






------Java培训、Android培训、iOS培训、.Net培训、期待与您交流! -------
Foundation框架:
Foundation类层次的根是NSObject类,它(和NSObject及NSCopying协议一起)定义了基本的对象属性和行为。Foundation框架的剩余部分由几组相互关联的类和一些独立的类组成。有一些代表基本数据类型的类,如字符串、字节数组、用于存储其它对象的集合类,一些代表系统信息的类
简单的说,Foundation框架就是许多个常用类的集合程序的开发过程,Foundation框架将经常使用平时创建OC类的时候,就要引用Foundation框架的Foundation.h文件#import <Foundation/Foundation.h>
Foundation框架中4种常用的结构体NSRange,NSPoint,NSSize,NSRect
结构体:
1.NSRange
1)NSRange原来就是由两个unsigned long类型组成的结构体:
2)NSRange的两个成员
NSRange有两个Unsigned long类型的成员:location、length
可以用来描述几个字母在字符串中所处的位置和长度。
也可以描述数组中几个数据所处的位置和范围。
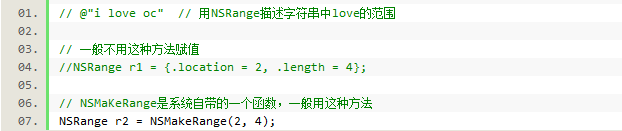
3)用NSString的对象方法rangeOfString,查找某个字符串在str中的范围

NSPoint(CGPoint)表示坐标
为什么使用CGPoint?
因为CGPoint和NSPoint的功能是一样的,但是CGPoint是跨平台的,所以一般使用CGPoint
NSPoint定义在Foundation/NSGeometry.h中,其定义格式是这样的:

NSPoint表示一个平面上的点,分别用x和y表示横坐标和竖坐标。这点在我们以后操作屏幕上的点定位都是有用的,NSPoint跟NSRange一样,同样可以使用函数NSMakePoint(CGFloat x, CGFloat y)来产生一个NSPoint,使用函数NSStringFromPoint(NSPoint point)来将NSPoint格式化为一个NSString字符串。
3、NSSize(CGSize)表示UI元素的尺寸,宽度和高度
NSSize结构体同样是定义在Foundation/NSGeometry.h中的,其定义结构如下
4、NSRect(CGRect)
NSRect结构体定义在Foundation/NSGeometry.h中,其定义为:

这个结构体用来存储宽度和高度,origin表示矩形左上角的坐标,size表示矩形的高度和宽度。同样的,我们可以使用NSMakeRect()和CGRectMake()来创建一个NSRect或者CGRect
NSString和NSMutableString
1.NSString(不可变字符串)
字符串创建的几种方式:
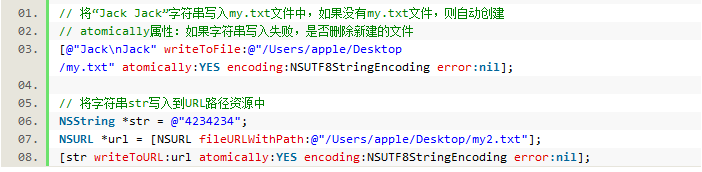
2.URL(资源路径)
URL的书写格式
协议头://路径
协议头包括:http(网络资源)、ftp(FTP服务器资源)、file(本地文件)等
3.创建字符串的类方法
一般都会有一个与对象initWith方法配对的类方法。开发中,我们常用类方法,因为代码短,省时间。

4.字符串的导出
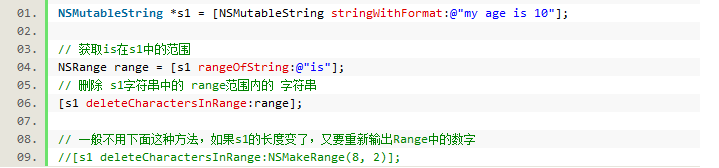
6.NSMutableString(可变字符串)
1)可变字符串的拼接:
这里用到了字符串对象方法 appendString:

