






读者福利:关注公众号【大模型应用开发LLM】可获取入门大模型学习资料包一份~
大家好,上篇给大家分享了如何本地部署目前最强开源LLM应用平台dify v1.0.0,本来这期是准备分享dify的知识库搭建的。
但是即便dify已经升级到1.0完全体了,它的知识库问答效果还是一坨,,,
以下是我个人使用dify知识库之后的感受:

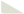
1.即便使用最新的父子分段后效果仍不理想;
2.配置有点繁琐,在知识库创建流程中已经设定了重排模型,到应用关联知识库的时候还要设定一次;
3.dify的知识库也支持fastgpt的问答拆分模式,但是这个拆分速度非常慢,还容易出错;
4.使用问答拆分之后的回复也是一坨,,,

说真的,dify除了知识库以外,其他大部分功能体验都比fastgpt要好。
有时候我真的有点恨铁不成钢。
而fastgpt的知识库效果是公认的好(以下是某群 群友的评价~)
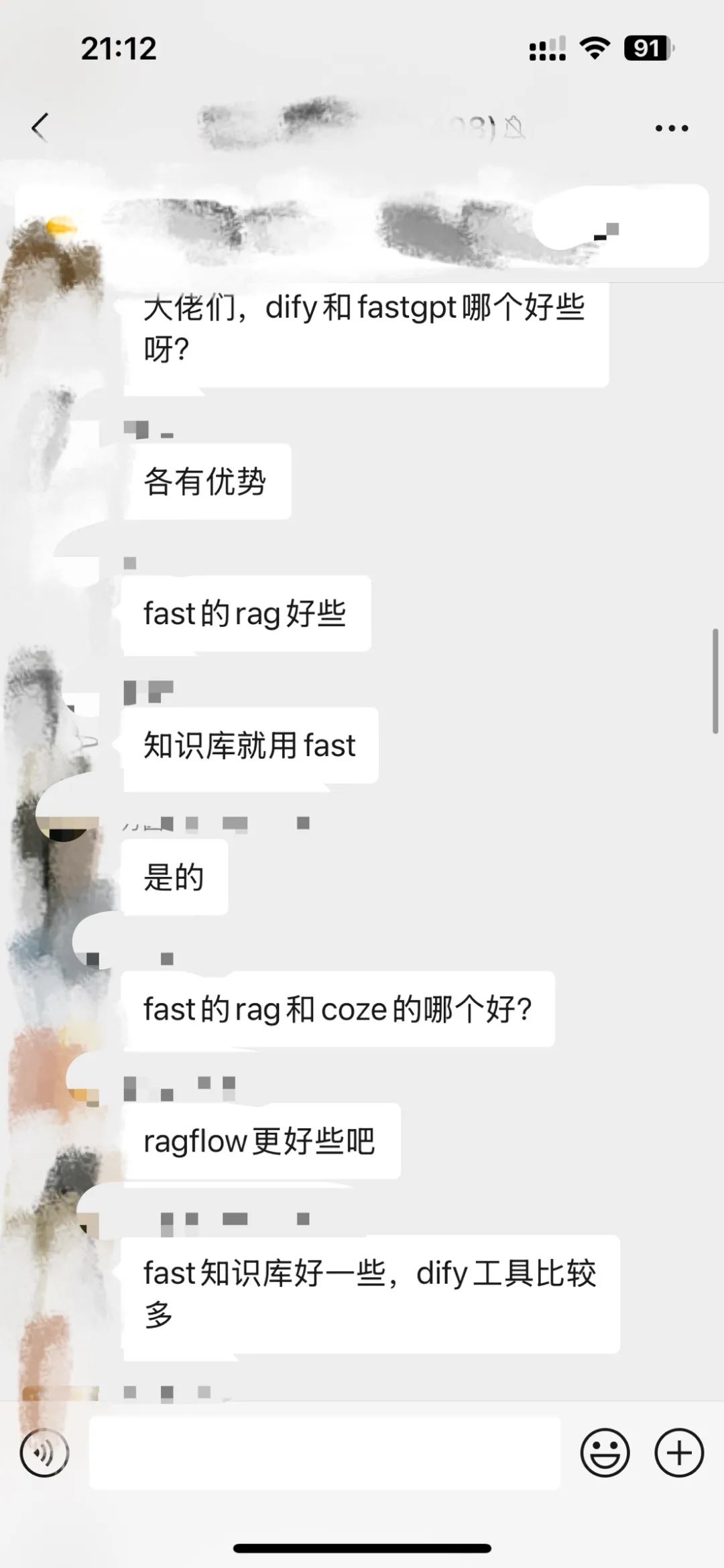
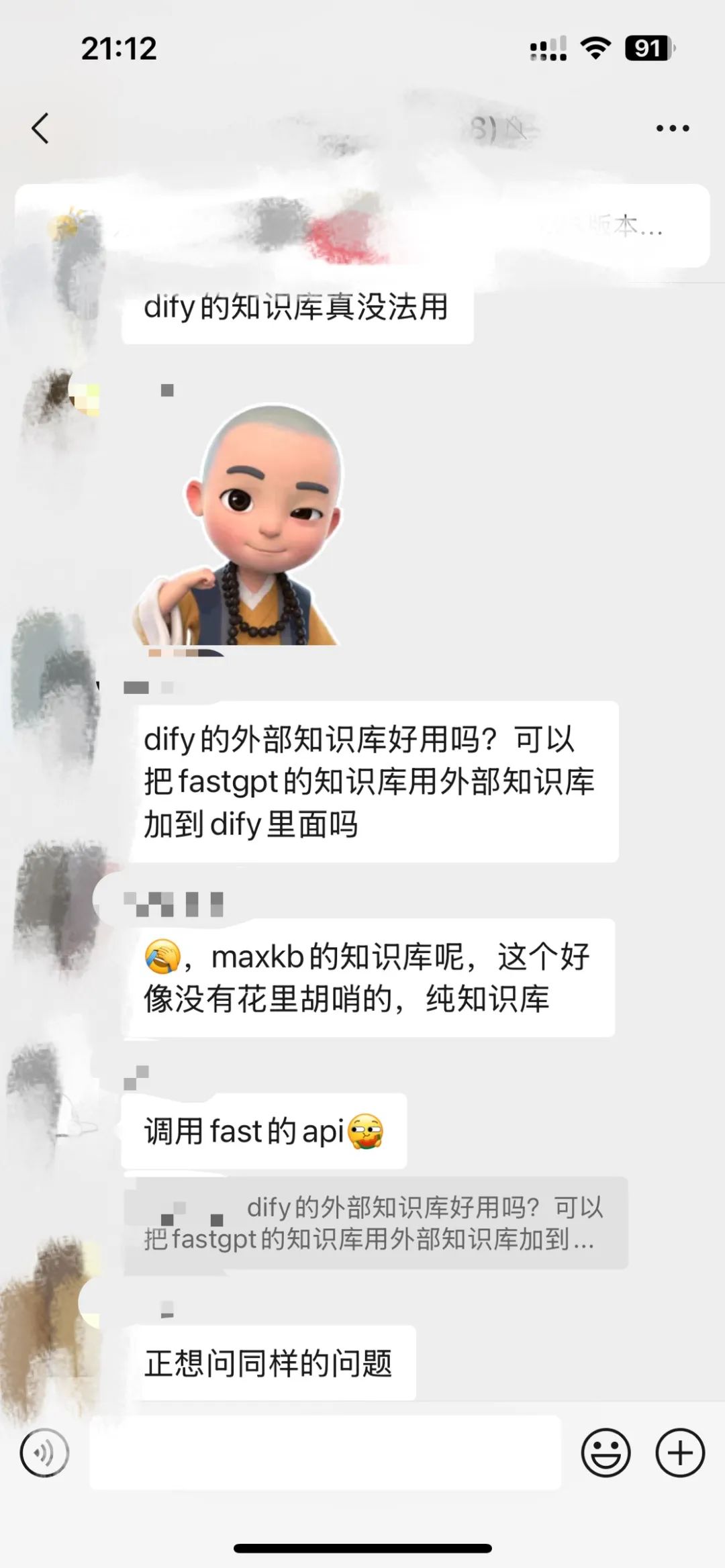

