






下面是kaggle比赛的学习笔记, 登录注册(我用google账号直接注册登录最简单)kaggle 网站之后点击Learn。
介绍
我们将从机器学习模型的工作原理以及它们的应用概述开始。如果您以前进行过统计建模或机器学习,这可能会感觉很基础。不用担心,我们将很快进入构建强大模型的阶段。
在这门课程中,您将在以下情境中构建模型:
您的表弟通过炒房赚了数百万美元。由于您对数据科学的兴趣,他提出与您合作成为商业伙伴。他提供资金,而您则提供能够预测各种房屋价值的模型。
您询问表弟他过去是如何预测房地产价值的,他说那只是凭直觉。但通过进一步询问,您发现他已经从过去看到的房屋中识别出价格模式,并使用这些模式为他正在考虑的新房屋做出预测。
机器学习的工作方式与此类似。我们将从一个称为决策树的模型开始。虽然有一些更精密的模型可以提供更准确的预测,但决策树易于理解,是数据科学中一些最佳模型的基本构建块。
为了简单起见,我们将从最简单的决策树开始。
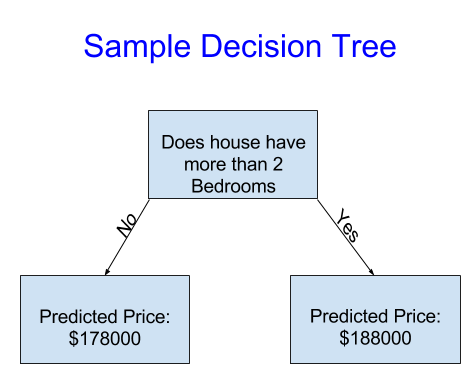
它将房屋分为仅两类。对于正在考虑的任何房屋,预测价格是同一类别房屋的历史平均价格。
我们使用数据来决定如何将房屋分成两组,然后再次确定每组中的预测价格。从数据中捕获模式的这一步骤称为模型的“拟合”或“训练”。用于“拟合”模型的数据称为“训练数据”。
关于模型如何“拟合”(例如如何拆分数据)的细节足够复杂,我们将在以后详细说明。在模型拟合后,您可以将其应用于新数据,以预测额外房屋的价格。
改进决策树 以下两个决策树中,更有可能是通过拟合房地产训练数据得到的呢?
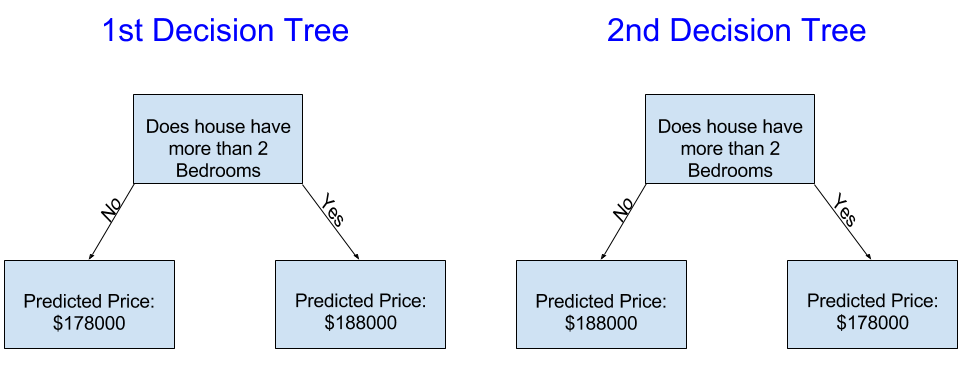
左侧的决策树(决策树1)可能更有意义,因为它捕捉到了拥有更多卧室的房屋往往售价高于卧室较少的房屋的现实情况。这个模型最大的缺点是它未捕捉到影响房价的大多数因素,如浴室数量、地块大小、位置等。
通过使用具有更多“分割”的树,您可以捕捉更多因素。这些被称为“更深”的树。一个考虑到每个房屋地块总大小的决策树可能如下所示:
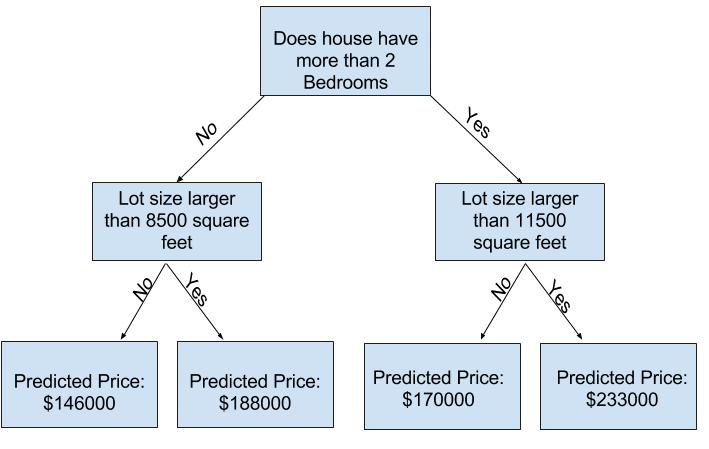
你通过沿着决策树追踪,始终选择与该房屋特征相对应的路径来预测任何房屋的价格。房屋的预测价格位于树的底部。在我们进行预测的底部点称为“叶子”。
叶子上的分割和值将由数据确定,因此现在是您查看将要使用的数据的时候了。
继续
使用 Pandas 熟悉您的数据
机器学习项目的首要步骤是熟悉数据。为此,您将使用 Pandas 库。Pandas 是数据科学家用于探索和操作数据的主要工具。大多数人在代码中将 pandas 缩写为 pd。我们可以通过以下命令做到这一点:
Python
import pandas as pd
Pandas 库最重要的部分是 DataFrame。DataFrame 容纳了您可能认为是表格类型的数据。这类似于 Excel 中的 sheet 或 SQL 数据库中的表。Pandas 为您想要使用这种类型的数据执行的大多数操作提供了强大的方法。
作为示例,我们将查看澳大利亚墨尔本的房屋价格数据。在动手练习中,您将把相同的过程应用于一个新的数据集,其中包含爱荷华州的房屋价格。
示例(墨尔本)数据位于文件路径 ../input/melbourne-housing-snapshot/melb_data.csv。我们使用以下命令加载和探索数据:
Python
# 将文件路径保存到变量以方便访问
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
# 读取数据并将其存储在名为 melbourne_data 的 DataFrame 中
melbourne_data = pd.read_csv(melbourne_file_path)
# 打印墨尔本数据中数据的摘要
melbourne_data.describe()
