







 文章详细介绍了MuGo这一AI围棋程序的实现,包括围棋术语、源码结构、输入数据特征、主要类和数据结构,特别是蒙特卡洛树搜索(MCTS)的落子策略。通过MCTS和策略网络,MuGo选择最佳下一手。此外,文章还提及了模型的搭建和训练过程。
文章详细介绍了MuGo这一AI围棋程序的实现,包括围棋术语、源码结构、输入数据特征、主要类和数据结构,特别是蒙特卡洛树搜索(MCTS)的落子策略。通过MCTS和策略网络,MuGo选择最佳下一手。此外,文章还提及了模型的搭建和训练过程。
文章目录
前言
自从AlphaGo横空出世,战胜李世石后,AI围棋如雨后春笋一般遍地开花。阅读DeepMind的论文有时还是隔靴搔痒,只有钻到代码里,才能一探究竟。于是,我选择了相对比较容易上手的MuGo作为研究起点。研究AlphaGo/AlphaZero实现原理,一方面是出于对AI围棋的兴趣,另一方面顺带加深对tensorflow等框架的了解。
围棋术语介绍
AI围棋源码中经常出现的几个词汇,解释如下:
- komi: 贴目,黑棋贴还给白棋的目数
- liberty: 气,一块棋要在棋盘上存活,需要有气,气为0就得被提掉
- ladder cap:征子。棋子被打吃时,如果逃跑,则对方一直叫吃,直到逃跑棋子达到棋盘底线而无处可逃,最终被吃掉。围棋里把这种吃子方式叫征吃,或征子
- ladder escape:征子逃跑,或引征。在逃跑路线上,遇到己方有棋子接应,就能逃出征子而不被吃掉;如果遇到对方的棋子,则不用等达到棋盘边界就被吃。
源码实现
MuGo的代码不多,源文件一共8个。
| 文件名 | 介绍 |
|---|---|
| features.py | 特征平面定义 |
| go.py | 棋盘设置,各种判断,如落子合法性,气的计算 |
| load_data_sets.py | 加载棋谱文件 |
| main.py | 主程序,接收命令行参数,完成预处理、训练、对弈三大功能 |
| policy.py | 神经网络即策略网络的搭建 |
| sgf_wrapper.py | sgf棋谱文件解析 |
| strategies.py | MCTS结构定义,Player定义 |
| utils.py | 辅助函数,如棋盘坐标转换 |
MuGo的输入数据
在features.py文件中,MuGo一共定义了十多个特征作为神经网络的输入:
| 特征 | 说明 | 特征平面个数 |
|---|---|---|
| 落子颜色 | Player stones; 对手. 自己; 空 | 3 |
| Ones | 全1的特征平面,让神经网络借此知道棋盘边界 | 1 |
| 最近落子回合数 | How many turns since a move played | 8 |
| 棋子的气 | 棋子的气数 | 8 |
| 对方将被提子数 | 多少棋子将被吃掉 | 8 |
| 自方将被提子数 | 多少己方的棋子将被吃掉 | 8 |
| 落子后的气 | Number of liberties after this move played | 8 |
| 是否为征子 | Whether a move is a successful ladder cap | 1 |
| 是否为逃征子 | Whether a move is a successful ladder escape | 1 |
| 是否为合法落子 | 合法落子不能填自己的眼,也不能被对手提掉 | 1 |
| Zeros | 全0的平面 | 1 |
一个特征平面用1x361向量来表示,特征平面个数是指需要多少个这样的向量。例如,最近落子回合数用八个特征平面表示,也就是仅记录最近八个回合的落子信息,每一步占一个特征平面。
主要类和数据结构
棋盘和落子
- 一个棋盘(board)用一个 NxN numpy 数组表示, 默认N=19,为19路棋盘
- 棋盘坐标(Coordinate): 采用元组(x, y)表示棋盘上某个坐标
- 落子(Move): 采用 (Coordinate c | None) 表示
- 走子(PlayerMove): 一个(Color, Move) 元组
(0, 0)为棋盘左上角 ,(18, 0) 为棋盘左下角。
初始化棋盘(在go.py中)
def set_board_size(n):
'''
Hopefully nobody tries to run both 9x9 and 19x19 game instances at once.