所以,过去一年我大部分时间都在用fastgpt,毕竟知识库才是根本。
不过我想:如果能把dify和fastgpt结合,且不妙哉?
dify提供了外部知识库API,我知道,这事儿绝对能成!
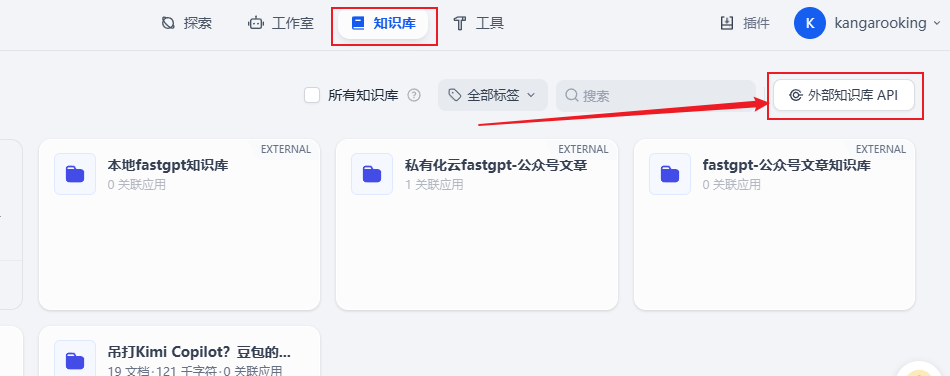
dify的外部知识库功能,支持添加外部知识库使用。
而fastgpt的知识库又刚好支持API调用。
那咱们可以直接把fastgpt知识库接入dify使用呀~
但是两边API接口不适配,,,是个问题。
遇到问题,我一般都会先找找有没有现成的方案(毕竟重复造轮子不是明智之举)
经过我的一番AI搜索,引擎搜索,各种查找,还真没找到现成的方案可以直接把fastgpt的知识库接入dify
PS:如果您有其他方案,欢迎评论区分享~
那么,就由我自己来创造"完美"!(造个轮子)
我用字节最新发布的AI编程工具Trae,花了30分钟左右,快速的完成了一个小项目,作为dify和fastgpt知识库的桥梁,可以快速、方便的把fastgpt的知识库外接到dify使用。
你可以把这个项目看做一个适配器。
姑且就给这个项目起名fda(fastgpt-dify-adapter)
看下dify外接fastgpt知识库前后的回复对比(左边是接入前,右边是接入后)
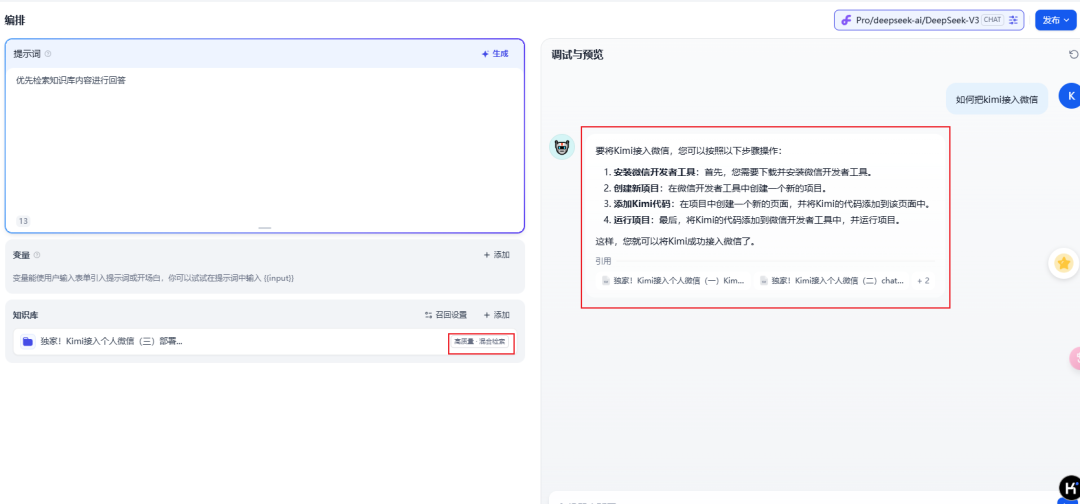
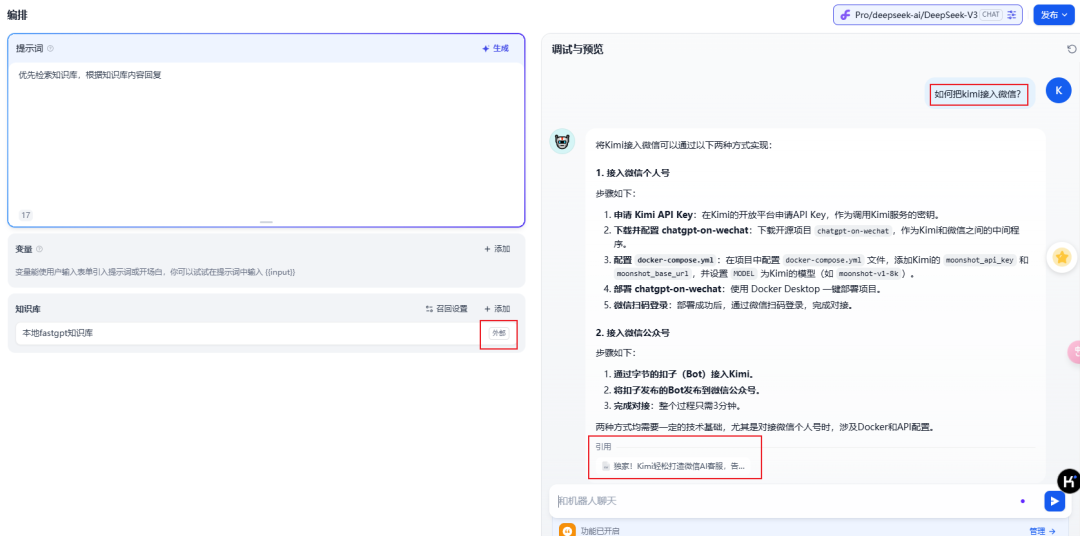