Id MSSubClass LotFrontage LotArea OverallQual OverallCond YearBuilt YearRemodAdd MasVnrArea BsmtFinSF1 ... WoodDeckSF OpenPorchSF EnclosedPorch 3SsnPorch ScreenPorch PoolArea MiscVal MoSold YrSold SalePrice count 1460.000000 1460.000000 1201.000000 1460.000000 1460.000000 1460.000000 1460.000000 1460.000000 1452.000000 1460.000000 ... 1460.000000 1460.000000 1460.000000 1460.000000 1460.000000 1460.000000 1460.000000 1460.000000 1460.000000 1460.000000 mean 730.500000 56.897260 70.049958 10516.828082 6.099315 5.575342 1971.267808 1984.865753 103.685262 443.639726 ... 94.244521 46.660274 21.954110 3.409589 15.060959 2.758904 43.489041 6.321918 2007.815753 180921.195890 std 421.610009 42.300571 24.284752 9981.264932 1.382997 1.112799 30.202904 20.645407 181.066207 456.098091 ... 125.338794 66.256028 61.119149 29.317331 55.757415 40.177307 496.123024 2.703626 1.328095 79442.502883 min 1.000000 20.000000 21.000000 1300.000000 1.000000 1.000000 1872.000000 1950.000000 0.000000 0.000000 ... 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 1.000000 2006.000000 34900.000000 25% 365.750000 20.000000 59.000000 7553.500000 5.000000 5.000000 1954.000000 1967.000000 0.000000 0.000000 ... 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 5.000000 2007.000000 129975.000000 50% 730.500000 50.000000 69.000000 9478.500000 6.000000 5.000000 1973.000000 1994.000000 0.000000 383.500000 ... 0.000000 25.000000 0.000000 0.000000 0.000000 0.000000 0.000000 6.000000 2008.000000 163000.000000 75% 1095.250000 70.000000 80.000000 11601.500000 7.000000 6.000000 2000.000000 2004.000000 166.000000 712.250000 ... 168.000000 68.000000 0.000000 0.000000 0.000000 0.000000 0.000000 8.000000 2009.000000 214000.000000 max 1460.000000 190.000000 313.000000 215245.000000 10.000000 9.000000 2010.000000 2010.000000 1600.000000 5644.000000 ... 857.000000 547.000000 552.000000 508.000000 480.000000 738.000000 15500.000000 12.000000 2010.000000 755000.000000