Also, never do "from go import N, W, ALL_COORDS, EMPTY_BOARD".
'''
global N, ALL_COORDS, EMPTY_BOARD, NEIGHBORS, DIAGONALS
if N == n: return
N = n
ALL_COORDS = [(i, j) for i in range(n) for j in range(n)]
EMPTY_BOARD = np.zeros([n, n], dtype=np.int8)
def check_bounds(c):
return c[0] % n == c[0] and c[1] % n == c[1]
NEIGHBORS = {(x, y): list(filter(check_bounds, [(x+1, y), (x-1, y), (x, y+1), (x, y-1)])) for x, y in ALL_COORDS} ## 所有坐标的相邻坐标,用来计算气
DIAGONALS = {(x, y): list(filter(check_bounds, [(x+1, y+1), (x+1, y-1), (x-1, y+1), (x-1, y-1)])) for x, y in ALL_COORDS} ## 每个坐标的四个对角线相邻坐标
获得相连棋子串(长的串俗称“大龙”)
## 采用BFS算法,将相同颜色的相连棋子加入到chain串,相连但不同颜色的棋子加入到reached串
def find_reached(board, c):
color = board[c]
chain = set([c])
reached = set()
frontier = [c]
while frontier:
current = frontier.pop()
chain.add(current)
for n in NEIGHBORS[current]:
if board[n] == color and not n in chain:
frontier.append(n)
elif board[n] != color:
reached.add(n)
return chain, reached
Group定义了一块棋,具有相同颜色,且里面棋子相连
class Group(namedtuple('Group', ['id', 'stones', 'liberties', 'color'])):
def __eq__(self, other):
return self.stones == other.stones and self.liberties == other.liberties and self.color == other.color
LibertyTracker类
该类维护着棋盘上有多少块棋,每块棋为一个Group对象,以及棋盘上每个棋子的气数,每个棋子的气数等于所在group的气数。
每次走子时,会调用add_stone()方法,更新上述信息。
Position类
该类代表对弈中某个局面的信息,包括:
- 整个棋盘的状态
- 当前第多少手
- 黑白双方被提掉的棋子数
- 所有棋块
- 是否存在打劫
- 最近的落子,保存在tuple中,例如recent[-1]为最近一次落子
- 下一步轮到谁走
蒙特卡洛(MCTS)落子
有了features.py和go.py里的定义,我们就把下棋这件事数字化了。但围棋的关键在于“下一手”怎么选取。接下来看看strategies.py这个模块怎么实现的。
MCTSNode类
class MCTSNode():
def __init__(self, parent, move, prior):
self.parent = parent # pointer to another MCTSNode
self.move = move # the move that led to this node
self.prior = prior
self.position = None # lazily computed upon expansion
self.children = {} # map of moves to resulting MCTSNode
self.Q = self.parent.Q if self.parent is not None else 0 # average of all outcomes involving this node
self.U = prior # monte carlo exploration bonus
self.N = 0 # number of times node was visited
每个节点都存储了三个重要数值:Q代表XXX,U代表该节点的奖励,N代表访问次数
每步棋的价值:
@property
def action_score(self):
# Note to self: after adding value network, must calculate
# self.Q = weighted_average(avg(values), avg(rollouts)),
# as opposed to avg(map(weighted_average, values, rollouts))
return self.Q + self.U
蒙特卡洛搜索树包含两个重要的过程: 扩展expand()和反向传播backup_value()。
蒙特卡洛采用快速走子(fast rollout)策略完成一次棋局模拟。
def backup_value(self, value):
self.N += 1
if self.parent is None:
# No point in updating Q / U values for root, since they are
# used to decide between children nodes.
return
self.Q, self.U = (
self.Q + (value - self.Q) / self.N,
c_PUCT * math.sqrt(self.parent.N) * self.prior / self.N,
)
# must invert, because alternate layers have opposite desires
self.parent.backup_value(-value)
Q的计算公式:
s
e
l
f
.
Q
+
v
a
l
u
e
−
s
e
l
f
.
Q
s
e
l
f
.