这个对比,两边所配置的参数,索引方式,索引模型,问答模型,以及知识库所上传的资料都一样。
但是dify的原始回复效果,我看了直接想报警!
完全跟我文章里面的内容不沾边,,,
整个接入过程简单分为3步:

1.配置、部署fda;
2.在fastgpt创建open apikey,复制知识库id;
3.在dify外接fastgpt知识库;
介绍差不多了,我们直接开始喂饭~

一、部署fda(fastgpt-dify-adapter)

fda(fastgpt-dify-adapter)使用python语言开发,支持docker-compose一键启动。
目前已经放到github


**地址:**https://github.com/kangarooking/fastgpt-dify-adapter


本篇教程使用的是本地部署的fastgpt和本地部署的dify来完成对接
PS:dify和fastgpt都有云端版本,懒得本地部署的朋友也可以通过云端版本测试。
同样,fda也是本地部署(系统:win10)
咱们不需要去下载fda的源码,直接创建一个fda的docker-compose.yml配置文件即可。
先随便新建一个文件夹,在文件夹下新建一个.txt文件,把如下内容复制到.txt文件中(一定要保持yml格式,不能乱)
version: '3'services: fastgpt-dify-adapter: image: registry.cn-guangzhou.aliyuncs.com/kangarooking/fastgpt-dify-adapter:1.0.1 ports: - "5000:5000" environment: - FASTGPT_BASE_URL=http://host.docker.internal:3000 # 问题优化配置 - DATASET_SEARCH_USING_EXTENSION=false - DATASET_SEARCH_EXTENSION_MODEL=deepseek-chat - DATASET_SEARCH_EXTENSION_BG= # 重排序配置 - DATASET_SEARCH_USING_RERANK=false restart: unless-stopped
ps:本次镜像也特别帮大家上传到了阿里云,这样不需要科学上网就能快速下载镜像啦
.txt文件保存之后,将文件名连着后缀一起修改为docker-compose.yml
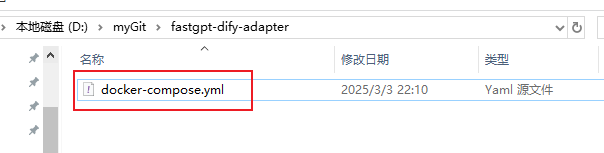
FASTGPT_BASE_URL:配置fastgpt地址(如果fastgpt和fda部署在同一个服务器的docker中,fastgpt地址建议直接使用 http://host.docker.internal:3000)
问题优化 和 重排序配置对应fastgpt的什么配置呢?
我放两个图你就懂了
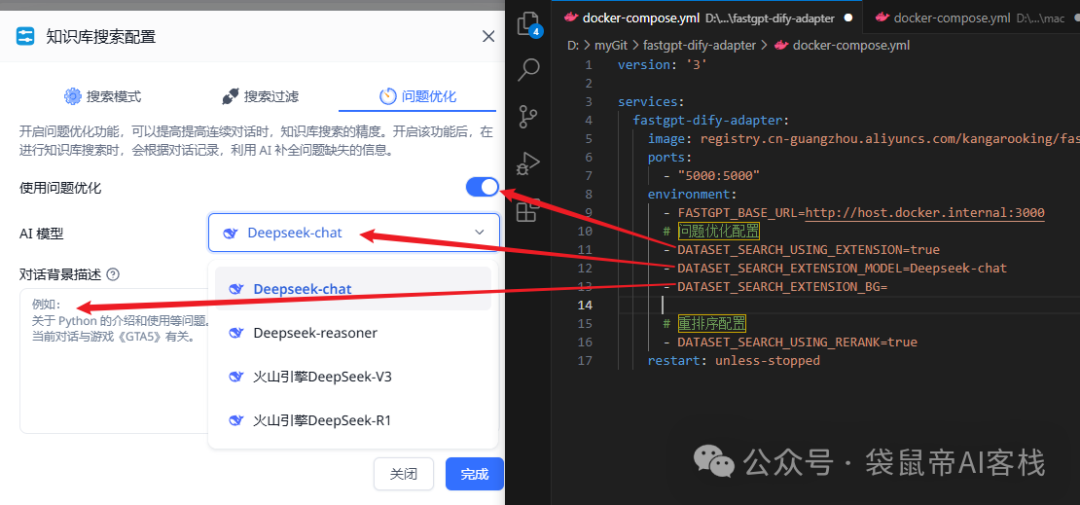
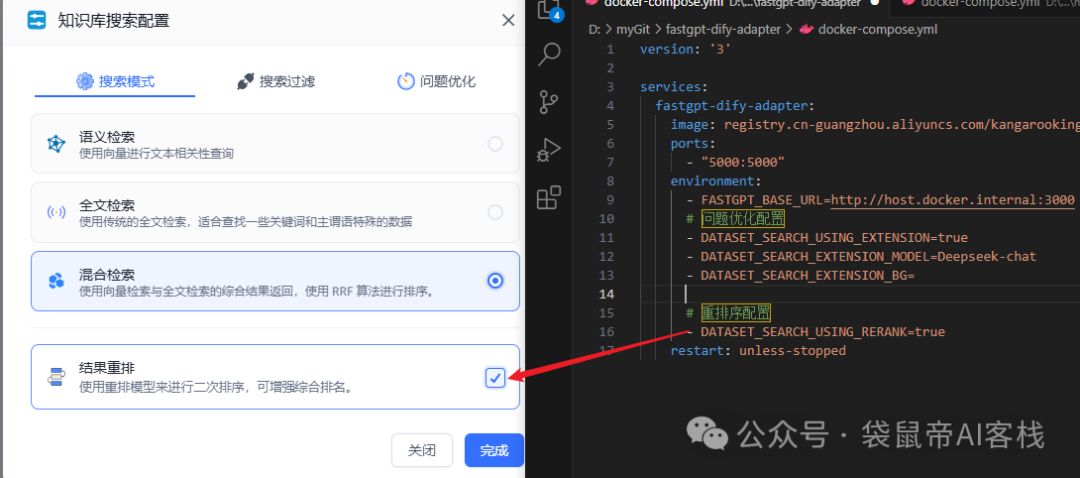
docker-compose.yml文件配置好之后
在docker-compose.yml文件所在目录的地址栏输入cmd 回车,进入控制台。

控制台输入指令docker-compose up -d ,然后 回车(就自动下载、部署fda了)
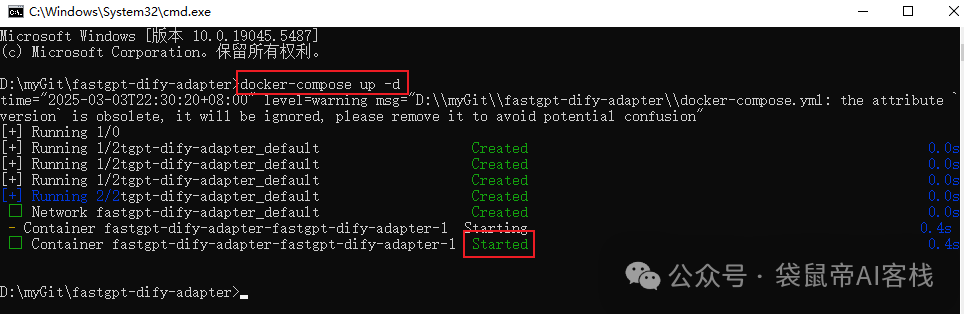
**如上图部署成功之后,可以打开docker-desktop,找到*Containers->fda->view details*查看fda的日志
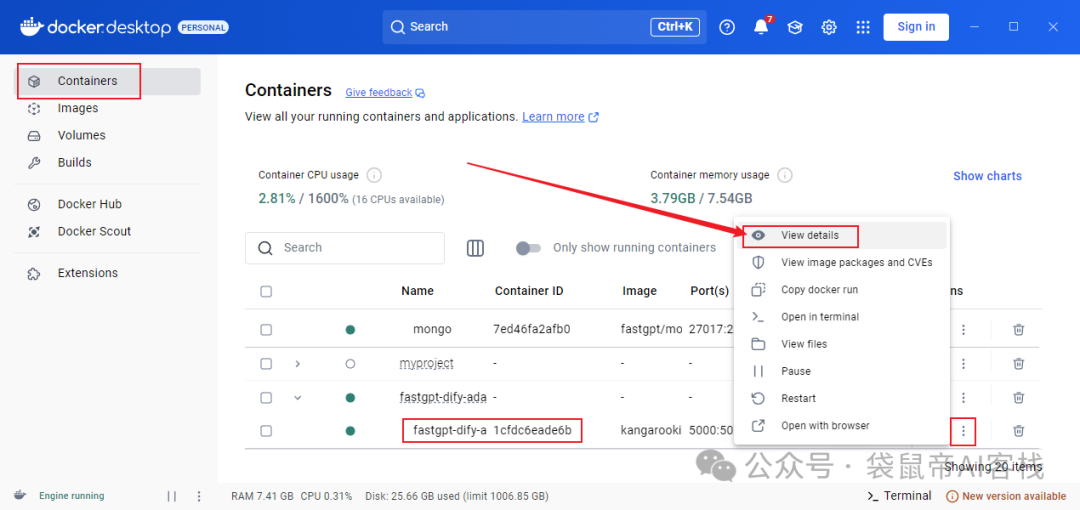

