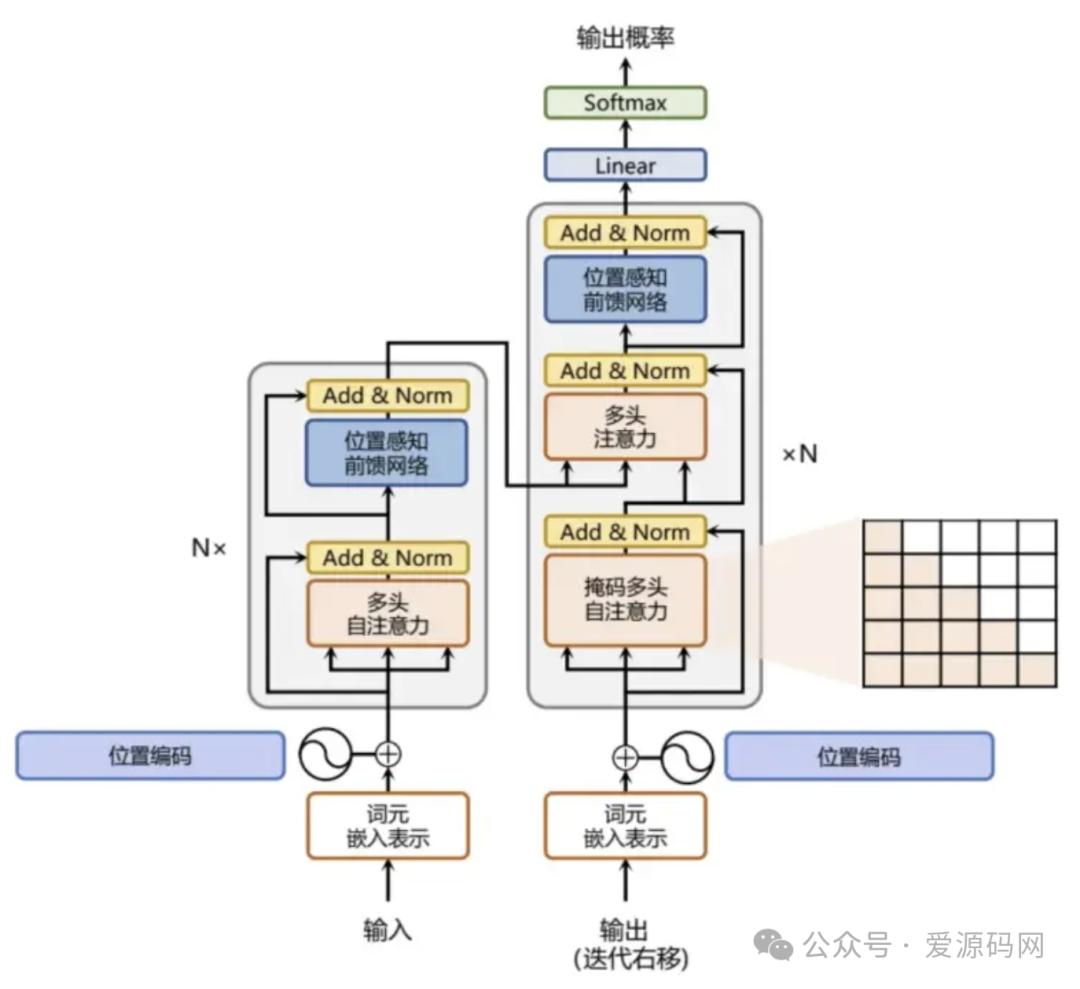
-
词元嵌入&位置编码
:将输入文本的每个单词转换为向量表示,并添加位置编码,让模型知晓单词的位置信息。
-
自注意力层
:把输入数据分为查询、键和数值,经过一系列运算,实现自注意力输出,使模型能关注文本不同部分的关联。
-
前馈层
:接受自注意力子层输出,通过带有Relu激活函数的两层全连接网络,进行复杂的非线性变换,提升翻译质量。
-
残差连接和层归一化
:残差连接避免梯度消失问题,层归一化消解数据差异,保证模型稳定训练。
-
解码层
:掩码多头注意力用于掩盖后续文本信息,防止模型在训练时“偷看”,确保训练有效。
五、生成式预训练语言模型GPT
-
无监督预训练
:将训练数据转换为向量位置数据,输入多层transformer层学习,输出数据,让模型掌握通用语言知识。
-
有监督的下游任务微调
:针对下游任务,使用带有标签的数据微调模型,但要注意避免灾难性遗忘问题。
六、基于huggingface的预训练语言模型实战
huggingface是开源的自然语言处理软件库,为开发人员和研究人员提供便利。下面以基于BERT模型的构建和使用为例:
-
构建步骤
-
-
数据集下载
:从dataset库下载预训练数据集,分割数据,10%用于测试。
-
训练词元分析器
:使用transformers库中的BertWordPieceTokenizer类训练,将文本转换为模型能理解的格式。
-
预训练语料集合
:分割超长预料,组合短小预料。
-
模型训练
:输入训练语料,评估测试语料。
-
模型使用
:对文本挖空,让模型预测。
-
-
代码示例
:(滑动查看完整代码)
1import json
2from datasets import concatenate_datasets, load_dataset, load_from_disk
3from tokenizers import BertWordPieceTokenizer
4from transformers import BertTokenizerFast
5from transformers import BertConfig, BertForMaskedLM, DataCollatorForLanguageModeling, TrainingArguments, Trainer
6# 1. 数据集合准备,此处需要单独准备,可能下载不下来,可以选择阿里的modelspace
7# 加载数据集
8#bookcorpus = load_dataset("bookcorpus", split="train")
9# 下载到本地 save_to_disk, 后面直接 load_from_disk就行
10#bookcorpus.save_to_disk("./bookcorpus")
11# 从本地加载数据
12bookcorpus = load_from_disk("./bookcorpus")
13dataset = concatenate_datasets([bookcorpus])
14# 90% 用于训练,10%用于测试
15d = dataset.train_test_split(test_size=0.1)
16# 将训练和测试数据分别保持在本地文件中
17"""print(t, file=f) writes the content of t to the file f.
18The print function automatically adds a newline after each item t,
19so each item from dataset["text"] will be on a new line in the output file."""
20def dataset_to_text(dataset, output_filename):
21 print(output_filename, "writing")
22 with open(output_filename, "w") as f:
23 for t in dataset["text"]:
24 print(t, file=f)
25 print(output_filename, "finish")
26# save the training set to train.txt and save the testing set to test.txt
27# dataset_to_text(d['train'], './train.txt')
28# dataset_to_text(d['test'], './test.txt')
