






本期分享如下:
- 浮点数精度问题
- 分区键巧用表达式
- PostGIS依赖的组件版本
- pg_profile部署
一、Java里double类型存储到varchar精度丢失问题
数据库表结构如下:
create table t1(a varchar);
Java使用double类型插入数据主要代码如下:
String sql = "insert into t1 values(?)";
PreparedStatement ps = connection.prepareStatement(sql);
ps.setObject(1, new Double(48)); ps.execute();
ps.setObject(1, new Double(48.1)); ps.execute();
ps.setObject(1, new Double(48.9)); ps.execute();
JDBC驱动层发送到服务端时会隐含设置extra_float_digits = 3,此时PG 11和PG 12入库的结果会有差异。

为什么12里使用varchar存储没有丢失精度呢,从官方文档的如下片段可以找到答案:
Improve performance by using a new algorithm for output of real and double precision values (Andrew Gierth)
Previously, displayed floating-point values were rounded to 6 (for real) or 15 (for double precision) digits by default, adjusted by the value of extra_float_digits. Now, whenever extra_float_digits is more than zero (as it now is by default), only the minimum number of digits required to preserve the exact binary value are output. The behavior is the same as before when extra_float_digits is set to zero or less.
从12版本开始,浮点数输出显示的精度做了优化,extra_float_digits参数描述也做了精化,浮点数显示默认使用shortest-precise模式,极简精确模式。
二、表达式分区键的妙用
大量数据在一个csv格式的文件里,有三个字段a,b,c,数据文件参考如下:
$ cat data.csv
a,b,c
1,aa1001,data
2,bb1002,data
copy入库时可以截取b字段的前两位入到对应分区吗?是否需要使用触发器呢?
PG 10版本支持声明式分区,分区键还可以使用表达式:
CREATE TABLE tab(
a varchar,
b varchar,
c varchar
) PARTITION BY LIST(substr(b,1,2));
创建分区
CREATE TABLE tab_aa PARTITION OF tab FOR VALUES IN('aa');
CREATE TABLE tab_bb PARTITION OF tab FOR VALUES IN('bb');
使用copy入库
postgres=# \copy tab from data.csv with (format 'csv',header true)
COPY 2
postgres=# select * from tab;
a | b | c
---+--------+------
1 | aa1001 | data
2 | bb1002 | data
(2 rows)
postgres=# select * from tab_aa;
a | b | c
---+--------+------
1 | aa1001 | data
(1 row)
postgres=# select * from tab_bb;
a | b | c
---+--------+------
2 | bb1002 | data
(1 row)
三、如何确定PostGIS使用第三方组件版本
例如使用PG 16版本安装PostGIS,应该如何选择PostGIS的版本,同时PostGIS依赖的第三方组件Geos、PROJ、GDAL应该使用什么版本?
从PostGIS的wiki网站可以找到最佳搭配:
https://trac.osgeo.org/postgis/wiki/UsersWikiPostgreSQLPostGIS
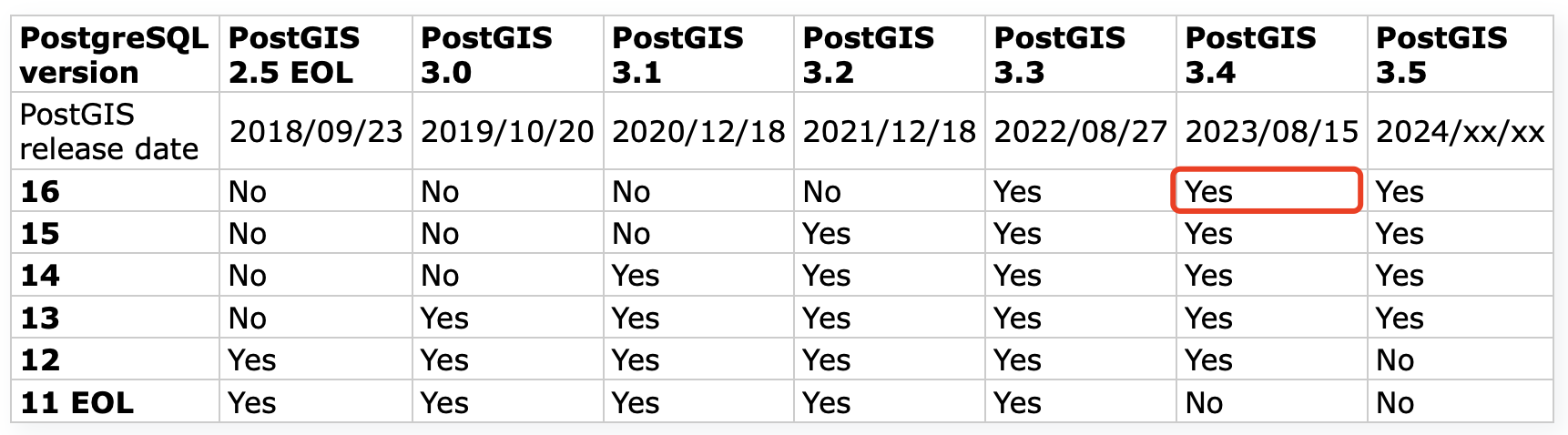
从上面的矩阵可以看出,在PG 16里PostGIS需要使用3.3~3.5版本,支持PostGIS的第三方组件版本也有相应的版本矩阵。
四、PG 16部署pg_profile
首先需要检查数据库如下参数
track_activities = on
track_counts = on
track_io_timing = on
track_wal_io_timing = on
track_functions = all/pl
shared_preload_libraries = 'pg_stat_statements,pg_stat_kcache,pg_wait_sampling'
源码编译pg_profile
