







-
@param directArena 线程使用的PoolArena.DirectArena
-
@param tinyCacheSize, tiny内存缓存的个数。默认为512
-
@param smallCacheSize small内存缓存的个数,默认为256个
-
@param normalCacheSize normalCacheSize缓存的个数,默认为64
-
@param maxCacheBufferCapacity
-
normalHeapCaches中单个缓存区域的最大大小,默认为32k 也就是normalHeapCaches[length-1]中缓存的最大内存空间 -
@param freeSweepAllocationThreshold 在本地线程每分配freeSweepAllocationThreshold 次内存后,检测一下是否需要释放内存。
*/
PoolThreadCache(PoolArena<byte[]> heapArena, PoolArena directArena,
int tinyCacheSize, int smallCacheSize, int normalCacheSize,
int maxCachedBufferCapacity, int freeSweepAllocationThreshold) {
if (maxCachedBufferCapacity < 0) {
throw new IllegalArgumentException("maxCachedBufferCapacity: "
- maxCachedBufferCapacity + " (expected: >= 0)");
}
if (freeSweepAllocationThreshold < 1) {
throw new IllegalArgumentException("freeSweepAllocationThreshold: "
- maxCachedBufferCapacity + " (expected: > 0)");
}
this.freeSweepAllocationThreshold = freeSweepAllocationThreshold;
this.heapArena = heapArena;
this.directArena = directArena;
if (directArena != null) {
tinySubPageDirectCaches = createSubPageCaches(tinyCacheSize, PoolArena.numTinySubpagePools);
smallSubPageDirectCaches = createSubPageCaches(smallCacheSize, directArena.numSmallSubpagePools);
numShiftsNormalDirect = log2(directArena.pageSize);
normalDirectCaches = createNormalCaches(
normalCacheSize, maxCachedBufferCapacity, directArena);
} else {
// No directArea is configured so just null out all caches
tinySubPageDirectCaches = null;
smallSubPageDirectCaches = null;
normalDirectCaches = null;
numShiftsNormalDirect = -1;
}
if (heapArena != null) {
// Create the caches for the heap allocations
tinySubPageHeapCaches = createSubPageCaches(tinyCacheSize, PoolArena.numTinySubpagePools);
smallSubPageHeapCaches = createSubPageCaches(smallCacheSize, heapArena.numSmallSubpagePools);
numShiftsNormalHeap = log2(heapArena.pageSize);
normalHeapCaches = createNormalCaches(
normalCacheSize, maxCachedBufferCapacity, heapArena); //@1
} else {
// No heapArea is configured so just null out all caches
tinySubPageHeapCaches = null;
smallSubPageHeapCaches = null;
normalHeapCaches = null;
numShiftsNormalHeap = -1;
}
// The thread-local cache will keep a list of pooled buffers which must be returned to
// the pool when the thread is not alive anymore.
ThreadDeathWatcher.watch(thread, freeTask);
}
在方法前,已经对构造方法的入参加了说明,关注如下两个方法。
代码@1:创建createNormalCaches 。
由于PoolThreadCache的设计理念与PoolArena一样,本身并不涉及到具体内存的存储,PoolThreadCache内部维护MemoryRegionCache[] tinySubpageHeapCaches,MemoryRegionCache[] smallSubpageHeapCaches,其数组长度与PoolArena相同,MemoryRegionCaches[] normalHeapCaches,缓存的是noraml内存,Netty把大于pageSize小于chunkSize的空间成为normal内存。normalHeapCaches[1] 是normalHeapCaches[0] 的2倍, 先重点关注PoolThreadCache createNormalCaches 源码:
private static NormalMemoryRegionCache[] createNormalCaches(
int cacheSize, int maxCachedBufferCapacity, PoolArena area) {
if (cacheSize > 0) {
int max = Math.min(area.chunkSize, maxCachedBufferCapacity); //@1
int arraySize = Math.max(1, max / area.pageSize); //@2
@SuppressWarnings(“unchecked”)
NormalMemoryRegionCache[] cache = new NormalMemoryRegionCache[arraySize];
for (int i = 0; i < cache.length; i++) {
cache[i] = new NormalMemoryRegionCache(cacheSize);
}
return cache;
} else {
return null;
}
}