2)不可变字符串拼接后新建字符串

3)删除字符串中的某个字符串
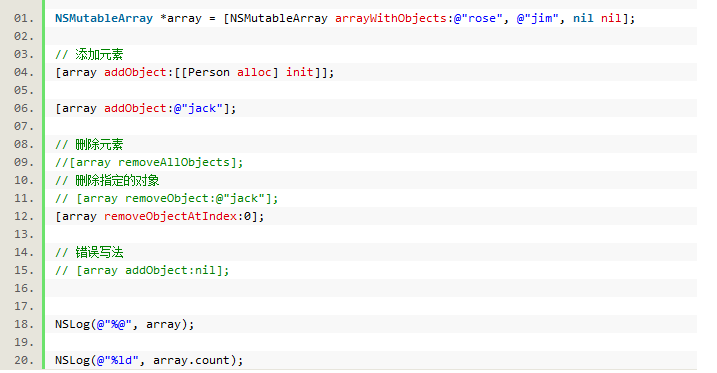
三、集合类 NSArray和NSMutableArray(OC数组)
1.可变数组、不可变数组
NSArray:不可变数组
NSMutableArray:可变数组
NSMutableArray是NSArray的子类
2.OC数组与C语言数组的区别
C语言数组:只能存放单一类型数据

OC数组:可以存放各种OC对象
* OC数组不能存放nil值,nil代表OC数组的结束。
* OC数组只能存放OC对象、不能存放非OC对象类型,比如int、struct、enum等

