







实际工作中,通常只有批量处理文档或者需要频繁处理固定格式文档的时候,使用工具的价值比较大。
使用python-docx处理Word文档的时候,可以创建一个全新的文档,或者修改一个文档。
如果批量处理或频繁处理的都是固定格式的文档,通常使用文档模板会更简单方便。毕竟工作追求的是效率,而不是技术研究。
使用文档模板处理工作的思路:
1、创建一个Word文档,在里面编辑好格式和内容
2、把里面需要动态填充的内容用占位符替换
3、组织数据内容到Excel / 数据库 / 文本 或其他地方,作为数据源
4、编写python程序
4.1、读取数据源
4.2、使用python-docx读取Word文档模板
4.3、替换Word模板文档中的占位符为数据源中的实际内容
4.4、保存新的Word文档
下面通过一个示例场景演示如何实现上面的思路,场景为批量生成邀请函。
1、创建Word文档模板
文档模板示例如下图:
其中需要动态替换的内容为 #attendee#(参会人),#meetingdate#(会议日期),#meetingplace#(会议地点),#meetingsubject#(会议主题) 。 #attendee# 就是用来占位的,后续会被实际的内容替换掉。
为了体现演示效果,#meetingdate# 设置为加粗,#meetingsubject# 设置为红色,看替换后生成的文档是不是和我们的预期相符。

2、读取并替换为实际内容(替换paragraph.text里的占位符)
from docx import Document
# 准备演示数据,实际应用时数据可以从Excel中读取,或从数据库读取,或从其他地方获得
dic_values = [
{'#attendee#':'张三', '#meetingdate#':'2023年11月1日', '#meetingplace#':'西安', '#meetingsubject#':'没有主题'}
,{'#attendee#':'李四', '#meetingdate#':'2023年11月1日', '#meetingplace#':'西安', '#meetingsubject#':'没有主题'}
,{'#attendee#':'王五', '#meetingdate#':'2023年11月1日', '#meetingplace#':'西安', '#meetingsubject#':'没有主题'}
]
# 一份数据生成一个文档
for val in dic_values:
document = Document('./doc_template1.docx')
for paragraph in document.paragraphs:
print(paragraph.text) # 替换前的段落内容
for key, value in val.items():
if paragraph.text.find(key) > 0:
paragraph.text = paragraph.text.replace(key, value)
print(paragraph.text) # 替换后的段落内容
document.save(f'doc_template_{val["#attendee#"]}.docx')上面代码运行后的输出结果
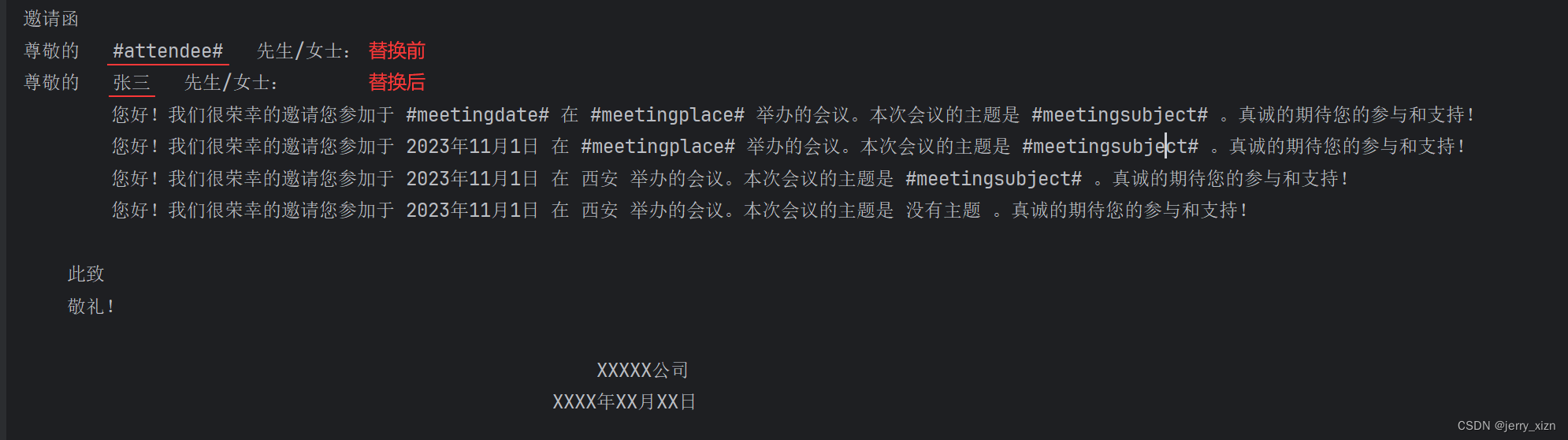