29# 2. 训练词元分析器(Tokenizer)
30"""训练分词器的主要目的是将文本转换成BERT模型能够理解的格式,并生成input_ids和attention_mask。
31分词(Tokenization):将原始文本分解成词汇单元(tokens),比如单词、标点符号等。
32生成input_ids:将分词后的结果转换为词汇表中对应的索引(ID),因为模型是通过这些索引来理解文本的。
33生成attention_mask:因为处理的文本长度不一,我们通常会将所有文本填充(pad)到相同长度。attention_mask用于指示哪些位置是真实文本,哪些位置是填充的,以便模型在处理时能够区分。"""
34"""BERT 采用了 WordPiece 分词,根据训练语料中的词频决定是否将一个完整的词切分为多个词元。
35需要首先训练词元分析器(Tokenizer)。"""
36special_tokens = ["[PAD]", "[UNK]", "[CLS]", "[SEP]", "[MASK]", "<S>", "<T>"]
37# if you want to train the tokenizer on both sets
38# training the tokenizer on the trainiing set
39files = ['./train.txt']
40# 30,522 vocab is BERT's default vocab size, feel free to tweak
41vocab_size = 30_522
42# maximum sequence length, lowering will result to faster training (when increasing batch size)
43max_length = 512
44"""truncate_longer_samples 布尔变量来控制用于对数据集进行词元处理的 encode() 回调函数。
45如果设置为 True,则会截断超过最大序列长度(max_length)的句子。否则,不会截断。
46如果设置为 False,需要将没有截断的样本连接起来,并组合成固定长度的向量。"""
47truncate_longer_samples = False
48# initialize the WordPiece tokenizer
49tokenizer = BertWordPieceTokenizer()
50# train the tokenizer
51# tokenizer.train(files=files, vocab_size=vocab_size, special_tokens=special_tokens)
52# 启用截断功能,最多可截断 512 个标记
53tokenizer.enable_truncation(max_length=max_length)
54model_path = './pretrained-bert'
55# if not os.path.isdir(model_path):
56# os.mkdir(model_path)
57# tokenizer.save_model(model_path)
58# 将部分标记符配置转储到配置文件中,包括特殊标记、是否小写以及最大序列长度
59with open(os.path.join(model_path, "config.json"), 'w') as f:
60 tokenizer_cfg = {
61 "do_lower_case": True,
62 "unk_token": "[UNK]",
63 "sep_token": "[SEP]",
64 "pad_token": "[PAD]",
65 "cls_token": "[CLS]",
66 "mask_token": "[MASK]",
67 "model_max_length": max_length,
68 "max_len": max_length,
69 }
70 json.dump(tokenizer_cfg, f)
71# when the tokenizer is trained and configured, load it as BertTokenizerFast
72# 初始化分词器
73tokenizer = BertTokenizerFast.from_pretrained(model_path)
74# 3. 预处理语料集合
75# 使用预训练的分词器来编码文本
