






今日,中国首个AI原生集成开发环境(AI IDE)Trae 国内版正式上线,配置Doubao-1.5-pro,并支持切换满血版DeepSeek R1、V3模型,让编程速度起飞。
作为更贴合中国开发者开发习惯与开发场景的AI IDE,Trae 以动态协作为核心,打造了一种人机协同,人与AI互相增强的全新开发体验,助力开发者高效应对复杂技术挑战,释放创新潜能。
人与 AI 默契协作,全新开发体验
AI技术的快速发展,让开发方式面临着巨大的变革,开发者亟需更高效率、更智能化的工具支持。Trae 应需而发,定位为 “智能协作AI IDE ” ,以“人机协同、互相增强”为核心理念,对代码补全 ,代码理解,Bug修复,基于自然语言生成代码等开发过程全场景都有非常好的适应性,不仅是一个开发工具,更是一位全天候开发“拍档”。
而基于人与AI协作开发的理念,无论是人还是AI,Trae 让恰当的对象,在恰当的时间接管工作,确保每一个代码片段都是人与AI共创的最优结果,为开发者带来更加高效、优质的开发体验。
更快,更好,更准确
Trae 为开发者打造了前所未有的开发体验,帮助开发者更快速,更准确,更高质量的完成开发需求。
全新 Builder 模式能充分利用AI的能力,无论是初学者还是资深的开发者,都能够轻松通过自然语言描述迅速的,端到端的生成应用:只需要用简单的语言描述需求,Trae 就可以迅速搭建起项目框架,还能持续进行调优修改,产出可用代码。这种智能化的"思想到代码"直通车能力,全程助力开发者将需求端到端完美落地,极大缩短了项目筹备周期,为高效开发奠定坚实基础。
在代码理解维度,Trae 的能力边界实现了质的突破,凭借对开发项目上下文的极致理解,深入剖析代码仓库,实时获取IDE中的各种环境上下文,精准洞察开发者的需求,从而为开发过程提供最为契合、准确的解决方法。
针对需求沟通效率问题,Trae 的实时代码续写技术可基于开发项目整体上下文进行智能补全,提升编码效率,而在交互体验方面,开发者可以便捷地将 AI 生成的代码一键应用到多个模块,还能根据实际需求随时灵活调整指令,并实时预览 AI 生成代码的前端效果。