数据描述解读
输出显示了您原始数据集每个列的 8 个数字。以下解释每个数字的含义:
count: 表示该列有多少行非缺失值。缺失值可能出于多种原因出现,例如,在调查一套一居室房屋时不会收集第二卧室的尺寸。我们稍后会讨论缺失值问题。
mean: 这代表该列的平均值。
std: 这是标准差,它衡量数值在数值上分散的程度。标准差越大,表示数据变异性越大。
min、25%、50%、75%、max: 想象您将每一列从低到高排序。这些数字代表排序列表中的不同点:
- min: 该列中的最小值。
- 25%(25th 百分位数): 大于 25% 的值且小于 75% 的值。
- 50%(中位数): 排序后数据的中间值。
- 75%(75th 百分位数): 大于 75% 的值且小于 25% 的值。
- max: 该列中的最大值。
这些统计数据为每个列的值分布提供了简洁的概述。分析它们可以帮助您了解数据中的中心趋势、变异性和潜在的异常值。
这个练习将测试您读取数据文件并了解有关数据的统计信息的能力。
在后续练习中,您将应用技术来过滤数据,构建机器学习模型,并逐步改进您的模型。
该课程示例使用的是墨尔本的数据。为了确保您能够自己应用这些技术,您将需要将它们应用到一个新的数据集(其中包含来自爱荷华州的房价)上。
这些练习使用“笔记本”编码环境。如果您对笔记本不熟悉,我们有一个90秒的介绍视频。
练习 运行以下单元格来设置代码检查,它将在您进行工作时验证您的工作。
# 设置代码检查
from learntools.core import binder
binder.bind(globals())
from learntools.machine_learning.ex2 import *
print("Setup Complete")
Step 1: 加载数据 将爱荷华数据文件读入一个名为home_data的Pandas DataFrame中。
import pandas as pd
import datetime
# 文件路径
iowa_file_path = '../input/home-data-for-ml-course/train.csv'
# 用以下行填充下面的代码,将文件读入名为home_data的变量中
home_data = pd.read_csv(iowa_file_path)
# 调用下面的行,不带参数,检查您是否正确加载了数据
step_1.check()
Step 2: 查看数据 使用您学到的命令查看数据的摘要统计信息。然后填写变量以回答以下问题:
# 打印下一行的摘要统计信息
home_data.describe()
summary_statistics = home_data.describe()
# 平均地块大小是多少(四舍五入到最接近的整数)?
avg_lot_size = round(summary_statistics['LotArea']['mean'])
# 截至今天,最新的房屋有多少年了(当前年份减去建造年份)
current_year = datetime.datetime.now().year # 获取当前年份
newest_home_age = current_year - int(summary_statistics['YearBuilt']['max']) # 最小的楼龄,将建造年份减去当前年份
# 检查答案
step_2.check()
思考您的数据 您数据中的最新房屋并不是很新。对此有一些潜在的解释:
- 在收集这些数据的地方可能没有新建的房屋。
- 数据收集很久以前。数据发布后建造的房屋将不会出现。
如果原因是上述解释中的第一个,那么这是否影响您对使用这些数据构建的模型的信任?如果是第二个原因呢?
您如何挖掘数据以查看哪个解释更为合理?
查看此讨论主题以查看其他人的想法或添加您的想法。














 2241
2241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