$ tar xzf pg_profile--4.4.tar.gz --directory $(pg_config --sharedir)/extension
使用三个角色权限来管理pg_profile
- pg_profile owner:profile_usr
CREATE SCHEMA dblink;
CREATE EXTENSION dblink SCHEMA dblink;
CREATE USER profile_usr with password 'profile_pwd' ;
GRANT USAGE ON SCHEMA dblink TO profile_usr;
CREATE SCHEMA profile AUTHORIZATION profile_usr;
\c postgres profile_usr
CREATE EXTENSION pg_profile SCHEMA profile;
- collecting role:profile_collector
\c postgres postgres
CREATE SCHEMA pgss;
CREATE SCHEMA pgsk;
CREATE SCHEMA pgws;
CREATE EXTENSION pg_stat_statements SCHEMA pgss;
CREATE EXTENSION pg_stat_kcache SCHEMA pgsk;
CREATE EXTENSION pg_wait_sampling SCHEMA pgws;
CREATE USER profile_collector with password 'collector_pwd';
GRANT pg_read_all_stats TO profile_collector;
GRANT USAGE ON SCHEMA pgss TO profile_collector;
GRANT USAGE ON SCHEMA pgsk TO profile_collector;
GRANT USAGE ON SCHEMA pgws TO profile_collector;
GRANT EXECUTE ON FUNCTION pgsk.pg_stat_kcache_reset TO profile_collector;
GRANT EXECUTE ON FUNCTION pgss.pg_stat_statements_reset TO profile_collector;
GRANT EXECUTE ON FUNCTION pgws.pg_wait_sampling_reset_profile TO profile_collector;
profile_usr宿主配置server端采集:
\c postgres profile_usr
SELECT profile.set_server_connstr('local','dbname=postgres port=1602 host=127.0.0.1 user=profile_collector password=collector_pwd');
设置数据过期策略:
SELECT profile.set_server_max_sample_age('local',3);
SELECT profile.show_servers();
再使用profile_usr用户发起采集
\c postgres profile_usr
SELECT * FROM profile.take_sample();
- reporting role:具有pg_read_all_stats角色的普通用户
GRANT pg_read_all_stats TO admin;
\c postgres admin
postgres=> SELECT profile.show_samples();
show_samples
-----------------------------------
(1,"2024-03-20 05:02:36+08",t,,,)
(2,"2024-03-20 05:07:01+08",t,,,)
(3,"2024-03-20 05:14:15+08",t,,,)
(3 rows)
最后生成HTML报告
psql -Aqtc 'select profile.get_report(1,2)' --output report1.html
psql -Aqtc "select profile.get_report_latest('local')" --output report2.html
还可以生成基线差异报告
psql -Aqtc 'select profile.get_diffreport(2,3,4,5)' --output report_diff.html
HTML报告如下:
关联推荐
- PostgreSQL知识问答分享-第38期
- PostgreSQL知识问答分享-第37期
- PostgreSQL知识问答分享-第36期
- PostgreSQL知识问答分享-第35期
- PostgreSQL知识问答分享-第34期
- PostgreSQL知识问答分享-第33期
- PostgreSQL知识问答分享-第32期
- PostgreSQL知识问答分享-第31期
- PostgreSQL知识问答分享-第30期
- PostgreSQL知识问答分享-第29期
如果有任何问题需要讨论交流的朋友,欢迎添加本人微信号skypkmoon。

















 4834
4834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