上面的运行结果可以看到,文档是生成了, 但内容格式和我们预期的不一致,显然这不是我们想要的。
3、读取并替换为实际内容(替换run.text里的占位符)

from docx import Document
# 准备演示数据,实际应用时数据可以从Excel中读取,或从数据库读取,或从其他地方获得
dic_values = [
{'attendee':'张三', 'meetingdate':'2023年11月1日', 'meetingplace':'西安', 'meetingsubject':'没有主题'}
,{'attendee':'李四', 'meetingdate':'2023年11月1日', 'meetingplace':'西安', 'meetingsubject':'没有主题'}
,{'attendee':'王五', 'meetingdate':'2023年11月1日', 'meetingplace':'西安', 'meetingsubject':'没有主题'}
]
# 一份数据生成一个文档
for val in dic_values:
document = Document('./doc_template1.docx')
# 替换run里的text
for paragraph in document.paragraphs:
for run in paragraph.runs:
print(run.text)
for key, value in val.items():
if run.text.find(key) > -1:
run.text = run.text.replace(key, value)
print(run.text) # 替换后的内容
document.save(f'doc_template_{val["attendee"]}.docx')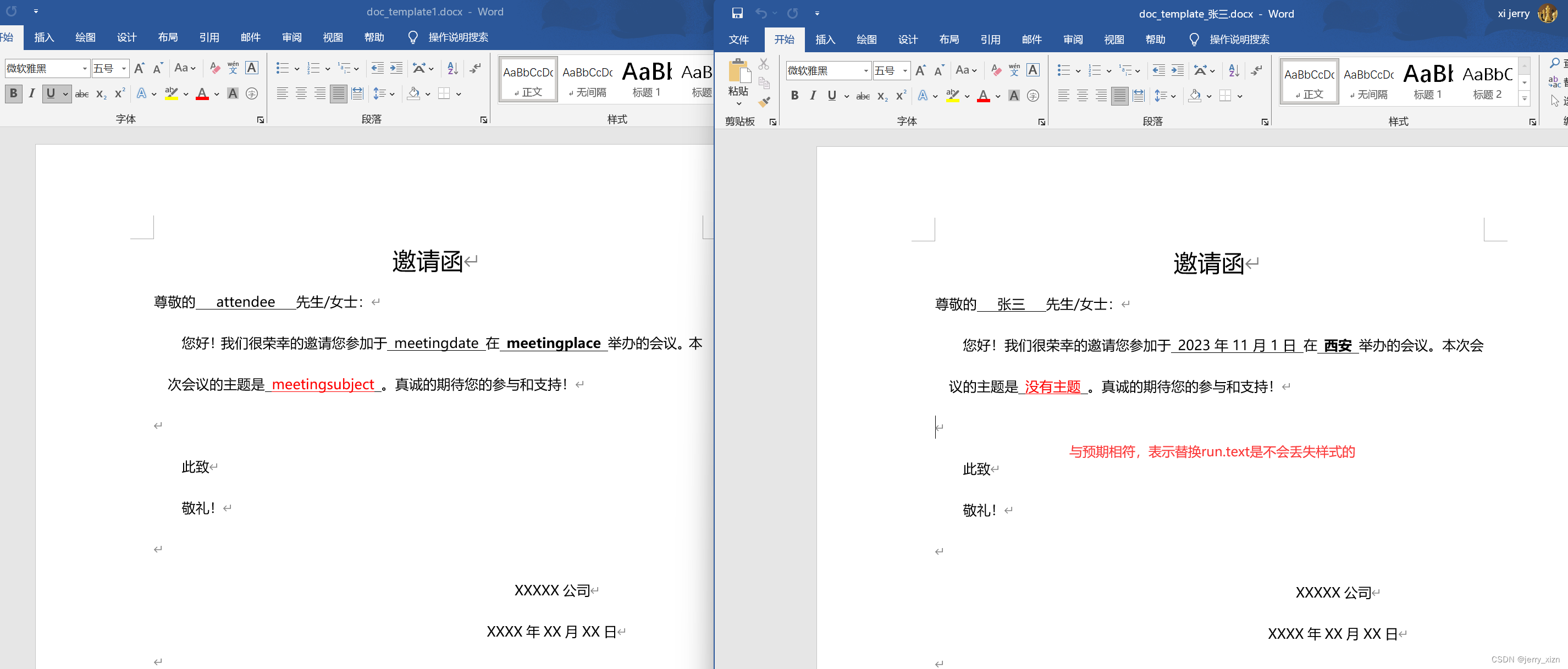
通过上面的示例可以看到,替换run.text是不会丢失样式的,和我们的预期结果一致。
不过大家会发现这次使用的占位符没有特殊符号【#】,而是用的一个完整的词语,这是因为runs会根据一些特殊字符把文本内容分割成许多不同的块,如下所示:#attendee# 被分割成了3个run,这样就无法用Replace函数了,因为每一个单独的run匹配不到定义的“键”。