76"""在启动整个模型训练之前,还需要将预训练语料根据训练好的 Tokenizer 进行处理。
77如果文档长度超过512个词元(token),那么就直接进行截断。"""
78def encode_with_truncation(examples):
79 """Mapping function to tokenize the sentences pass with truncation"""
80 return tokenizer(examples["text"], truncation=True, padding="max_length",
81 max_length=max_length, return_special_tokens_mask=True)
82def encode_without_truncation(examples):
83 """Mapping function to tokenize the sentences pass without truncation"""
84 return tokenizer(examples["text"], return_special_tokens_mask=True)
85"""在使用 Hugging Face 的 datasets 库处理数据集以准备用于 PyTorch 训练时,您可能需要执行一些额外的步骤来优化数据集格式。
86具体来说,如果您想移除非必要列并将 input_ids 和 attention_mask 设置为 PyTorch 张量(tensors),
87可以通过使用数据集的 .map() 方法来应用转换函数,然后使用 .set_format() 方法来指定输出格式。"""
88# the encode function will depend on the truncate_longer_samples variable
89encode = encode_with_truncation if truncate_longer_samples else encode_without_truncation
90# tokenizing the train dataset, test dataset。map: 对数据集应用encode函数,批量处理
91train_dataset = d["train"].map(encode, batched=True)
92test_dataset = d["test"].map(encode, batched=True)
93if truncate_longer_samples:
94 # 移除其他列之后,将input_ids和attention_mask 设置为 PyTorch 张量
95 train_dataset.set_format(type="torch", columns=["input_ids", "attention_mask"])
96 test_dataset.set_format(type="torch", columns=["input_ids", "attention_mask"])
97else:
98 # 移除其他列之后,直接将需要的列保留为Python列表
99 train_dataset.set_format(columns=["input_ids", "attention_mask", "special_tokens_mask"])
100 test_dataset.set_format(columns=["input_ids", "attention_mask", "special_tokens_mask"])
101from itertools import chain
102# 主要数据处理函数,用于连接数据集中的所有文本, 并生成长度为 max_seq_length 的数据块。
103def group_texts(examples):
104 # concatentate all texts
105 concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
106 total_length = len(concatenated_examples[list(examples.keys())[0]])
107 # 如果模型支持,我们可以添加衬垫,而不是填充,您可以根据自己的需要定制这一部分。
108 if total_length >= max_length:
109 total_length = (total_length // max_length) * max_length
110 # Split by chunks of max_len.
