








AI科技圈近一周又发生了啥新鲜事?一起看看吧~
2024图灵奖授予强化学习奠基人Richard Sutton与导师Andrew Barto
强化学习领域的先驱Andrew Barto和Richard Sutton荣获2024年ACM图灵奖。两人自1980年代起提出强化学习的主要思想,构建了其数学基础,并开发了重要算法。他们合著的经典教材《Reinforcement Learning: An Introduction》被引用超7.9万次。强化学习是当今AI突破的关键,从AlphaGo到ChatGPT,其应用广泛且深远。此次获奖不仅是对他们学术贡献的认可,也凸显了强化学习在现代AI发展中的核心地位

https://x.com/TheOfficialACM/status/1897225672935735579
阿里开源QwQ-32B推理模型,320亿参数性能媲美6710亿参数的DeepSeek-R1
阿里巴巴凌晨开源发布了全新推理模型QwQ-32B,其参数量为320亿,但性能足以比肩6710亿参数的DeepSeek-R1满血版。该模型基于Qwen2.5-32B,通过大规模强化学习(RL)显著提升了数学和编程任务的推理能力,甚至在多个基准测试中超越了DeepSeek-R1。QwQ-32B已开源至Hugging Face和ModelScope,并支持本地部署工具Ollama。阿里团队表示,强化学习为模型性能提升提供了新思路,未来将继续探索其在长时推理中的应用
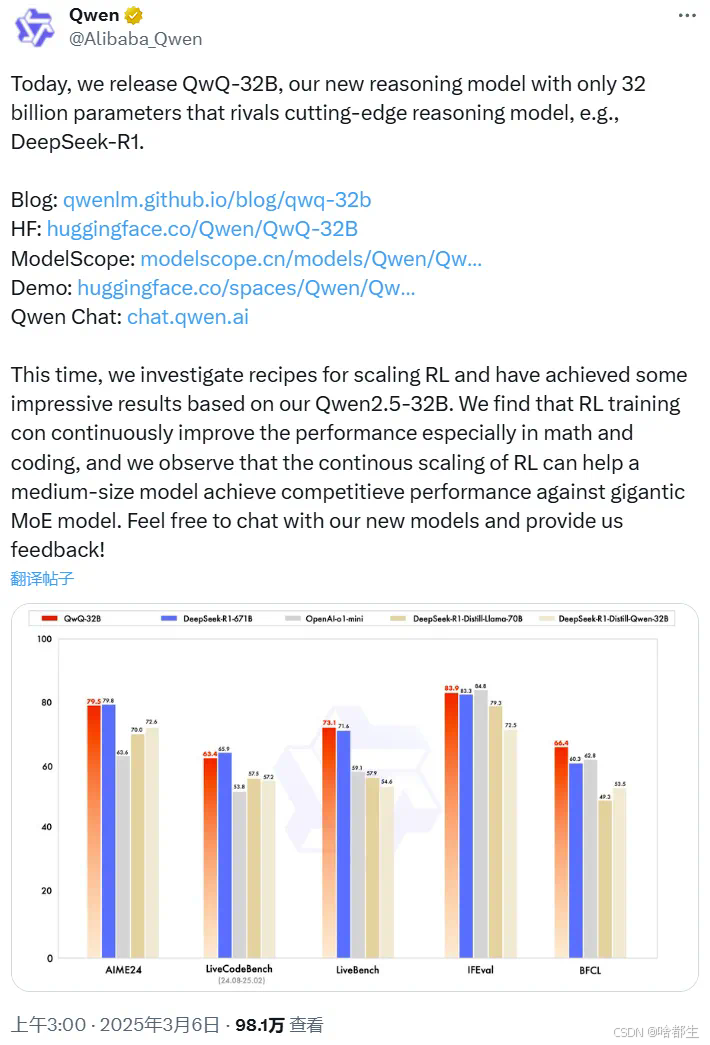
https://qwenlm.github.io/zh/blog/qwq-32b/
Monica.im 发布全球首款 AI Agent 产品 Manus