二、获取fastgpt相关参数

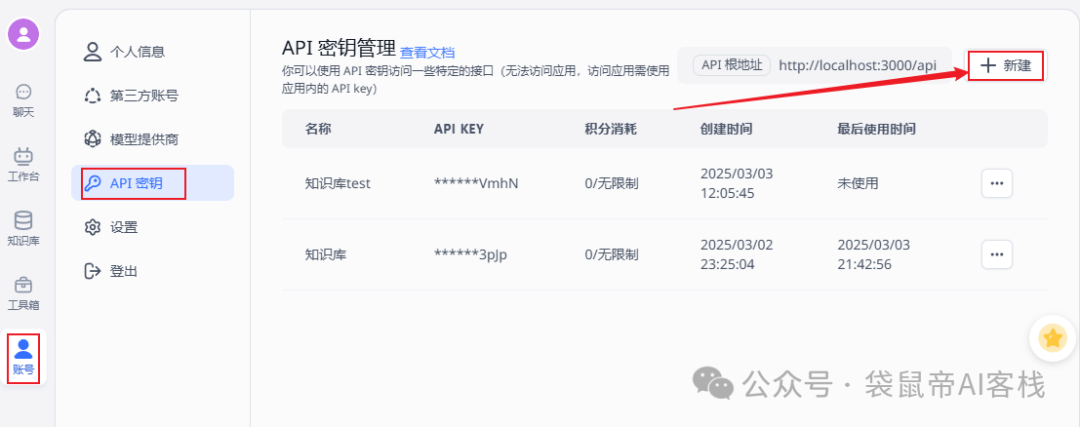
我们需要获取fastgpt的openapi key
创建openapi key之后 需要复制下来备用
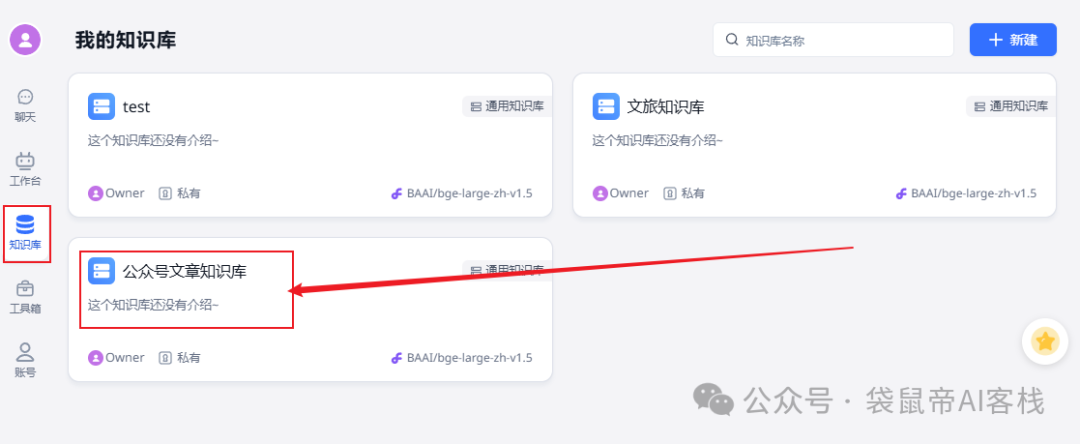
找到你想要接入dify的知识库,点进去
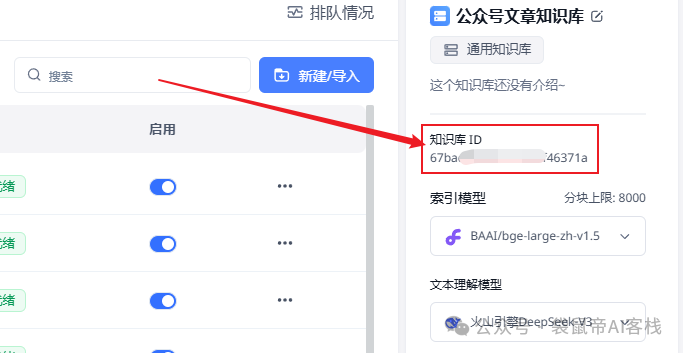
在最右边找到知识库id,复制下来备用