for paragraph in document.paragraphs:
for run in paragraph.runs:
print(run.text)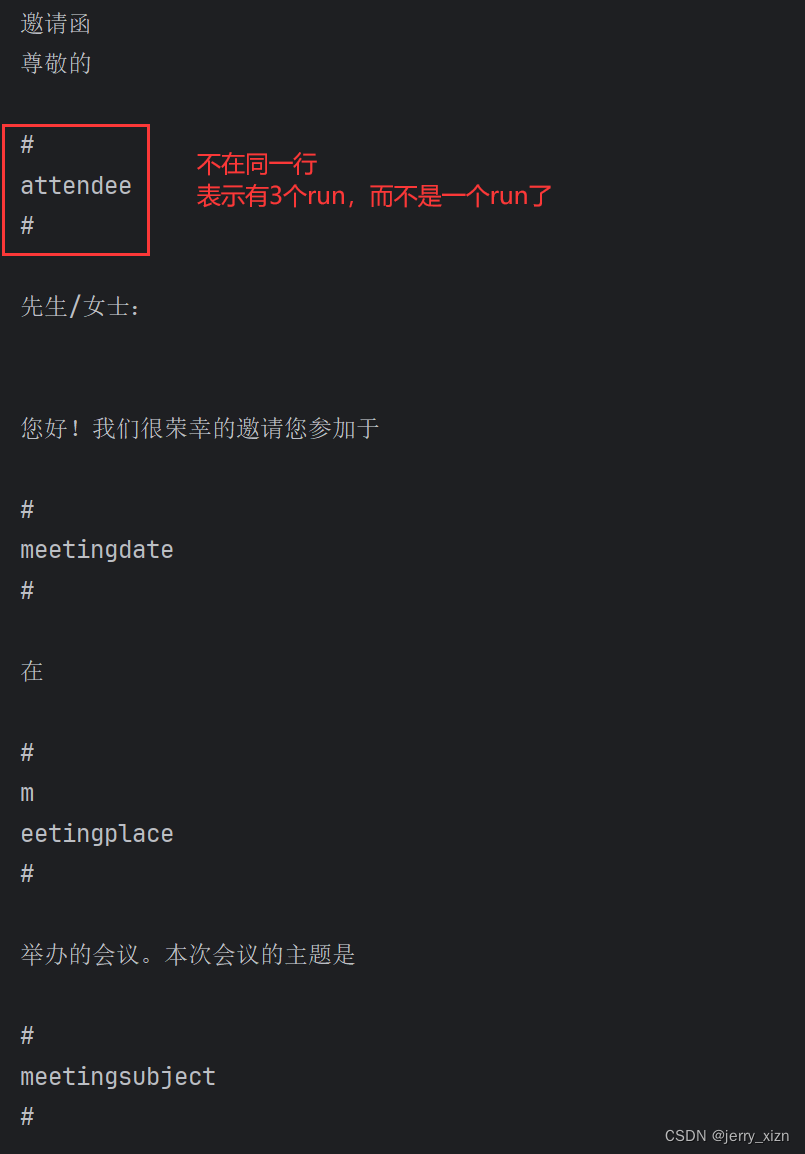
有人可能会说,那就把“占位符的每个键”定义成一个单独的词语不就可以了,不用加特殊字符了。这样也是可以的,不过这就要求每个键都不能与文档内容里的词语重复,否则就会出现把不应该被替换的内容给替换掉。
实际使用场景中,占位符的键不与文档内容里的词语重复,有时候很难避免,所以尽量用特殊符号把占位表装饰一下,既避免出现重合的情况,又能明显的看出哪些是占位符,哪些是正常文本内容。
而且面对runs把文本内容分割了的情况也是有办法处理的。
4、读取并替换为实际内容(替换run.text里带特殊占位符的内容)

from docx import Document
# 准备演示数据,实际应用时数据可以从Excel中读取,或从数据库读取,或从其他地方获得
dic_values = [
{'#attendee#':'张三', '#meetingdate#':'2023年11月1日', '#meetingplace#':'西安', '#meetingsubject#':'没有主题'}
,{'#attendee#':'李四', '#meetingdate#':'2023年11月1日', '#meetingplace#':'西安', '#meetingsubject#':'没有主题'}
,{'#attendee#':'王五', '#meetingdate#':'2023年11月1日', '#meetingplace#':'西安', '#meetingsubject#':'没有主题'}
]
# 一份数据生成一个文档
for val in dic_values:
document = Document('./doc_template1.docx')
for paragraph in document.paragraphs:
runs = paragraph.runs
for i, run in enumerate(runs):
if run.text == '#':
counter = i # 记录起始位置
tmp = '#' # tmp开始存储
while tmp not in list(val.keys()):
counter += 1
tmp += runs[counter].text
runs[counter].clear()
runs[i].text = runs[i].text.replace(runs[i].text, val[tmp])
document.save(f'doc_template_{val["#attendee#"]}.docx')

5、总结
- 替换paragraph.text里的占位符最简单容易,但是会丢失内容的样式,如果不关心样式,只关心内容,则可以使用该方式;
- 替换run.text里的占位符,不会丢失样式,建议使用这种方式,实际开发过程中,可以把对run.text的替换封装成一个方法,然后去调用就可以了;
- 不管用哪种方法,占位符的定义,尽量不要直接用词语,最好用特殊符号装饰一下,避免把不应该被替换的内容替换掉;















 243
243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