参数 numCaches,为SubPageMemoryRegionCache[]数组的长度,而cacheSize,为每一个SubPageMemoryRegionCache中缓存的内存个数,也就是SubPageMemoryRegionCache中entries[]的长度。这里的cacheSize,就是PooledByteBufAllocator DEFAULT_TINY_CACHE_SIZE=512,DEFAULT_SMALL_CACHE_SIZE=256,DEFAULT_NORMAL_SIZE=64,其实这里的取名为DEFAULT_TINY_CACHE_LENGTH更加贴切。
代码@1:其实应该不需要与area.chunkSize做比较,因为如果超过chunkSize的内存,netty不会重复使用,直接在整个堆空间或堆外空间申请并释放。这里可能是出于代码的自我保护,得到normalHeapCaches中单个 Entry所持有的内存不超过该值。
代码@2:计算normalHeapCaches数组的长度,这里有优化的空间,用位运算:int arraySize = Math.max(1, max >> numShiftsNormalHeap ),其中numShiftsNormalHeap为 log2(pageSize)。这样做的原因,也就是normalHeapCaches 数组中的元素的大小,是以2的幂倍pageSize递增的。cacheSize默认为64,参数值来源于PooledByteBufAllocator。接下来关注PoolThreadCache的allocateTiny方法:
1.2 PoolThreadCache allocateTiny方法
/**
- Try to allocate a tiny buffer out of the cache. Returns {@code true} if successful {@code false} otherwise
*/
boolean allocateTiny(PoolArena<?> area, PooledByteBuf<?> buf, int reqCapacity, int normCapacity) {
return allocate(cacheForTiny(area, normCapacity), buf, reqCapacity);
}
private MemoryRegionCache<?> cacheForTiny(PoolArena<?> area, int normCapacity) {
int idx = PoolArena.tinyIdx(normCapacity);
if (area.isDirect()) {
return cache(tinySubPageDirectCaches, idx);
}
return cache(tinySubPageHeapCaches, idx);
}
/**
- Try to allocate a small buffer out of the cache. Returns {@code true} if successful {@code false} otherwise
*/
boolean allocateNormal(PoolArena<?> area, PooledByteBuf<?> buf, int reqCapacity, int normCapacity) {
return allocate(cacheForNormal(area, normCapacity), buf, reqCapacity);
}
private MemoryRegionCache<?> cacheForNormal(PoolArena<?> area, int normCapacity) {
if (area.isDirect()) {
int idx = log2(normCapacity >> numShiftsNormalDirect);
return cache(normalDirectCaches, idx);
}
int idx = log2(normCapacity >> numShiftsNormalHeap); //@1
return cache(normalHeapCaches, idx);
}
private boolean allocate(MemoryRegionCache<?> cache, PooledByteBuf buf, int reqCapacity) {
if (cache == null) {
// no cache found so just return false here
return false;
}
boolean allocated = cache.allocate(buf, reqCapacity); //@2
if (++ allocations >= freeSweepAllocationThreshold) {
allocations = 0;
trim(); //@3
}
return allocated;
}
代码@1:根据需要申请的内存定位数组的下标,根据上文讲解的数组长度计算逻辑,相应的定位算法就显而易见了。
代码@2:MeomoryRegionCache内部持有的 Entry entries[]数组是真正持有内存的单元,故现在将重点转移到MemoryRegionCache的讲解中。
代码@3:如果分配次数达到freeSweepAllocationThreshold,进行一次尝试释放一次。具体代码见 trim()方法的讲解。
1.2.1 关于PoolThreadCache allocateForTiny 之MemoryRegionCache 源码解读【针对1.2代码@2】
1)MemoryRegionCache属性与构造方法详解
private final Entry[] entries; //MemoryRegionCache真正持有内存的地方
/*
private static final class Entry {
PoolChunk chunk; //具体的PoolChunk
long handle; //内存持有偏移量,高32位保存的是bitmaIdx,低32位保存的是memoryMapIdx
}
*/
private final int maxUnusedCached; //表示允许的最大的没有使用的内存数量(已经被缓存),默认为size的一半。
private int head; // 作用类似于ByteBuf的readerIndex,从该位置获取一个缓存的Entiry。
private int tail; // 作用类似于ByteBuf的writerIndex,从该位置增加一个加入一个新的Entity
private int maxEntriesInUse; // 在使用中最大的entry数量
private int entriesInUse; // 目前使用中的entry数量
@SuppressWarnings(“unchecked”)
MemoryRegionCache(int size) { // size 默认的大小为 512, 256, 64
entries = new Entry[powerOfTwo(size)];
for (int i = 0; i < entries.length; i++) {
entries[i] = new Entry();
}
maxUnusedCached = size / 2; //允许被缓存,但没有使用的最大数量,超过该值,则会触发内存释放操作。
}
初始状态的MemoryRegionCache的各个属性的值分别为:
maxUnusedCached : 256,128,32,为size的一半;head:0 ;tail:0 ; maxEntriesInUse : 0; entriesInUse : 0
2)MemoryRegionCache的allocate方法详解
/**
- Allocate something out of the cache if possible and remove the entry from the cache.