111 result = {
112 k: [t[i : i + max_length] for i in range(0, total_length, max_length)]
113 for k, t in concatenated_examples.items()
114 }
115 return result
116# 请注意,在 `batched=True` 的情况下,这个映射会同时处理 1,000 个文本,因此 group_texts 会为每组 1,000 个文本丢弃一个余数。
117# 可以在此调整 batch_size,但如果数值越大,预处理速度可能越慢。
118if not truncate_longer_samples:
119 train_dataset = train_dataset.map(group_texts, batched=True,
120 desc=f"Grouping texts in chunks of {max_length}")
121 test_dataset = test_dataset.map(group_texts, batched=True,
122 desc=f"Grouping texts in chunks of {max_length}")
123 # convert them from lists to torch tensors
124 train_dataset.set_format("torch")
125 test_dataset.set_format("torch")
126# 4. 模型训练
127# 在构建了处理好的预训练语料之后,就可以开始训练模型
128# 使用配置初始化模型
129model_config = BertConfig(vocab_size=vocab_size, max_position_embeddings=max_length)
130# 在MLM任务中,模型的目标是预测输入句子中被随机遮蔽掉的单词。这是 BERT 训练过程的一部分,有助于模型学习语言的深层次理解。
131model = BertForMaskedLM(config=model_config)
132# 初始化数据整理器,随机屏蔽 20%(默认为 15%)的标记,用于屏蔽语言建模 (MLM) 任务
133data_collator = DataCollatorForLanguageModeling(
134 tokenizer=tokenizer, mlm=True, mlm_probability=0.2
135)
136training_args = TrainingArguments(
137 output_dir=model_path,
138 evaluation_strategy="steps", # evaluate each 'logging_steps'
139 overwrite_output_dir=True,
140 num_train_epochs=10, # number of training epochs, feel free to tweak
141 per_device_train_batch_size=10, # the training batch size, put it as high as your GPU memory fits
142 gradient_accumulation_steps=8, # accumulating the gradients before updating the weights
143 per_gpu_eval_batch_size=64, # evaluate batch size
144 logging_steps=1000, # evaluate, log and save model checkpoints every 1000 step
145 save_steps=1000,
146 # load_best_model_at_end=True, # whether to load the best model (in terms of loss) at the end of training
147 # save_total_limit=3, # whether you don't have much space so you let only 3 model weights saved in the disk
148)
149trainer = Trainer(
150 model=model,
151 args=training_args,
152 data_collator=data_collator,
153 train_dataset=train_dataset,
154 eval_dataset=test_dataset,
155)
156# train the model
157trainer.train()
158# 5. 模型使用
159from transformers import pipeline
160# load the model checkpoint
161model = BertForMaskedLM.from_pretrained(os.path.join(model_path, "checkpoint-10000"))
162# load the tokenizer
163tokenizer = BertTokenizerFast.from_pretrained(model_path)
164# 已经完成了 BERT 模型的训练。使用 fill-mask 管道进行预测
165fill_mask = pipeline("fill-mask", model=model, tokenizer=tokenizer)
166# perform predictions
167examples = [
168 "Today's most trending hashtags on [MASK] is Donald Trump",
169 "The [MASK] was cloudy yesterday, but today it's rainy.",
170]
171for example in examples:
172 predictions = fill_mask(example)
173 print(f"Input: {example}")
174 for prediction in predictions:
175 print(f"{prediction['sequence']}, confidence: {prediction['score']}")
176 print("="*50)
七、Transformer模型实际使用下的变更
以llama模型为例,在实际应用中Transformer模型有不少变更:
-
前置层归一化
:使用RMSNorm函数,将层归一化位置调整,第一个层归一化移到多头自注意力层之前,第二个移到全连接层之前,残差连接位置也相应调整。
-
激活函数变更
:采用SwiGLU激活函数,性能更优。
-
相对位置编码
:使用旋转位置嵌入(RoPE)代替绝对位置编码,借助复数思想实现相对位置编码。
ction[‘score’]}“)
176 print(”="*50)
七、Transformer模型实际使用下的变更
以llama模型为例,在实际应用中Transformer模型有不少变更:
-
前置层归一化
:使用RMSNorm函数,将层归一化位置调整,第一个层归一化移到多头自注意力层之前,第二个移到全连接层之前,残差连接位置也相应调整。
-
激活函数变更
:采用SwiGLU激活函数,性能更优。
-
相对位置编码
:使用旋转位置嵌入(RoPE)代替绝对位置编码,借助复数思想实现相对位置编码。
大模型的世界博大精深,今天我们只是揭开了冰山一角。希望这篇文章能让大家对大模型基础理论与实践有初步了解,在人工智能的浪潮中,一起探索更多可能!如果大家有什么想法或疑问,欢迎在留言区交流。
大模型风口已至:月薪30K+的AI岗正在批量诞生
2025年大模型应用呈现爆发式增长,根据工信部最新数据:
国内大模型相关岗位缺口达47万
初级工程师平均薪资28K(数据来源:BOSS直聘报告)
70%企业存在"能用模型不会调优"的痛点
真实案例:某二本机械专业学员,通过4个月系统学习,成功拿到某AI医疗公司大模型优化岗offer,薪资直接翻3倍!
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
相信大家在刚刚开始学习的过程中总会有写摸不着方向,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程等免费分享出来。
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
😝有需要的小伙伴,可以微信扫码领取!

👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先有一个明确的学习路线,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(完整路线在公众号内领取)

大模型学习路线
👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

大模型教程
👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

电子书
👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,需要的扫描下方二维码领取 **




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