Monica.im 推出的 AI Agent 产品 Manus 于 2025 年 3 月 6 日正式发布,凭借其强大的自主任务执行能力和多代理架构,迅速在 AI 圈引发轰动。Manus 不仅能提供答案,还能直接交付完整的任务成果,如旅行规划、股票分析、教育内容创建等。其在 GAIA 基准测试中取得最先进表现,并采用多代理架构,通过规划、执行和验证代理的分工协作,大幅提升任务处理效率

https://mp.weixin.qq.com/s/BkAKuHEZT0Ysh2_VxIhAkw
拉里·佩奇成立AI创业公司,目标颠覆制造业
谷歌联合创始人拉里·佩奇成立了名为Dynatomics的AI创业公司,专注于利用大语言模型(LLM)为物体创建高度优化的设计,并推动其在工厂制造中的应用。该公司由曾是飞行汽车公司Kittyhawk首席技术官的Chris Anderson经营。佩奇的这一举措显示出AI在智能制造领域的巨大潜力,也反映了硅谷对AI技术未来发展的持续看好。与此同时,谷歌另一位联合创始人谢尔盖·布林也在积极参与谷歌大语言模型Gemini的研发,显示出谷歌在AI领域的深度布局
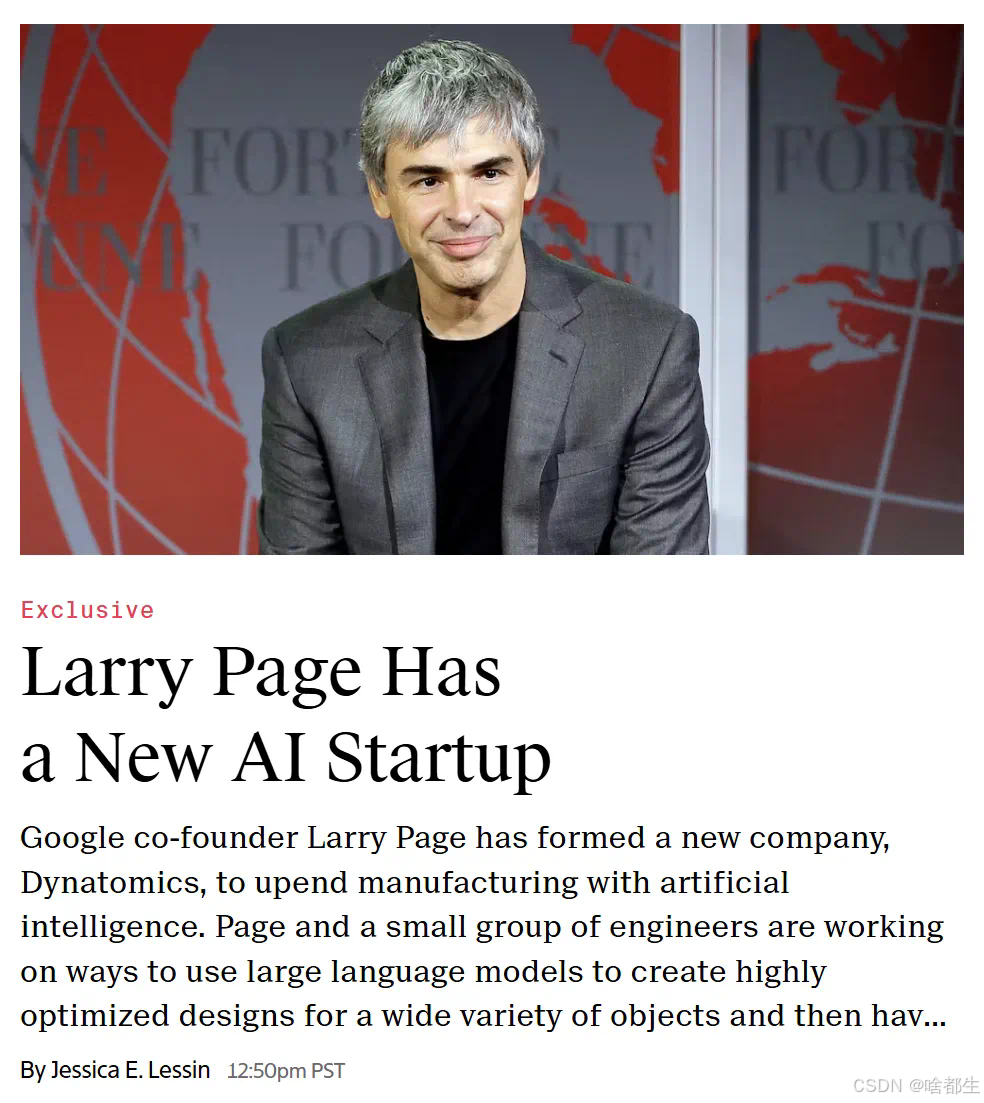
https://www.theinformation.com/articles/larry-page-has-a-new-ai-startup
南大周志华团队斩获AAAI 2025杰出论文奖
AAAI 2025会议于2月25日至3月4日在美国费城举办,会议共收到12957篇有效投稿,录取率为23.4%。在此次会议上,南京大学周志华团队凭借论文《Efficient Rectification of Neuro-Symbolic Reasoning Inconsistencies by Abductive Reflection》获得杰出论文奖。