*/
public boolean allocate(PooledByteBuf buf, int reqCapacity) {
Entry entry = entries[head]; //@1
if (entry.chunk == null) { //@2
return false;
}
entriesInUse ++; //@3
if (maxEntriesInUse < entriesInUse) {
maxEntriesInUse = entriesInUse;
}
initBuf(entry.chunk, entry.handle, buf, reqCapacity); //@4
// only null out the chunk as we only use the chunk to check if the buffer is full or not.
entry.chunk = null; //@5
head = nextIdx(head); //@6
return true;
}
代码@1:从entries数组中获取一个entry,head指针表示下一个缓存的Entry。
代码@2:如果entry.chunk为空,则表示线程里暂未缓存内存,返回false,表示从本地线程中分配失败。
代码@3:每分配出一个Entry,则entriesInUse加1,表示正在使用的entry个数。
代码@5:用entry中的内存初始化ByteBuf。
代码@6:head指针加一,如果超过entries的length,则重新从0开始,其实也就是 (head + 1) % (entires.length - 1),这里使用的是位运算。如果成功分配,则返回true, 结束本次内存的分配。
1.2.3 关于PoolThreadCache allocateForTiny 之代码@3,trim方法详解:
该方法的目的是在本地线程分配达到一定次数后,检测一下从本地线程缓存分配的效率,如果总是分配不到,就是虽然本地有缓存一定的内存,但每次分配都没有找到合适内存供分配,此时需要释内存回全局分配池,避免浪费内存。
void trim() {
trim(tinySubPageDirectCaches);
trim(smallSubPageDirectCaches);
trim(normalDirectCaches);
trim(tinySubPageHeapCaches);
trim(smallSubPageHeapCaches);
trim(normalHeapCaches);
}
private static void trim(MemoryRegionCache<?>[] caches) {
if (caches == null) {
return;
}
for (MemoryRegionCache<?> c: caches) {
trim©;
}
}
private static void trim(MemoryRegionCache<?> cache) {
if (cache == null) {
return;
}
cache.trim();
}
trim的具体实现是MemoryRegionCache,现在进入到MemoryRegionCache详解:
/**
- Free up cached {@link PoolChunk}s if not allocated frequently enough.
