







🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
深度学习神经网络在自然语言处理中表现非常优秀,但动辄几十层,上亿参数的大型网络速度慢且需要大量算力支持,限制了使用场景。FastText是Facebook开源的一款简单而高效的文本分类器,它使用浅层的神经网络实现了word2vec以及文本分类功能,效果与深层网络差不多,节约资源,且有百倍的速度提升,可谓高效的工业级解决方案。本篇将介绍Fasttext的相关概念、原理及用法。
文本分类
文本分类是许多应用程序的核心问题,例如垃圾邮件检测,情感分析或智能回复。 在本教程中,我们将介绍如何使用fastText工具构建文本分类器。
什么是文本分类?
文本分类的目标是将文档(如电子邮件,博文,短信,产品评论等)分为一个或多个类别。 这些类别可以是根据评论分数,垃圾邮件与非垃圾邮件来划分,或者文档的编写语言。 如今,构建这种分类器的主要方法是机器学习,即从样本中学习分类规则。 为了构建这样的分类器,我们需要标注数据,它由文档及其相应的类别(也称为标签或标注)组成。
相关概念
BOW BOW是词袋Bag of Words的简称,BOW是文本分类中常用的文本向量化的方法,它忽略了顺序和语法,将文本看成词汇的集合,且词汇间相互独立,如同把词放进了一个袋子。在分类任务中使用BOW时,就是根据各个词义综合分析文本的类型,常用于感情色彩分类等领域。
CBOW
CBOW是连续词袋模型Continuous Bag-of-Word Model的简称,它常用于上下文词来预测中间词。
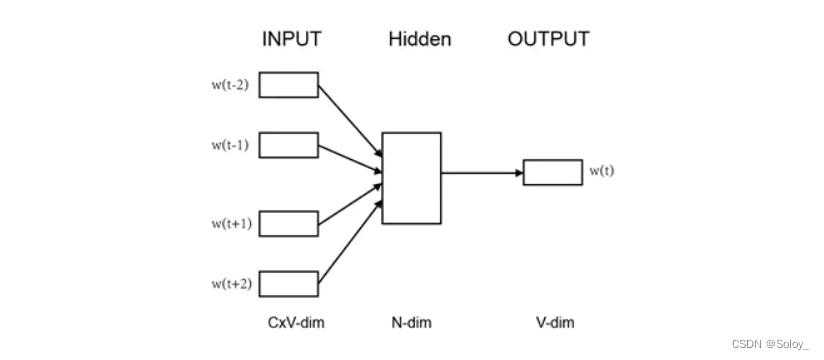
如图所示,使用前两个和后两个词(共C=4个)预测中间的词w,其中每个词被映射成V维的词向量;每个词向量乘以参数矩阵A(VN维矩阵),转换成N维数据,然后将所有词对应的N维的数据相加取均值,计算出N维的隐藏层Hidden;再用隐藏层乘参数矩阵B(NV维),计算待预测的词w对应的V维词向量;最终用预测出的w与真实的w作比较计算误差函数,然后用梯度下降调整A,B两个参数矩阵。由此,使用简单的神经网络就完成了预测任务。
N-gram
N-gram是由N个token(词)组成的有序集合,常用的有Bi-gram (N=2)和Tri-gram (N=3),实际使用中2或3-gram就够用了。Fasttext论文中使用Bi-gram将文本拆成词对。
如I love deep learning可拆成:
Bi-gram : {I, love}, {love, deep}, {deep, learning}
Tri-gram : {I, love, deep}, {love, deep, learning}
这样使一个词它之前的词建立联系。
以Bi-gram为例,Wn-1出现时,Wn出现的概率是:
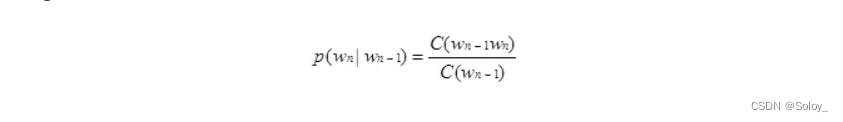
其中C()表示计数,N-gram技术在自然语言处理中广泛使用。
FastText原理
在文本分类问题中,早期的算法一般将词袋BOW作为输入,使用线性模型作为算法计算类别,这种方法在类别不均衡时效果不好,后来用将线性分类器分解为低秩矩阵或者多层网络的方法解决这一问题。
FastText与CBOW结构类似,如下图所示:
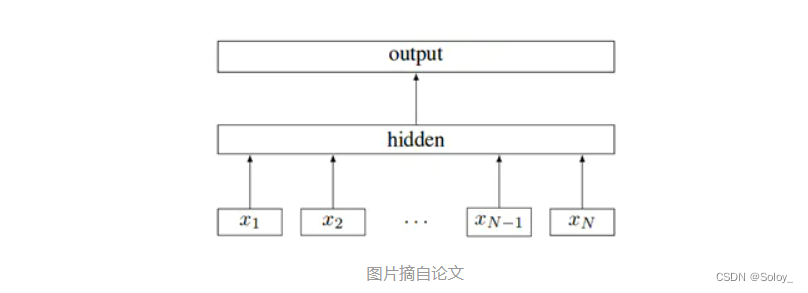
图片摘自论文
其中输入是文档中的词,使用词嵌入方法,和CBOW一样,通过乘A矩阵转换到Hidden,再乘B矩阵转换到输出层,与CBOW不同的是它的输出不是空缺的单词,而是分类的类别。
FastText用负对数似然作为损失函数:
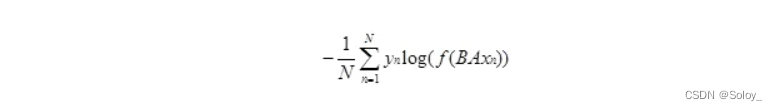
其中N是文档数,xn是文档中的词特征。yn是标签,A和B是权重矩阵,A用于转换到文本表示,B用于线性变换计算类别,f是一个softmax函数用于计算最终分类的概率。
当分类的类别较多时,计算的时间复杂度是O(hk),其中k是类别的个数,h是文本表示的维度。Fasttext使用了基于霍夫曼编码树的分级softmax,使训练的时间复杂度降为O(hlog2(k))。每一个节点的概率大小与从树根到该节点经过的路径有关,例如某节点深度为l+1,它的父节点分别是n1…n2,则它的概率是:
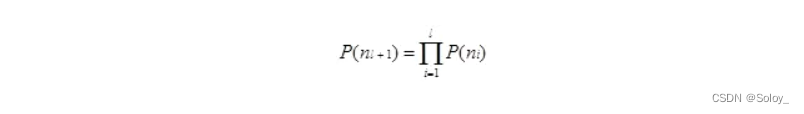
这就意味着,节点的概率小于它父节点的概率,因此访问树时,就可以忽略概率小的分枝。如果只需预测取前TopN,则复杂度可降至O(log(TopN))。
