









文本分类隶属于数据挖掘方面的一个分支,不过,就文本分类而言尚有相当大的研究空间,关于文本分类,网上的资料很多,有兴趣的同事可以去研究一下.
目前文本分类可以在公司应用系统中的域名分类,垃圾邮件识别,WEB爬虫,IDC内容分析等各子系统中实际应用,此外文本分类将来也可能在行为分析,内容过滤(绿网客户端)等发挥作用.
文本分类的实现过程可以用下图表示:

关于文本分类算法,目前有三种经典分类器{最近邻(KNN)、朴素贝叶斯(Naïve Bayes)、支持向量机(SVM)},另外,还有一个中科院的叫做ICTDRAP分类器(http://www.searchforum.org.cn/tansongbo/software.htm),四者之间的对比如下:
1、 ICTDRAP, 综合性能排名第一。精度第一,速度第一。
2、 SVM,综合性能排名第二。精度第一,速度第四。
3、 Naïve Bayes,综合性能排名第三。精度第三,速度第三。
4、 KNN,综合性能排名第四。精度第四,速度第四。
2、 SVM,综合性能排名第二。精度第一,速度第四。
3、 Naïve Bayes,综合性能排名第三。精度第三,速度第三。
4、 KNN,综合性能排名第四。精度第四,速度第四。
ICTDRAP是中科院实现的一个算法,它的优越性在于它的性能表现,普通PC上它的过滤(分类)速度可以超过4M/秒,遗憾的是在网上没有找到他的算法实现,但是其它三种经典分类器算法可以在网上找到.
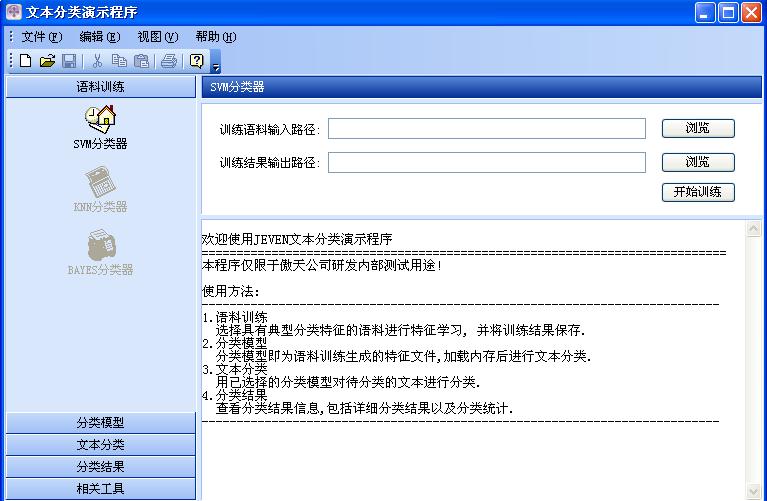
以下是程序截图:















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









