




 本文详细介绍了AlphaGo的棋盘编码器、网络架构,包括强策略网络、快策略网络和价值网络。重点阐述了策略网络的训练,包括监督学习初始化、自我对弈和策略梯度算法。此外,还讨论了价值网络的训练和蒙特卡洛树搜索的实现,包括搜索新棋局、模拟对弈和节点数据更新。AlphaGo的改进版蒙特卡洛树搜索结合了神经网络,增强了搜索算法的效率和准确性。
本文详细介绍了AlphaGo的棋盘编码器、网络架构,包括强策略网络、快策略网络和价值网络。重点阐述了策略网络的训练,包括监督学习初始化、自我对弈和策略梯度算法。此外,还讨论了价值网络的训练和蒙特卡洛树搜索的实现,包括搜索新棋局、模拟对弈和节点数据更新。AlphaGo的改进版蒙特卡洛树搜索结合了神经网络,增强了搜索算法的效率和准确性。
1. 棋盘编码器
AlphaGo所采用的棋盘编码器为 19×19×49 的特征张量,其中前48个平面用于策略网络的训练,最后一个平面用于价值网络的训练。前48个平面包含11种概念,其更多地利用了围棋专有的定式,例如它在特征集合中引入了征子和引征的概念。最后一个平面用来表示当前执子方。
AlphaGo的棋盘编码器也采用了二元特征,它用8个平面分别代表每个棋子是否有1口、2口…和至少8口气。AlphaGo 所使用的特征平面的分类和解释如下:

2. AlphaGo的网络架构
AlphaGo一共使用了三个神经网络,包括2两个策略网络和1个价值网络。其中策略网络分为快策略网络和强策略网络。快策略网络的主要作用是为了在保证一定高的预测准确率的情况下同时能够非常迅速地做出动作预测。与之相反,强策略网络的优化目标是准确率而不是预测速度,其网络更深且预测效果比快策略网络好2倍。最后价值网络用来评判当前棋盘状态的好坏,其使用强策略网络的自我对弈产生的数据集训练出来的。接下来我们分别看一下这三种网络。
(1)强策略网络
强策略网络一共有13层卷机网络,且在整个网络的训练过程中,都保留的原始的19×19的大小,因此我们需要对中间卷机层进行paddinga操作。此外第一个层卷积核的大小为5,剩下12层的卷积核的大小为3,最后一层的卷积核大小为1,且只有一个过滤器。关于激活函数,前12层都采用Relu激活函数,最后一层由于要得出每个位置的概率值,因此采用softmax 激活函数。强策略网络使用keras实现如下:
model = Sequential()
model.add(
Conv2D(192, 5, input_shape=input_shape, padding="same", data_format='channels_first', activation='relu')
)
for i in range(2, 12):
model.add(
Conv2D(192, 3, padding='same', data_format='channels_first', activation='relu')
)
model.add(
Conv2D(filters=1, kernel_size=1, padding='same', data_format='channels_first', activation='softmax')
)
model.add(Flatten())
(2)快策略网络
由于快策略网络的主要目的是构建一个比强策略网络更小的网络,从而能够进行快速评估,因此读者可以自行创建一个简易的网络从而实现此功能,这里就不做示例。
(3)价值网络
价值网络总共有16层卷机网络,其中前12层与强策略网络完全一致,第13层是一个额外的卷机层,与第2~12层的结构一致,而第14层的卷积核大小为1,并且有一个过滤器。最后是两层稠密层,倒是第二层共有256个输出,采用ReLU几何函数;最后一层只有一个输出,表示当前状态的价值,采用tanh激活函数。需要注意的是价值网路的输入维度和策略网络的输入维度不同,前面我们知道价值网络的输入比策略网络的输入多一层特征值用来记录当前执子方。价值网络使用keras实现如下:
model = Sequential()
model.add(
Conv2D(192, 5, input_shape=input_shape, padding="same", data_format='channels_first', activation='relu')
)
for i in range(2, 13):
model.add(
Conv2D(192, 3, padding='same', data_format='channels_first', activation='relu')
)
model.add(
Conv2D(filters=1, kernel_size=1, padding='same', data_format='channels_first', activation='relu')
)
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(1, activation='tanh'))
3. 策略网络的训练
(1) 监督学习初始化策略网络(behavior cloning)