*/
private void trim() {
int free = size() - maxEntriesInUse; //@1
entriesInUse = 0;
maxEntriesInUse = 0; //@2
if (free <= maxUnusedCached) { //@3
return;
}
int i = head;
for (; free > 0; free–) {
if (!freeEntry(entries[i])) {
// all freed
break;
}
i = nextIdx(i);
}
// Update head to point to te correct entry
// See https://github.com/netty/netty/issues/2924
head = i;
}
在进行该方法的实现逻辑之前,我先提供一张草图,形象的反映head,tail等说明:
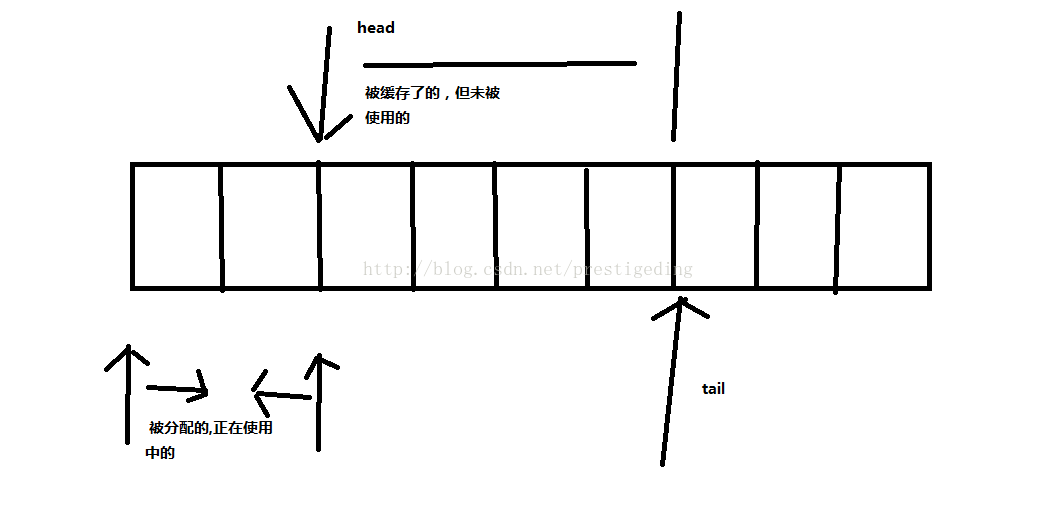
代码@1:size()方法返回的是 (tail-head) & (length-1),表示当前缓存了但未被使用的个数。maxEntriesInUse的值,其实就是entiryesInUse的值。
代码@2:代码@3,如果缓存的并且未使用的个数如果小于允许的值(maxUnusedCached)值是放弃本次内存释放,否则,需要将head到tail这部分的内存全部释放,返回给全局内存分配池。这里我可能没有理解透彻,如果是我实现的话,entriesInUse该值不会设置为空,而是直接释放掉 tail-head这部分的内存就好,释放算法在内存分配与释放篇已经做过详细解读,这里不重复讲解:
@SuppressWarnings({ “unchecked”, “rawtypes” })
private static boolean freeEntry(Entry entry) {
PoolChunk chunk = entry.chunk;
if (chunk == null) {
return false;
}
// need to synchronize on the area from which it was allocated before.
synchronized (chunk.arena) {
chunk.parent.free(chunk, entry.handle);
}
entry.chunk = null;
return true;
}
扫描一下MemoryRegionCache类,还有一个方法我们未曾分析过,就是add方法,默认一开始MemoryRegionCache类中的Entry[] entries中的PoolChunk与handle都是空的,只有通过该add方法,将线程用过的内存缓存起来才能重复使用。我们要养成这样一个习惯,一个ByteBuf用过后,需要调用realse方法将其释放,具体到池化的PooledByteBuf,调用其realse方法,并不会将内存直接返还给JVM堆,而是放入到内存池,供重复使用,由于引入了线程本地缓存,所以在调用PooledByteBuf的release方法时,并不会将它立马返回给内存池(PoolArena),而是放入到本地线程缓存中。
/**
- Add to cache if not already full.
