







背景:虚拟机ubuntu16.04 爬取内涵段子文字,replace处理字符串

要求,根据客户要求要爬取的page数,将段子爬取下来:
源码如下:
1 # -*- coding:utf-8 -*-
2
3 import urllib2
4 import re
5
6 class Spider:
7 def __init__(self):
8 self.page=1
9 self.switch = True
10
11 def loadPage(self):
12 #下载页面
13 url = "http://www.neihanpa.com/article/list_5_"+str(self.page)+".html"
14 headers ={"User-Agent":"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0"}
15 request = urllib2.Request(url,headers=headers)
16 response = urllib2.urlopen(request)
17 html = response.read().decode("gbk").encode("utf-8")
18 #print html
19 self.dealPage(html)
20
21 def dealPage(self,html):
22 #处理每页的段子
23
24 pattern = re.compile('<div\sclass="f18 mb20">(.*?)</div>',re.S)
25 content_list = pattern.findall(html)
26 for content in content_list:
27 content = content.replace("<br>","").replace("&hellip","").replace("&ldquo","").replace("&rdquo","").replace("<br />","").replace("<p>","").replace("</p>","")
28 self.writePage(content)
29
30 def writePage(self,item):
31 #写入文件
32 with open("duanzi.txt","a") as f:
33 f.write(item)
34
35 def startWork(self):
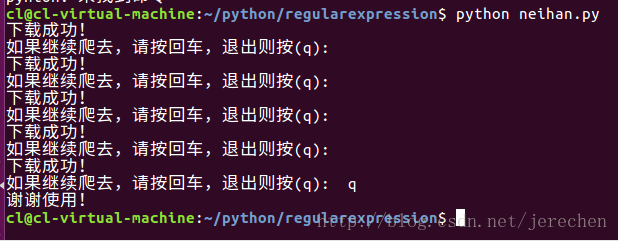
36 while self.switch==True:
37 self.loadPage()
38 print "下载成功!"
39 command = raw_input("如果继续爬去,请按回车,退出则按(q): ")
40 if command =="q":
41 self.switch = False
42 print "谢谢使用!"
43 self.page+=1
44
45 if __name__ == "__main__":
46 neihanspider = Spider()
47 neihanspider.startWork()
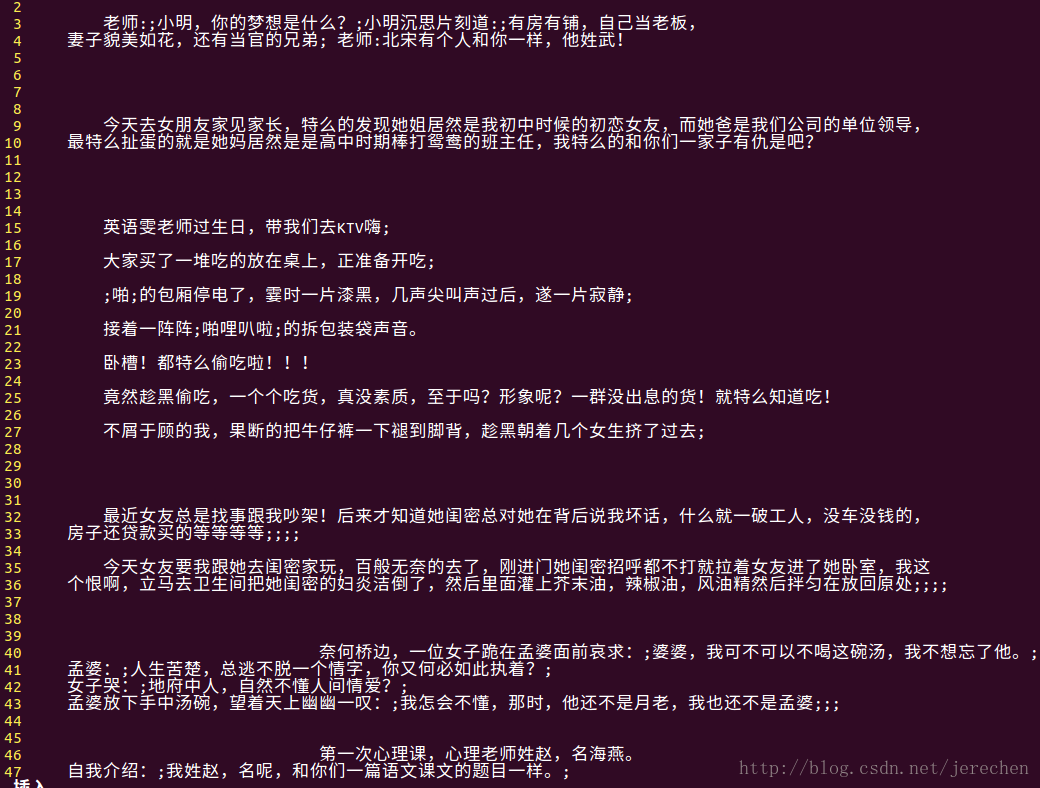
打开duanzi.txt文件查看















 301
301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