该研究提出了一种基于溯因学习的框架,用于改进神经符号AI系统的推理一致性,实验结果表明其在效率和准确性上均优于当前的SOTA方法。此外,多伦多大学和波尔多大学等机构的研究者也获得了杰出论文奖,斯坦福大学等机构的研究则获得了“AI对社会影响特别奖”

https://mp.weixin.qq.com/s/NXtoKX7Tq5B6n5O8ij_SBw
DeepSeek R1技术成功迁移到多模态领域,视觉强化微调项目Visual-RFT全面开源
视觉强化微调(Visual-RFT)项目成功将DeepSeek-R1背后的强化学习方法从纯文本大语言模型拓展到视觉语言大模型,通过设计针对视觉任务的规则奖励,实现了少样本学习和更强的泛化能力。在开放词汇、少样本学习等设定下,Visual-RFT仅用少量数据就取得了显著性能提升,尤其在推理定位等任务中展现出强大的视觉推理能力。项目基于QWen2-VL 2B/7B模型进行实验,全面超越传统监督微调方法,并已全面开源
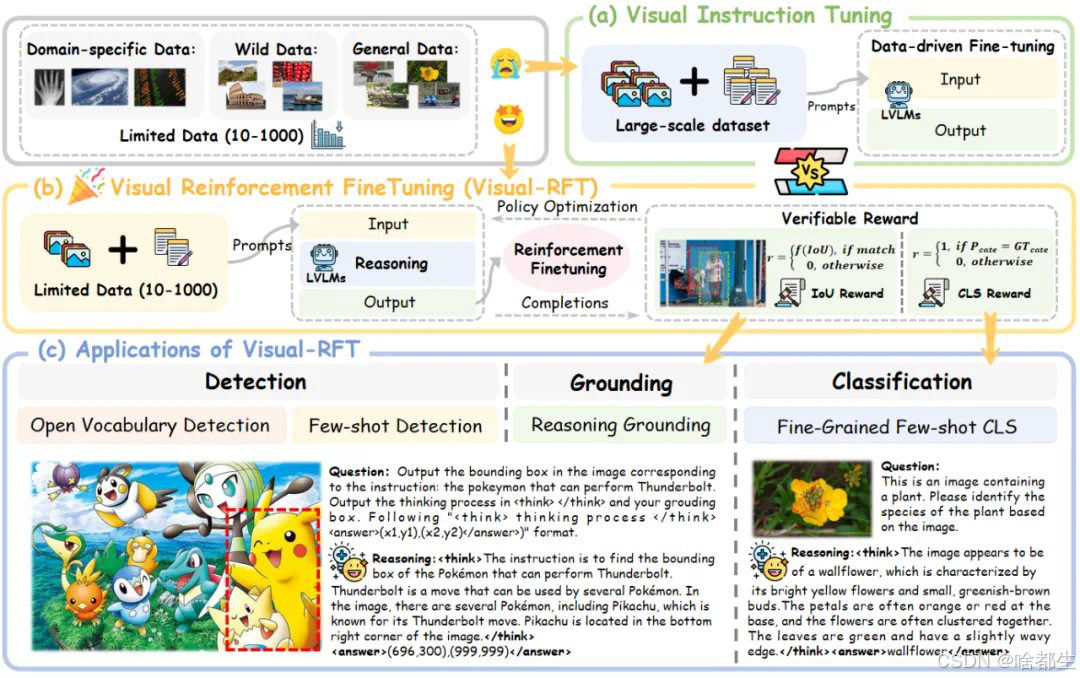
https://github.com/Liuziyu77/Visual-RFT
北京大学彭宇新教授团队开源多轮交互式商品检索模型及数据集
北京大学彭宇新教授团队在多轮交互式商品检索领域取得重要进展,其最新研究成果MAI模型及相关数据集FashionMT已开源,并被ICLR 2025接收。该研究针对现有方法在历史上下文缺失和数据规模受限的问题,提出了多轮聚合-迭代模型(MAI),通过两阶段语义聚合(TSA)和循环组合损失(CCL)优化多模态语义对齐,并设计无参数多轮迭代优化机制(MIO)压缩历史信息冗余。实验表明,MAI在新基准FashionMT上平均召回率提升8%,显著优于现有方法,为电商场景中的动态需求检索提供了更高效的技术支持
