







自学网站:http://www.runoob.com/xpath/xpath-axes.html
在appium中只是使用xpath技术查找元素,其他的不适用
什么是xpath:XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。
一、选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
下面列出了最有用的路径表达式:
| 表达式 | 描述 |
| / | 从根节点选取。(绝对路径) |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。(相对路径) |
| . | 选取当前节点。(表示当前的) |
| .. | 选取当前节点的父节点。(当前目录或路径的上一级) |
| @ | 选取属性。 |
| [ ] | 索引,从1开始 |
| * | 表示所有,不限制元素的类型 |
实例
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
| 路径表达式 | 结果 |
| /html | 选取根元素 html。 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| html/body | 选取属于 html 的子元素的所有 body 元素。 |
| //div | 选取所有 div子元素,而不管它们在文档中的位置。 |
| //body//div | 选择属于 body 元素的后代的所有 div 元素,而不管它们位于 body 之下的什么位置。 |
| //@id | 选取有 id 属性的所有元素。 |
二、谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中
实例
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
| 路径表达式 | 结果 |
| /html/body/div[1] | 选取属于 body 子元素的第一个 div 元素。 |
| /html/body/div[last()] | 选取属于 body子元素的最后一个 div元素。 |
| /html/body/div[1]/div[last()-1] | 选取属于 body子元素的第一个div子元素的倒数第二个 div 元素。 |
| /html/body/div[1]/div[position()<3] | 选取属于 body子元素的第一个div子元素的前两个 div 元素。 Position表示的是一个位置 |
| //a[@id] | 选取所有具有id 的属性的 a 元素。 |
| //a[@id='nav_default'] | 选取所有 a 元素,且这些元素的id属性值为nav_default |
| //body//div[span>223] | 选取 body 元素下的所有 div 元素,且其中的 span 元素的值须大于 223。 |
| //body//div[span>22]/strong | 选取 body子元素中的 div元素下的所有 strong元素,且其中的 span元素的值须大于 223。 |
| //div[contains(@class’top’)] | 查找class包括top的元素 |
| //*[contains(@class’top’)] | 查找包括top的元素,不限制类型 |
三、选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
| //body/* | 选取 body 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //a[@*] | 选取所有带有属性的 a 元素。 |
四、选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
| //li | //ul | 选取所有的 li元素和 ul元素。 |
五、XPath 轴
轴可定义相对于当前节点的节点集。
| 轴名称 | 结果 |
| ancestor | 选取当前节点的所有先辈(父、祖父等)。不包自己 |
| ancestor-or-self | 选取当前节点的所有先辈(父、祖父等)以及当前节点本身。 |
| attribute | 选取当前节点的所有属性。 |
| child | 选取当前节点的所有子元素。 |
| descendant | 选取当前节点的所有后代元素(子、孙等)。 |
| descendant-or-self | 选取当前节点的所有后代元素(子、孙等)以及当前节点本身。 |
| following | 选取文档中当前节点的结束标签之后的所有节点。 |
| namespace | 选取当前节点的所有命名空间节点。 |
| parent | 选取当前节点的父节点。 |
| preceding | 选取文档中当前节点的开始标签之前的所有节点。 |
| preceding-sibling | 选取当前节点之前的所有同级节点。兄弟节点 |
| self | 选取当前节点。 |
实例
| 例子 | 结果 |
| //*[@id='course']/child::ul | 选取id值为course的元素的所有ul子元素。 |
| //div/attribute::id | 选取具有id属性的所有div元素 |
| //div[@id='course']/child::* | 选取id值为course的元素的所有子元素。 |
| //div[@id='course']/descendant::li | 选取id值为course的元素的所有后代li元素 |
| //*[@id='nav_default']/ancestor::li | 选择id为nav_default节点的所有 li 先辈。 |
| .//*[@id='nav_default']/parent::li | 选择id为nav_default节点的所有 li父元素。 |
| //div[@id='course']/preceding-sibling::* | 选择id为course元素的之前的所有同级元素,哥哥姐姐们 |
| //div[@id='course']/following-sibling::* | 选择id为course元素的之后的所有同级元素,弟弟妹妹们 |
六、自我实用总结
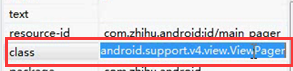
- <html> 标签相当于uiautomator中的class属性
Xpath中的根节点是<html>

Uiautomator根节点是class
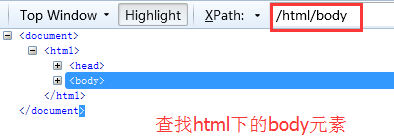
2、Xpath下查找html下的body元素
Uiautomator中的选择
/android.widget.FrameLayout/android.widget.LinearLayout

3、查找div标签
1)绝对路径: /html/body/div[2] 或 html/body/div[2]
2)相对路径: //body/div[2]
4. 查找所有的div标签

5. 查找统计所有的div标签

6. 查找具备id属性的div的标签

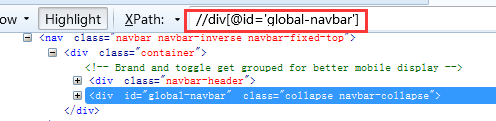
7、查找id属性等于global-navbar的div变迁
8、复制带空格的class属性,必须加两个空格

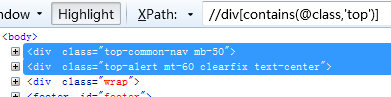
9. 在div标签中,查找class属性,class属性的值包含top的元素
10、查找最后一个div标签
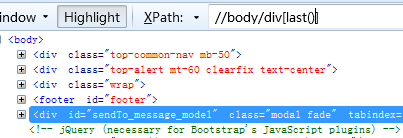
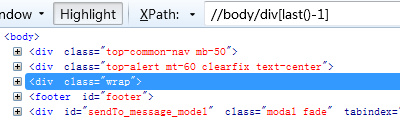
11、查找倒数第二个div标签
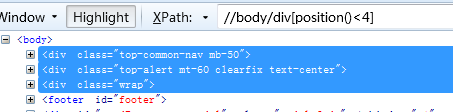
12、选择前三个,用position()
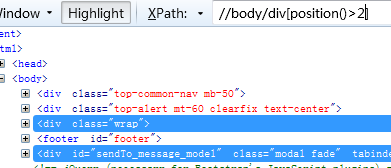
13、选择倒数两个div
14、选择body下所有的子元素(不包含body本身),不包含body子元素的子元素

15、查找body下所有的子元素和子元素的子元素

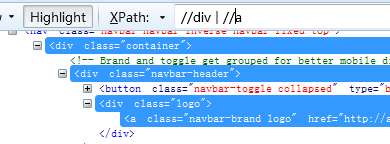
16、查找div标签或者a标签——》结果:就是a和div都会被找到
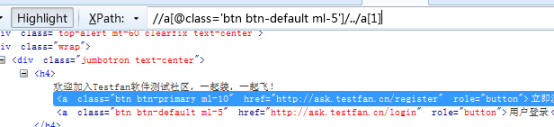
17、通过用户登录找到立即注册,找上级

先找到用户登录的上一级标签,通过上一级标签找到立即注册















 287
287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