N
self.Q + \frac {value - self.Q} {self.N}
self.Q+self.Nvalue−self.Q
U的计算公式:
c
_
P
U
C
T
∗
s
e
l
f
.
p
a
r
e
n
t
.
N
∗
s
e
l
f
.
p
r
i
o
r
s
e
l
f
.
N
\frac {c\_PUCT \ast \sqrt {self.parent.N} \ast self.prior} {self.N}
self.Nc_PUCT∗self.parent.N∗self.prior
这里,MuGo的c_PUCT为一个常数5。
Upper Confidence Bounds(置信上限), UCT = 树的置信上限(UCB for Trees)
UCT是一个让我们从已访问的节点中选择下一个节点来进行遍历的函数,也是MCTS的核心函数。
粗略地理解,就是MuGo根据策略网络选择可能的下一步选点,策略网络返回的是move_probabilities,即可能的落子选项(move, 赢棋概率)的集合。然后对MCTS树进行扩展,再根据棋局胜负结果反向更新各个节点的value,以此推断出胜率最高的“下一手”。
选择下一手的实现在类MCTS中。
class MCTS(GtpInterface) 类
该类其实就是一个具备了结合策略网络和蒙特卡洛搜索树行棋的棋手(Player)的化身。
class MCTS(GtpInterface):
def __init__(self, policy_network, read_file, seconds_per_move=5):
## 借助一个策略网络和模型文件完成初始化
def suggest_move(self, position):
## 在局面position下选择最好的下一步
def tree_search(self, root):
...
## 这里只列出关键逻辑
# backup
move_probs = self.policy_network.run(position) ## 根据策略网络得到落子选项
chosen_leaf.expand(move_probs) ## 扩展节点, chosen_leaf为root的价值最大的叶子节点
# evaluation
value = self.estimate_value(root, chosen_leaf) ## 评估选中的节点的价值
print("value: %s" % value, file=sys.stderr)
chosen_leaf.backup_value(value) ## 反向更新父节点的价值
def estimate_value(self, root, chosen_leaf):
# Estimate value of position using rollout only (for now).
# (TODO: Value network; average the value estimations from rollout + value network)
leaf_position = chosen_leaf.position
current = copy.deepcopy(leaf_position)
while current.n < self.max_rollout_depth:
move_probs = self.policy_network.run(current)
current = self.play_valid_move(current, move_probs)
if len(current.recent) > 2 and current.recent[-1].move == current.recent[-2].move == None:
break
else:
print("max rollout depth exceeded!", file=sys.stderr)
perspective = 1 if leaf_position.to_play == root.position.to_play else -1
return current.score() * perspective
策略网络又是如何得出落子选项的呢?咱们接着往下看。
模型的搭建
整个网络通过五个卷积层,输出落子概率。
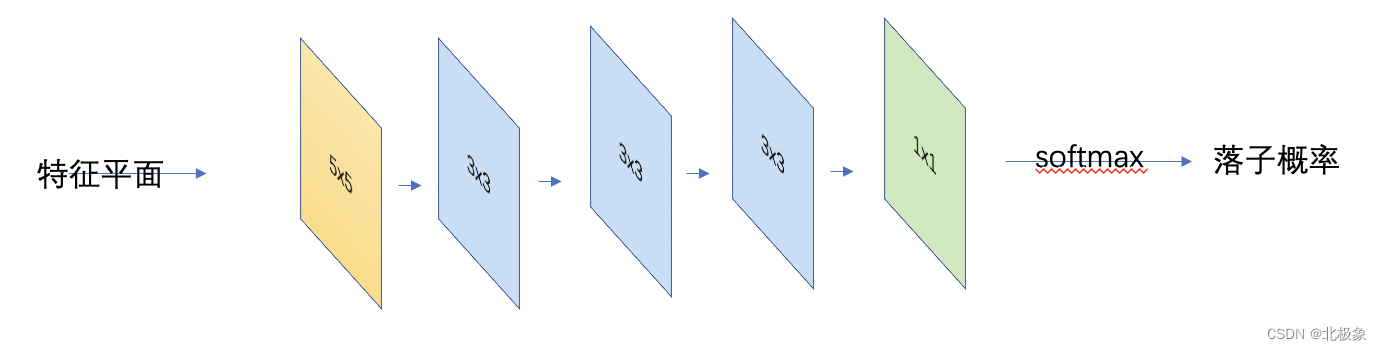
初始的卷积核是5x5,后面接三个3x3的卷积层,最后输出层的卷积核为1x1,通过softmax做归一化处理后,得出落子概率。
log_likelihood_cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y))
train_step = tf.compat.v1.train.AdamOptimizer(1e-4).minimize(log_likelihood_cost, global_step=global_step)
was_correct = tf.equal(tf.argmax(logits, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(was_correct, tf.float32))
优化函数为softmax_cross_entropy_with_logits(),计算当前局面卷积神经网络给的落子概率和人类棋谱的下一步之间的损失。
注意:一张棋谱能产生多个局面和下一步的数据。
模型的训练