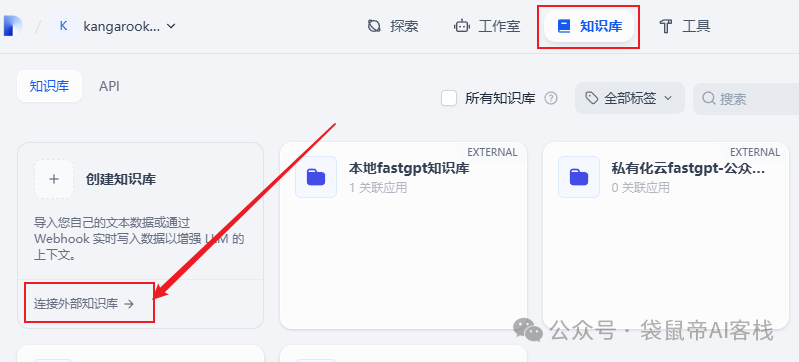
三、dify外接fastgpt知识库

访问dify,知识库->外部知识库API->添加外部知识库API
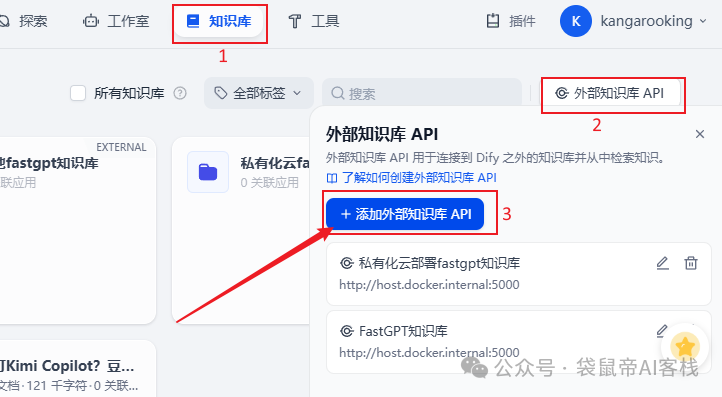
API Endpoint填写fda的地址+端口(如有)
PS:如果dify和fda也是部署在同一服务器的docker中,fda的地址直接用:http://host.docker.internal:5000
API key填写刚刚复制的fastgpt openapi key
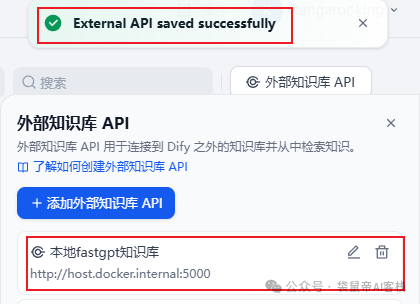
让后保存。