可变数组的基本使用:
集合类 NSSet和NSMutableSet (无序数组)
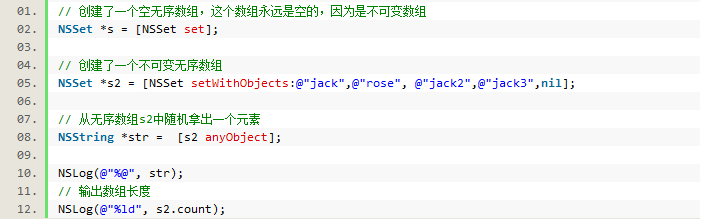
1.NSSet 无序不可变数组
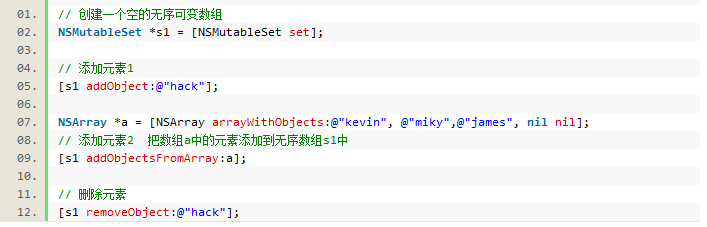
NSMutableSet 无序可变数组
集合类 NSDictionary和NSMutableDictionary (字典)
字典:一个key(键)对应一个value(值),里面存储的东西都是键值对。
key(id类型) ----> value(id类型)
一般用法:索引 ---->文字内容
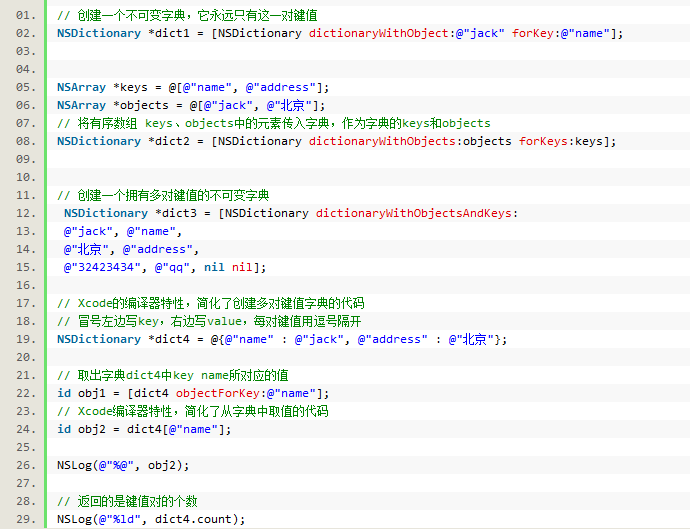
不可变字典 NSDictionary
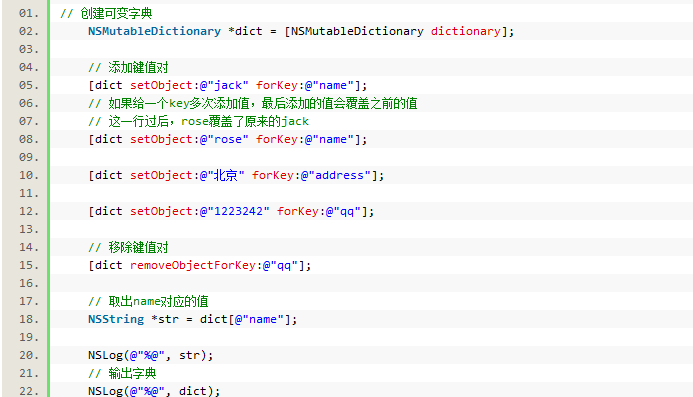
可变字典 NSMutableDictionary
字典的遍历
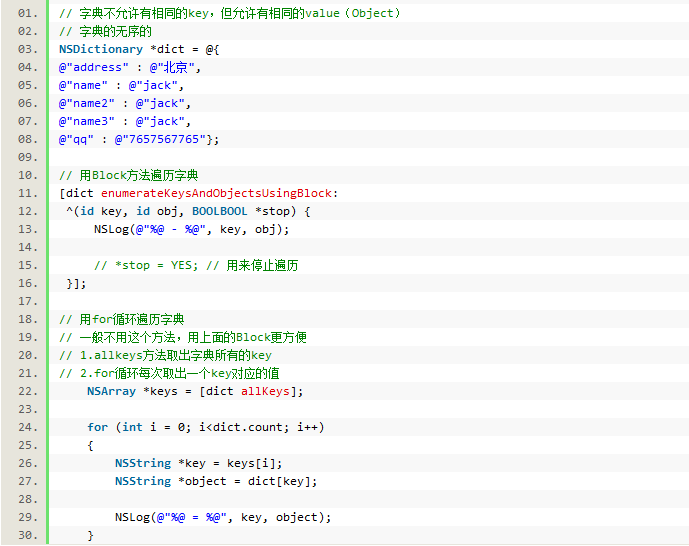
集合类总结
集合
1.NSArray\NSMutableArray
*有序
*快速创建(不可变):@[obj1, obj2, obj3]
*快速访问元素:数组名[i]
2.NSSet\NSMutableSet
*无序
3.NSDictionary\NSMutableDictionary
*无序
*快速创建(不可变):@{key1 : value1, key2 : value2}
*快速访问元素:字典名[key]
NSValue/NSNumber
1.简介
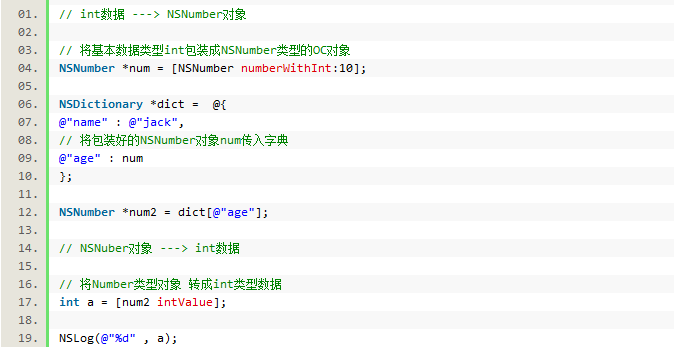
在OC数组和字典中,只能存放OC对象。如果我们想传一个基本数据类型到数组中,比如int类型,只能将int包装成字符串对象:@“20”。