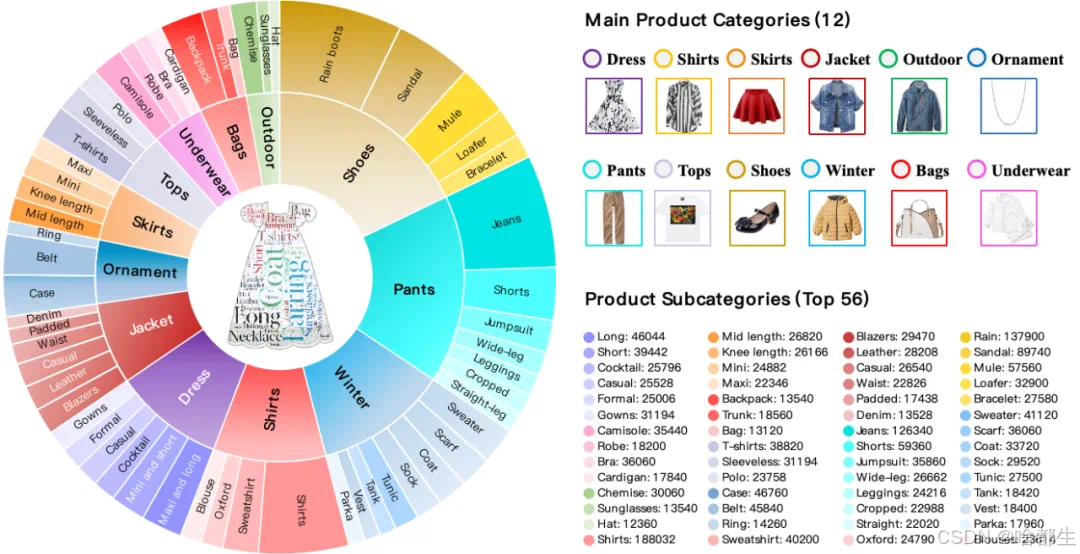
https://github.com/PKU-ICST-MIPL/MAI_ICLR2025
字节跳动发布国内首个AI原生IDE Trae国内版
字节跳动推出AI编程工具Trae国内版,这是国内首个AI原生集成开发环境(IDE)。该工具搭载doubao-1.5-pro模型,支持切换至满血版DeepSeek R1&V3,能够帮助开发者快速生成代码框架,提升开发效率。例如,开发者只需用自然语言输入需求,Trae即可生成包含前端页面和数据库连接的基础代码。此外,Trae的原生AI能力使其在上下文感知和全场景处理方面表现出色,确保代码自动补全和Bug修复等操作更加高效。Trae国内版还针对国内开发场景进行了优化,并计划支持模型自定义功能

trae.com.cn
智源开源多模态向量模型BGE-VL,多模态检索性能取得新突破
智源研究院联合多所高校开发的多模态向量模型BGE-VL正式开源,该模型在图文检索和组合图像检索等任务中表现出色,刷新了多项基准记录。BGE-VL基于大规模合成数据集MegaPairs训练而成,该数据集通过自动化方法生成高质量多模态三元组数据,仅需传统人工标注数据量的1/70即可实现更优的训练效果。BGE-VL模型在多个主流多模态检索基准测试中显著提升了性能,例如在组合图像检索评测集CIRCO上,BGE-VL-MLLM较之前的最佳模型提升了8.1个百分点。此外,该模型还具备优异的可扩展性,随着数据规模的增加,性能持续提升。智源研究院表示,未来将继续探索该模型在更多多模态检索场景中的应用
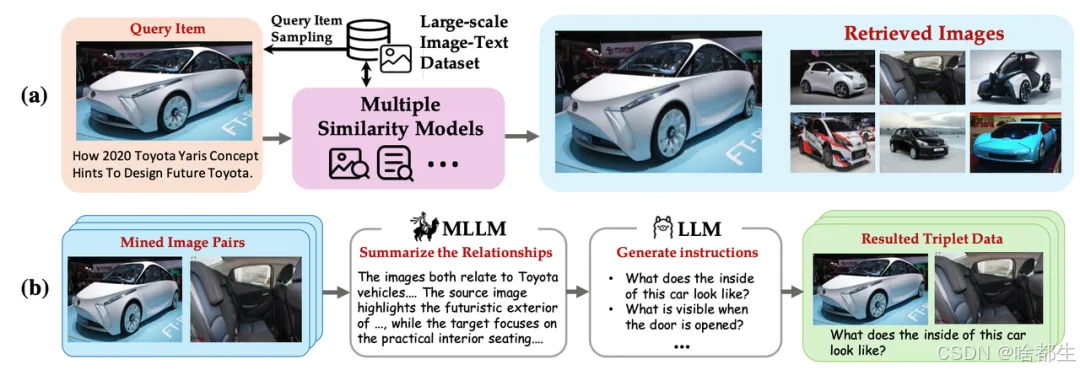
https://github.com/VectorSpaceLab/MegaPairs