def train(self, training_data, batch_size=32):
num_minibatches = training_data.data_size // batch_size
for i in range(num_minibatches):
batch_x, batch_y = training_data.get_batch(batch_size)
_, accuracy, cost = self.session.run(
[self.train_step, self.accuracy, self.log_likelihood_cost],
feed_dict={self.x: batch_x, self.y: batch_y})
self.training_stats.report(accuracy, cost)
avg_accuracy, avg_cost, accuracy_summaries = self.training_stats.collect()
global_step = self.get_global_step()
print("Step %d training data accuracy: %g; cost: %g" % (global_step, avg_accuracy, avg_cost))
if self.training_summary_writer is not None:
activation_summaries = self.session.run(
self.activation_summaries,
feed_dict={self.x: batch_x, self.y: batch_y})
self.training_summary_writer.add_summary(activation_summaries, global_step)
self.training_summary_writer.add_summary(accuracy_summaries, global_step)
获得某个局面position下的落子概率:
def run(self, position):
'Return a sorted list of (probability, move) tuples'
processed_position = features.extract_features(position, features=self.features)
probabilities = self.session.run(self.output, feed_dict={self.x: processed_position[None, :]})[0]
return probabilities.reshape([go.N, go.N])
对弈过程
对于某个给定的局面,通过策略网络得到可能的选点,然后通过MCTS搜索分别计算每个选点的价值,最终选择价值最大的选点。
附录:围棋常用术语英文
a(large) group of stones 一条(大)龙
alive活(棋)
aji味
areas实地
atari打吃
Baduk围棋
Black黑棋
board棋盘
bowl棋盒
capture提子
capturingraces 对杀
compensationpoints 贴目
connection连接
corner角
dame单官
dan(业余/职业)()段
danpro 职业()段
dead死(棋)
divinemove 胜负手
edge边
eye眼
falseeyes 假眼
fiveby five 五五
forcingmoves 劫财
fuseki布局
Go围棋
gote后手
gridsize 棋盘尺寸(9X9,13X13,19X19)
handicap泛指包括让子和贴目等形式在内的指导棋
hane扳
hayago快棋
higheye 高目
highkakari 高挂
Igo围棋
influence-orientedapproach 注重外势
jigo和棋
joseki定石/定式
jungsuk定石/定式
kakari挂
kifu棋谱
ko劫
kofights 打劫
komi贴目
korigatachi愚形
kosumi小尖
kyu级
ladder征子
largehigh eye 超高目
liberties气
lightness薄
lowkakari 低挂
miai见合
monkeyjump 伸腿
move一招棋、一手棋
moyo模样
myoushu妙手
nakade点杀
net枷吃
nidanbane 连扳
originof heaven 天元
outsidethe eye 目外
outsidethe large eye 超目外
pass停一手
rank级别、段位
resignation投子认负
rule-sets(中国/日本/韩国)规则
score点目
seki双活
sente先手
separation分离/分断
shape棋形
side边
smalleye 小目
snapback倒扑
starpoint 星位
stone棋子
tengen天元
territorialapproach 注重实地
territories实地
tesuji手筋
thickness厚实
threeby three 三三
tsumego诘棋/死活题
Weiqi围棋
White白棋
yose官子
yosu miru 试应手
参考链接
结语
本文还在写作中,TODO



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