下面列出了FastText与深度学习模型的速度比较,可以看到,其提速非常明显。
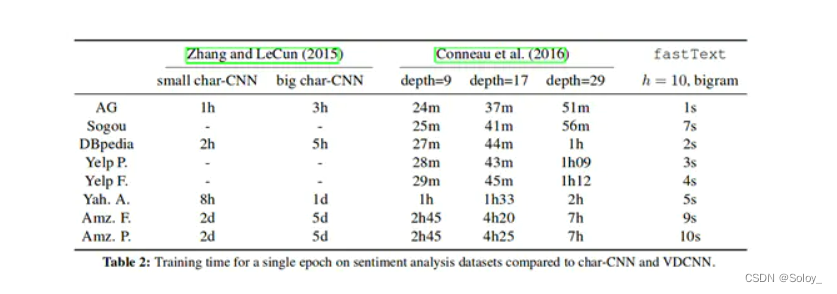
个人感觉,层次少的好处不只在于运算速度快,而且更容易归因,定位重要特征,以及估计对应的权重,不像深度网络的数据都散布在各层的节点之中。
FastText的代码实现
# coding: UTF-8
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class Config(object):
"""配置参数"""
def __init__(self, dataset, embedding):
self.model_name = 'FastText'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt', encoding='utf-8').readlines()] # 类别名单
self.vocab_path = dataset + '/data/vocab.pkl' # 词表
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.log_path = dataset + '/log/' + self.model_name
self.embedding_pretrained = torch.tensor(
np.load(dataset + '/data/' + embedding)["embeddings"].astype('float32'))\
if embedding != 'random' else None # 预训练词向量
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.dropout = 0.5 # 随机失活
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.n_vocab = 0 # 词表大小,在运行时赋值
self.num_epochs = 20 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 1e-3 # 学习率
self.embed = self.embedding_pretrained.size(1)\
if self.embedding_pretrained is not None else 300 # 字向量维度
self.hidden_size = 256 # 隐藏层大小
self.n_gram_vocab = 250499 # ngram 词表大小
'''Bag of Tricks for Efficient Text Classification'''
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.embedding_ngram2 = nn.Embedding(config.n_gram_vocab, config.embed)
self.embedding_ngram3 = nn.Embedding(config.n_gram_vocab, config.embed)
self.dropout = nn.Dropout(config.dropout)
self.fc1 = nn.Linear(config.embed * 3, config.hidden_size)
# self.dropout2 = nn.Dropout(config.dropout)
self.fc2 = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
out_word = self.embedding(x[0])
out_bigram = self.embedding_ngram2(x[2])
out_trigram = self.embedding_ngram3(x[3])
out = torch.cat((out_word, out_bigram, out_trigram), -1)
out = out.mean(dim=1)
out = self.dropout(out)
out = self.fc1(out)
out = F.relu(out)
out = self.fc2(out)
return out















 219
219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