*/
public boolean add(PoolChunk chunk, long handle) {
Entry entry = entries[tail];
if (entry.chunk != null) {
// cache is full
return false;
}
entriesInUse --;
entry.chunk = chunk;
entry.handle = handle;
tail = nextIdx(tail);
return true;
}
本地线程池关于内存的分配与释放旧梳理到这里了。
2、PooledByteBuf线程本地缓存专题(线程对象池)
==============================
到目前为止,我们更加关注的是PooledByteBuf内部持有的内存的管理,重复利用,显然Netty并不满足与此,PooledByteBuf本身是否也可以缓存呢?是的,一样可以缓存,并且netty从PooledByteBuf对象本身,指向的内存从两个方面进行缓存,回收利用,并不是将单一某个面进行一起缓存。下文,将从PooledByteBuf对象的回收利用这一层面进行Netty本地线程池来进行PooledByteBuf的重复利用。重复声明一下,PooledByteBuf对象池中缓存的PooledByteBuf,并没有任何缓存区(byte[]或java.nio.ByteBuffer)关联,只是PooledByteBuf本身,从对象池中获取一个PooledByteBuf后,还需要调用initBuf等方法进行内存的分配。
请看如下代码片段:来自PooledHeapByteBuf:
private static final Recycler RECYCLER = new Recycler() {
@Override
protected PooledHeapByteBuf newObject(Handle handle) {
return new PooledHeapByteBuf(handle, 0);
}
};//@2
static PooledHeapByteBuf newInstance(int maxCapacity) {
PooledHeapByteBuf buf = RECYCLER.get(); //@1
buf.setRefCnt(1);
buf.maxCapacity(maxCapacity);
return buf;
}
关注代码@1,@2创建一个PooledHeapByteBuf,是从一个静态变量 RECYLER的get方法中获取,代码@2的写法是不是和ThreadLocal的使用非常类似,所以本专题的主角,就非Recycler莫属了。
2.1 Recycler构造方法核心属性
private static final int DEFAULT_MAX_CAPACITY; //对象池默认的最大容量
private static final int INITIAL_CAPACITY; //初始容量
private final int maxCapacity; //对象池的容量,由构造方法中进行初始化,默认为DEFAULT_MAX_CAPACITY。
private final FastThreadLocal<Stack> threadLocal = new FastThreadLocal<Stack>() {
@Override
protected Stack initialValue() {
return new Stack(Recycler.this, Thread.currentThread(), maxCapacity);
}
};
Recycler不是一普通的对象池,而是基于线程本地变量(缓存)实现的对象池,所以此处的threadLocal是Recycler中至关重要的数据结构。我们可以看出,Recycler为每个线程保持的是一叫Stack的对象。先跳过Statck,我们看一下Recycler对外提供了哪些方法供我们使用:
@SuppressWarnings(“unchecked”)
public final T get() {
Stack stack = threadLocal.get();
DefaultHandle handle = stack.pop();
if (handle == null) {
handle = stack.newHandle();
handle.value = newObject(handle);
}
return (T) handle.value;
}
public final boolean recycle(T o, Handle handle) {
DefaultHandle h = (DefaultHandle) handle;
if (h.stack.parent != this) {
return false;
}
h.recycle(o);
return true;
}
看到这里,为了摸清楚Recycler的内部实现原理,我们只能将目光先投向Stack类。但一看又发现Statck内部维护着这样一个数据结构:DefaultHandle<?>[] elements;也就是一个Statck类维护这样一个DefaultHandle数组,所以,我们先将目光锁定在DefaultHandle上:
2.2 DefaultHandle源码详解
DefaultHandle,是对象池中最基本的单元,由该对象包裹着实际缓存的对象。
public interface Handle { //负责对象回收接口
void recycle(T object);
}
static final class DefaultHandle implements Handle {
private int lastRecycledId; //@1
private int recycleId; //@2,这两个属性待分解
private Stack<?> stack; //该Handle所在的Statck对象,上面也谈到,Statck维护一个Handle数组
private Object value; //该对象就是对象池缓存的对象,这里用 private T value更合适。
DefaultHandle(Stack<?> stack) { // 构造函数
this.stack = stack;
}
@Override
public void recycle(Object object) {
最后
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长,自己不成体系的自学效果低效漫长且无助。
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,不论你是刚入门Java开发的新手,还是希望在技术上不断提升的资深开发者,这些资料都将为你打开新的学习之门!
如果你觉得这些内容对你有帮助,需要这份全套学习资料的朋友可以戳我获取!!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
//该对象就是对象池缓存的对象,这里用 private T value更合适。
DefaultHandle(Stack<?> stack) { // 构造函数
this.stack = stack;
}
@Override
public void recycle(Object object) {
最后
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长,自己不成体系的自学效果低效漫长且无助。
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
[外链图片转存中…(img-GpGYdPhH-1715854087662)]
[外链图片转存中…(img-7RAVmFWv-1715854087663)]
[外链图片转存中…(img-n5Dnhrgb-1715854087663)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,不论你是刚入门Java开发的新手,还是希望在技术上不断提升的资深开发者,这些资料都将为你打开新的学习之门!
如果你觉得这些内容对你有帮助,需要这份全套学习资料的朋友可以戳我获取!!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!














 1508
1508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