在通往AI Coding 的 AGI 时代里,有众多 AI 辅助编程工具出现,但Trae 希望成为更可靠的、值得开发者信赖的“AI 工程师” (The Real AI Engineer ): 通过真正的 AI 编程 Agent, 帮助开发者实现「从需求到落地」的端到端全链路开发闭环。Trae 相信,一个好的“AI 工程师”,不仅是一个好用的工具,更是一个多面手AI合作伙伴,可以更好的帮助开发者解决多种问题,让其有精力去重新构想价值创造的方式,触摸创造力的天花板。
即刻体验畅快编程
Trae 国内版不仅针对中国开发场景和习惯进行了一些优化,后续还即将支持模型自定义,用户可以根据自己的喜好,接入合适的大模型API,希望给开发者带来全新的AI IDE 开发体验。
即刻访问官网trae.com.cn,下载安装包,和我们一起,解锁AI驱动的开发新未来~
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
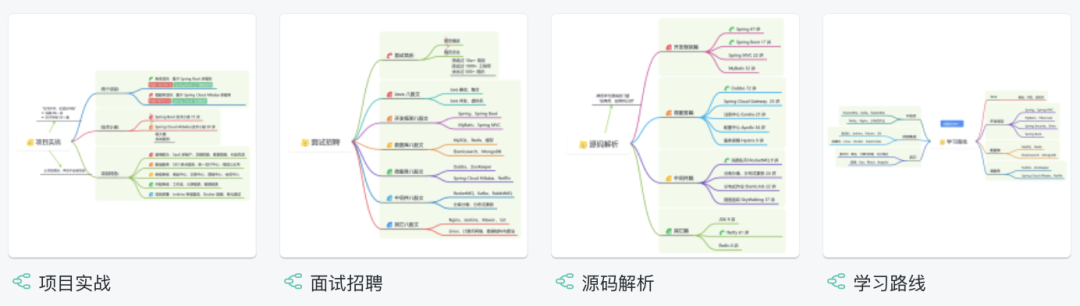
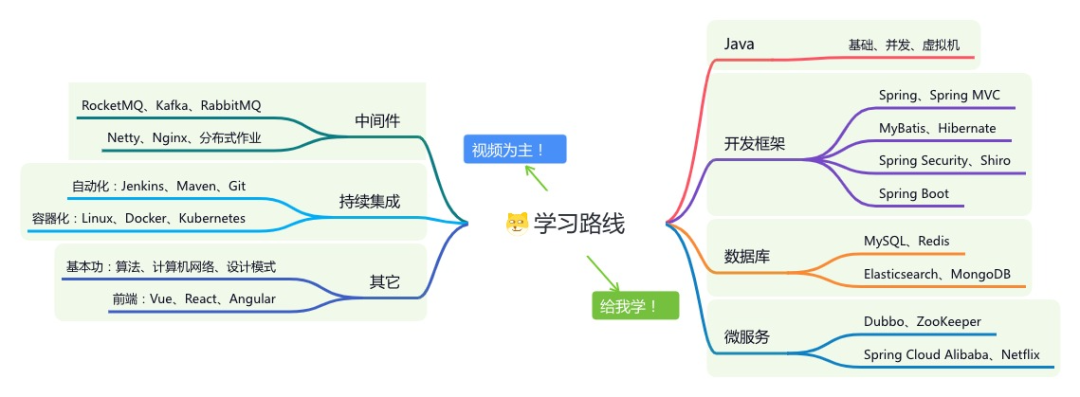
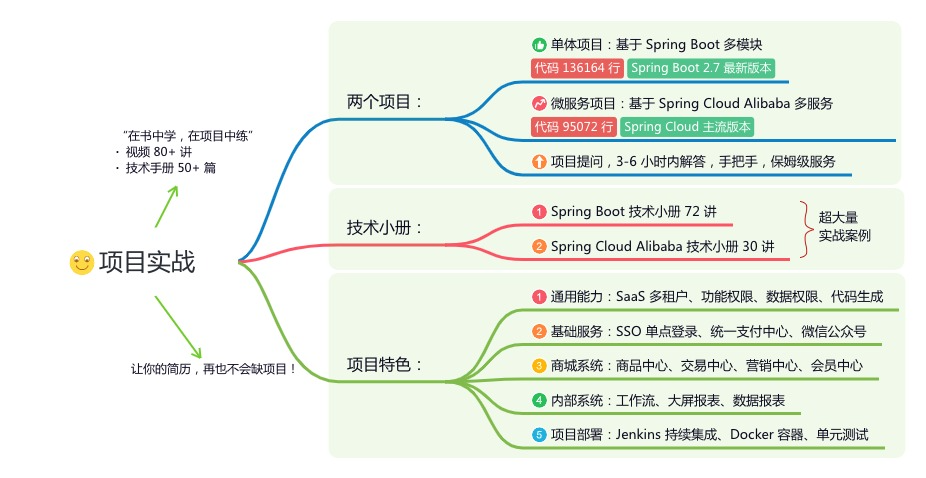
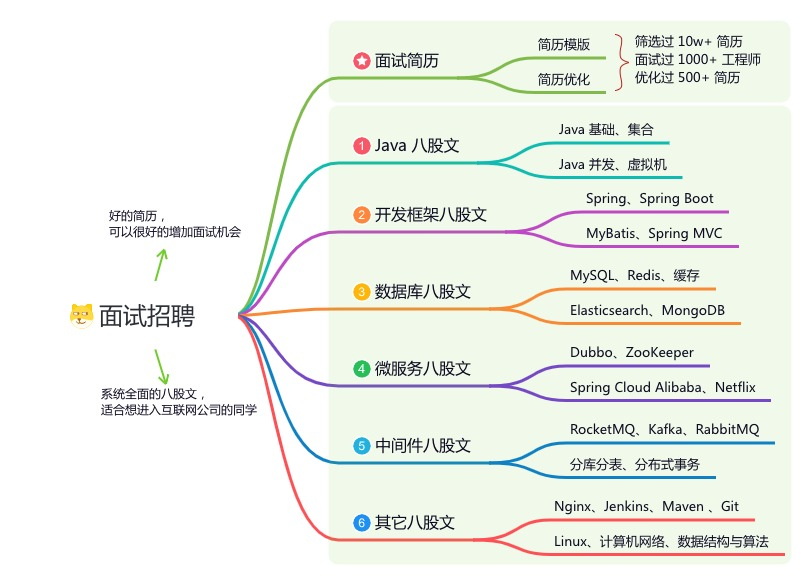
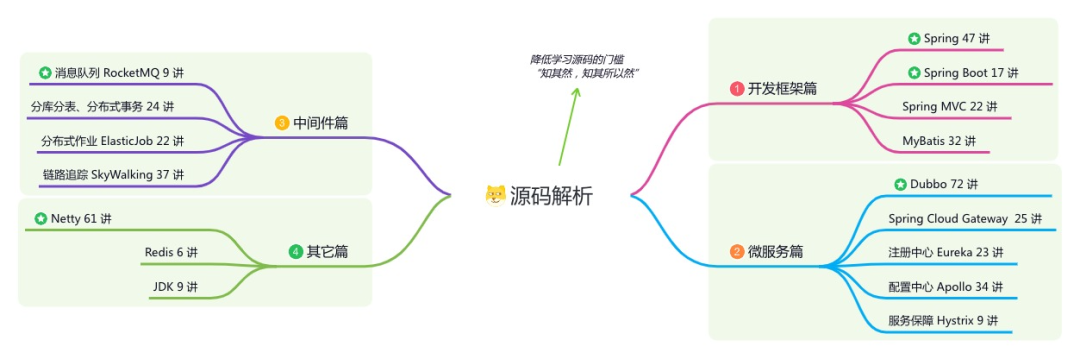
内容包括:项目实战、面试招聘、源码解析、学习路线。
如果大家想领取完整的学习路线及大模型学习资料包,可以扫下方二维码获取

👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

大模型教程
👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

电子书
👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,**有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
**或扫描下方二维码领取 **



















 773
773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