如下图就保存成功了
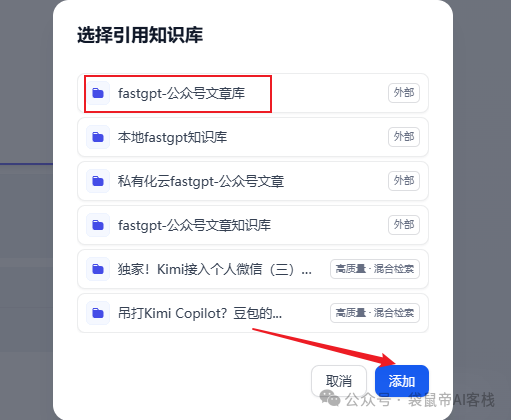
然后我们创建一个外部知识库
注意填写刚刚复制的fastgpt知识库id
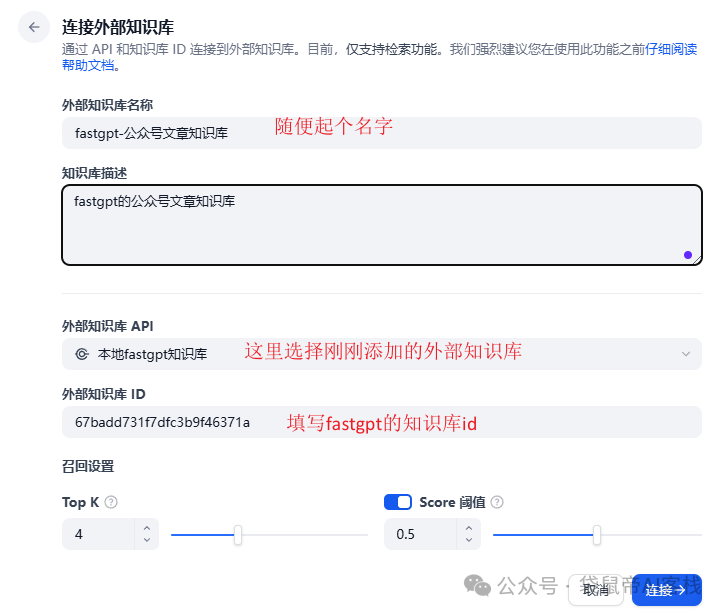
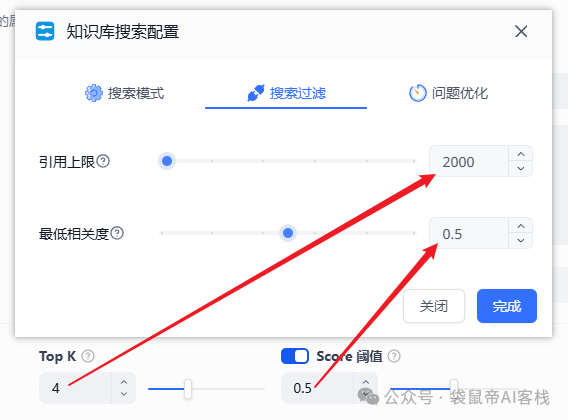
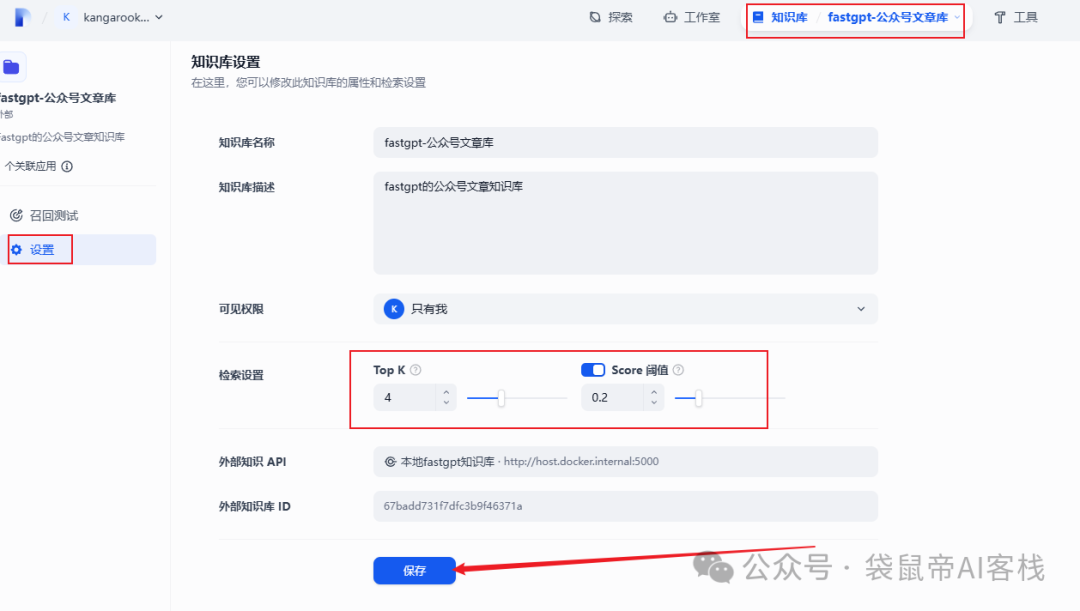
Top K 和 Score对应fastgpt哪里的配置,我放个图你就明白了
Top K为4=fastgpt的引用上限2000(如果是5就对应2500,以此类推)
Score=fastgpt的最低相关度
建议 Top K拉到6以上,可以提供更多的长下文
配置好之后,点击连接
最后,随便进入一个dify应用,点击添加知识库
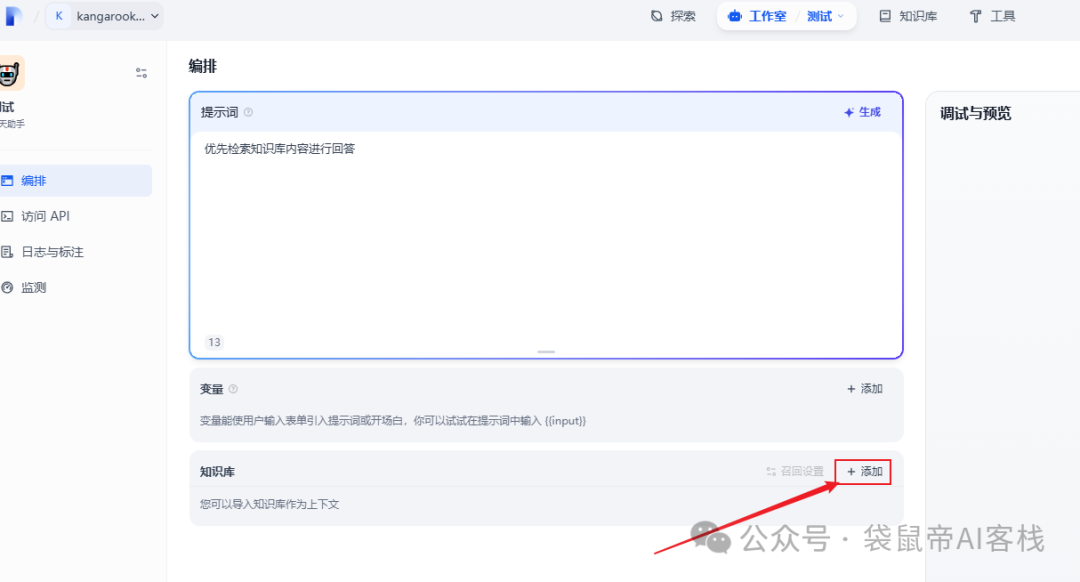
选择刚刚创建的外部库,添加
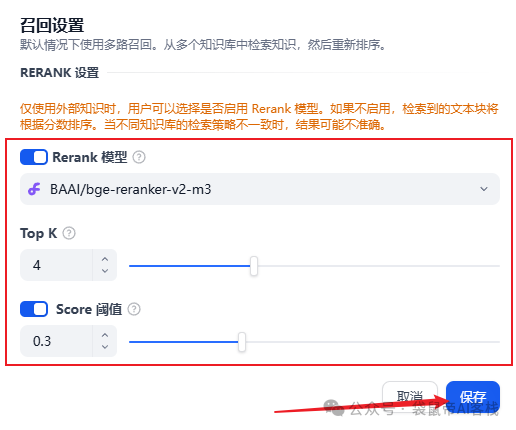
会弹出设置(这里的设置经我测试不起作用,不用管),直接保存
到这一步,我们就可以在dify里面愉快的使用fastgpt知识库来进行问答回复啦~ 效果提升不止一点点!
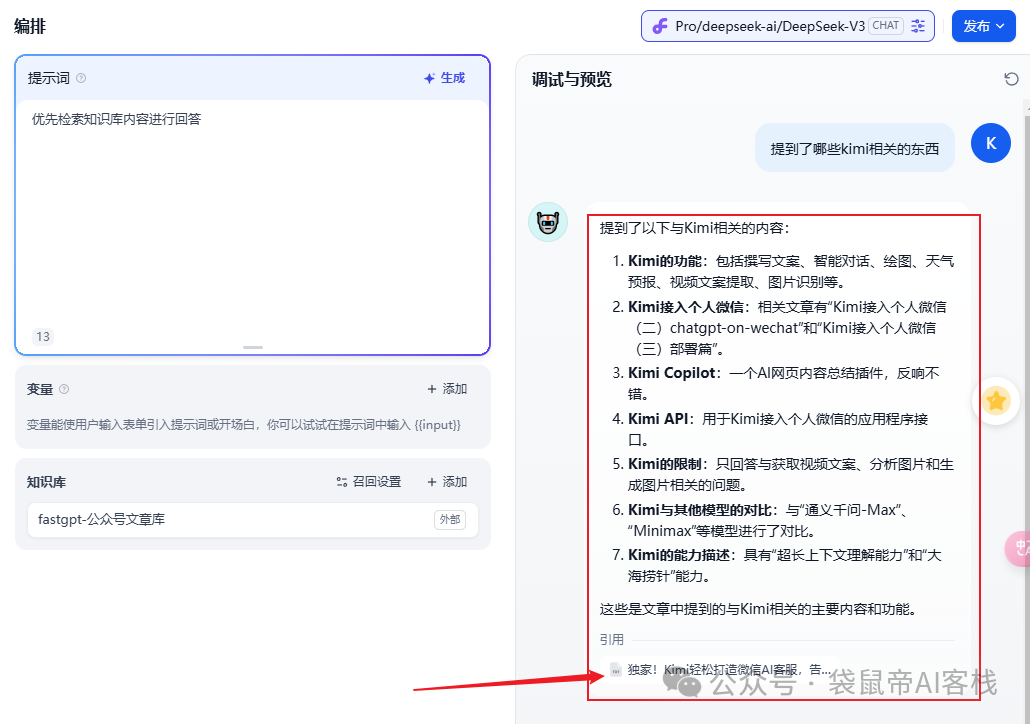
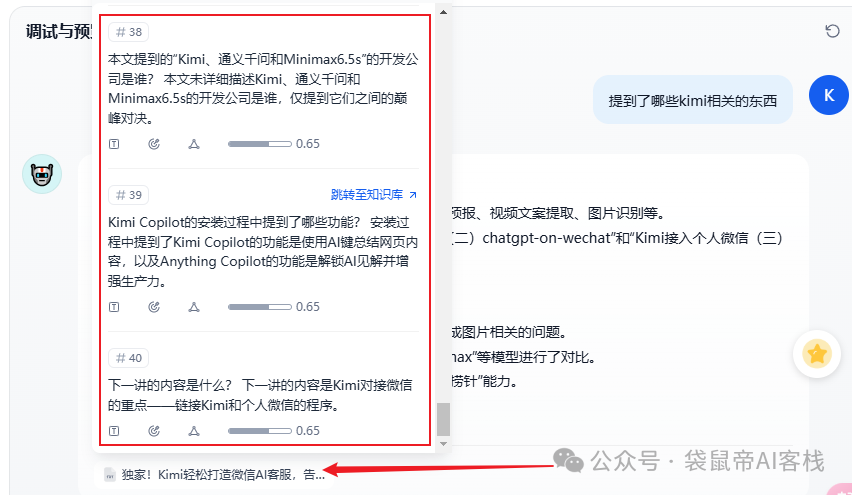
点击引用,还可以看到所有的引用内容
如果后续想调整外部知识库的参数,可以到外部知识库->设置里面调整
至此
pg3YF5-1746157384223)]
到这一步,我们就可以在dify里面愉快的使用fastgpt知识库来进行问答回复啦~ 效果提升不止一点点!