图像生成模型CogView4发布并开源,支持中英双语及任意分辨率
智谱技术团队近日发布了最新的图像生成模型CogView4,并宣布开源。该模型具备强大的复杂语义对齐和指令跟随能力,支持任意长度的中英双语输入以及任意分辨率图像生成。在DPG-Bench基准测试中,CogView4-6B综合评分排名第一,达到开源文生图模型的SOTA水平。此外,CogView4采用多阶段训练策略,优化了文本和图像的训练框架,极大地提升了创作自由度。模型遵循Apache 2.0协议开源,相关仓库地址已公布,将于3月13日上线智谱清言平台
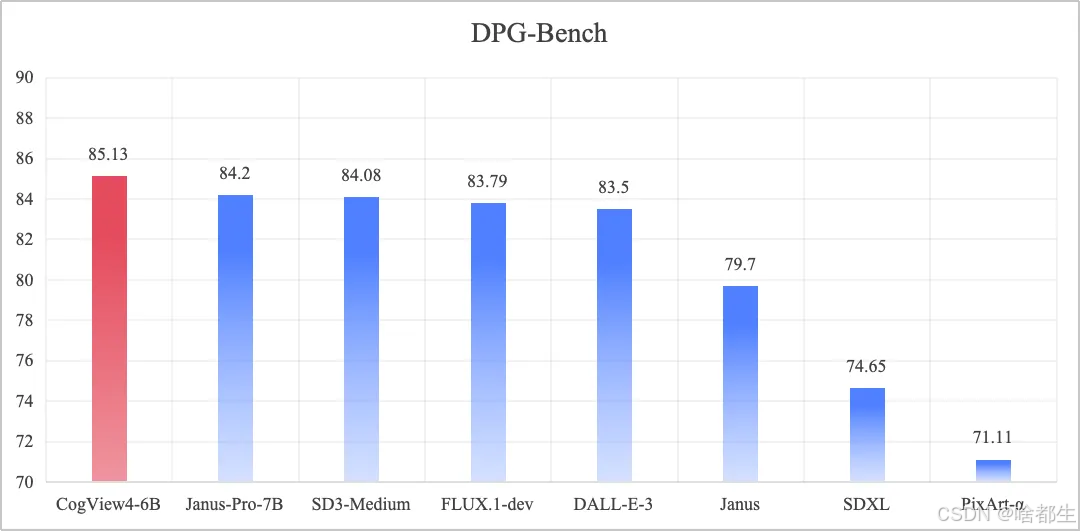
https://github.com/THUDM/CogView4
OpenAI投入3.6亿元,联合15家顶级机构成立NextGenAI教育联盟
OpenAI宣布成立NextGenAI教育联盟,联合包括哈佛、麻省理工、牛津等在内的15家顶尖大学和机构,承诺提供5000万美元(约合人民币3.6亿元)的研究补助金、计算资金和API访问权限。该联盟旨在利用AI加速研究突破并推动教育变革,涵盖医疗、农业、制造业等多个领域。例如,哈佛大学与波士顿儿童医院将利用AI缩短罕见病诊断时间,得克萨斯农工大学则通过该计划推动生成式AI素养培训。OpenAI希望通过这一合作,进一步加强学术界与工业界的联系,确保AI的益处能够延伸到全球的实验室、图书馆和教室

https://mp.weixin.qq.com/s/9VGr0KXg5TxdUo9eMlFxyw


















 1261
1261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