OC中提供这两个类NSValue、NSNumber,可以将任何基本数据类型转成NSValue或NSNumber类型的对象。
* NSNumber是NSValue的子类
* NSValue可以包装任何基本数据
* NSNumber只能包装数字(int、double、floa、BOOL、enum)
NSNumber的基本使用
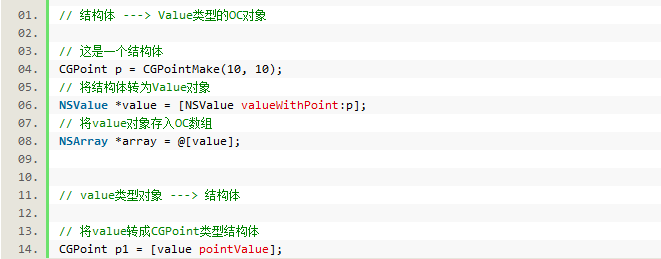
NSValue的基本使用
NSValue一般用于包装结构体:CGPoint、CGSize、CGRect
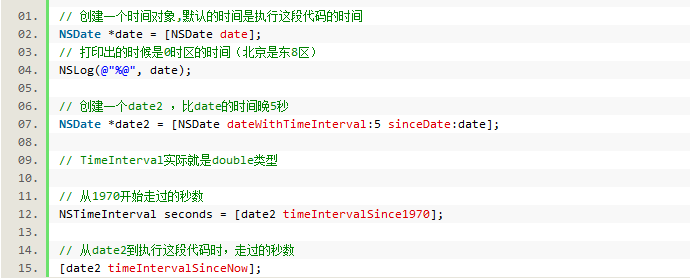
NSDate 时间
1.基本使用
2.时间格式化
当我们想把NSDate对象中的时间输出到手机屏幕上时,我们就需要将NSDate对象转成字符串。
但如何告诉程序我们想要用什么格式输出呢?2015\04\07 还是 2015-04-07 11:10:36? 用24时制还是12时制?
这就用到了时间格式类:NSDateFormatter
1)将NSDate对象转成字符串
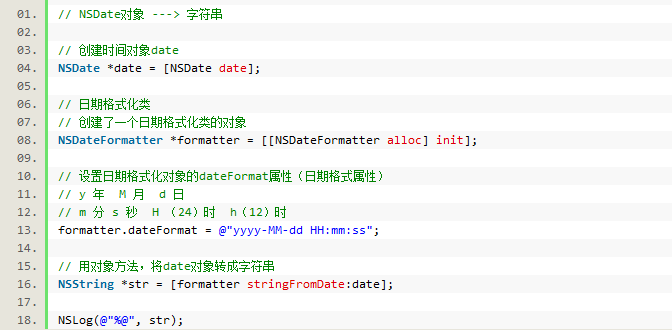
2)将字符串转成NSDate对象
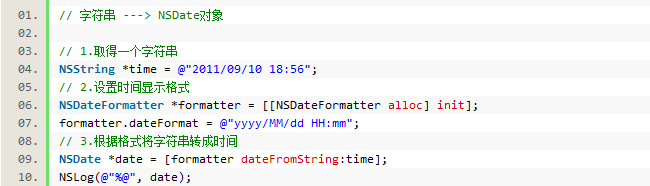
总结:
1.结构体一般用CG前缀而不用NS,CG是跨平台的。
2.调用CG开头的函数需要添加CoreGraphics框架
3.NSMutable开头的类都是可变的,都是不带Mutable的类的子类
4.基本数据类型与OC对象的转换:NSValue/NSNumber
5.默认显示时间是0时区的时间,北京是东8区。时间格式化:NSDateFormatter















 1055
1055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