[外链图片转存中…(img-qPPEDX6I-1746157384223)]
点击引用,还可以看到所有的引用内容
[外链图片转存中…(img-gnyPJOA6-1746157384223)]
如果后续想调整外部知识库的参数,可以到外部知识库->设置里面调整
[外链图片转存中…(img-kauMM8cC-1746157384223)]
至此
外接fastgpt知识库的dify才算是世界上最好用的开源LLM应用平台!
如何学习AI大模型?
大模型的发展是当前人工智能时代科技进步的必然趋势,我们只有主动拥抱这种变化,紧跟数字化、智能化潮流,才能确保我们在激烈的竞争中立于不败之地。
那么,我们应该如何学习AI大模型?
对于零基础或者是自学者来说,学习AI大模型确实可能会感到无从下手,这时候一份完整的、系统的大模型学习路线图显得尤为重要。
它可以极大地帮助你规划学习过程、明确学习目标和步骤,从而更高效地掌握所需的知识和技能。
这里就给大家免费分享一份 2025最新版全套大模型学习路线图,路线图包括了四个等级,带大家快速高效的从基础到高级!




如果大家想领取完整的学习路线及大模型学习资料包,可以扫下方二维码获取

👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

大模型教程
👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

电子书
👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,需要的扫描下方二维码领取 **



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