AlphaGo最开始使用监督学习方法对策略网络进行预训练,每个游戏状态编码为一个张量,而训练所使用的标签是一个与棋盘尺寸相同的向量,并在实际动作落子处填入1,其余位置为0,训练流程图如下:
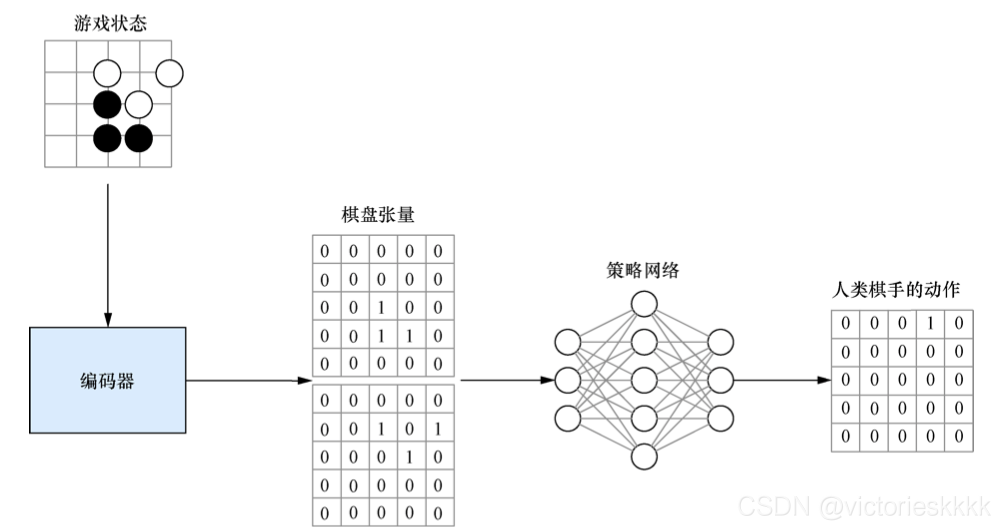
我们用同样的方法训练强策略网络和快策略网络,通过监督学习训练的网络已经可以很大概率地打败业余玩家了,但是如果想要赢得职业玩家还需要继续进行提升。
(2) 自我对弈(self-play)
DeepMind使用多个不同版本的强策略网络与当前最强版本的强策略网络进行对弈,这么做能够防止过拟合并且在总体上能够得到更好的表现。在这里我们采用更简单的方法,直接让上面训练好的强策略网络进行自我对弈,机器人对弈的代码如下:
def simulate_game(black_player, white_player, board_size):
game = GameState.new_game(board_size)
moves = []
agents = {
Player.black: black_player,
Player.white: white_player,
}
while not game.is_over():
next_move = agents[game.next_player].select_move(game)
moves.append(next_move)
game = game.after_move(next_move)
game_result = scoring.compute_game_result(game)
return game_result
def experience_simulator(num_games, agent1, agent2):
collector1 = experience.ExperienceCollector()
collector2 = experience.ExperienceCollector()
color = Player.black
for i in range(num_games):
collector1.begin_episode()
collector2.begin_episode()
agent1.set_collector(collector1)
agent2.set_collector(collector2)
if color == Player.black:
black_player, white_player = agent1, agent2
else:
black_player, white_player = agent2, agent1
game_record = simulate_game(black_player, white_player)
if game_record.winner == color:
collector1.complete_episode(reward=1)
collector2.complete_episode(reward=-1)
else:
collector1.complete_episode(reward=-1)
collector2.complete_episode(reward=1)
color = color.other
return experience.combine_experience([collector1, collector2])
代码中的‘ExperienceCollector’类用于储存和处理对弈过程中生成的棋谱状态,相应的动作以及动作奖励的数据序列 ( s 1 , a 1 , r 1 , s 2 , . . . , s t , a t ) (s_{1}, a_{1}, r_{1}, s_{2},..., s_{t}, a_{t}) (s1,a1,r1,s2,...,st,at)。其中每个动作的奖励取决于胜负。具体而言,如果此轮博弈player获得胜利,那么player所有的动作奖励值都为1,否则为-1。每一轮次比赛结束后,(状态,动作,奖励)序列值都会存储到player和opponent的经验收集器中,双方的经验值可以结合一起用于之后训练的数据集。在实现指定轮次的对弈之后,我们用其生成的经验值训练强策略网络。
(3) 策略剃度算法训练策略网络(Policy Gradient)
在讨论策略梯度算法之前,我们先了解一下策略学习(Policy- Based Reinforcement Learning), 策略学习通过使用神经网络估计策略函数(policy function), 从而进一步的估计状态价值函数(state-value function):
V ( s ; θ ) = ∑ a π ( a ∣ s ; θ ) . Q
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 449
449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









