






https://medium.com/@simpsons/apache-hudi-compaction-6e6383790234
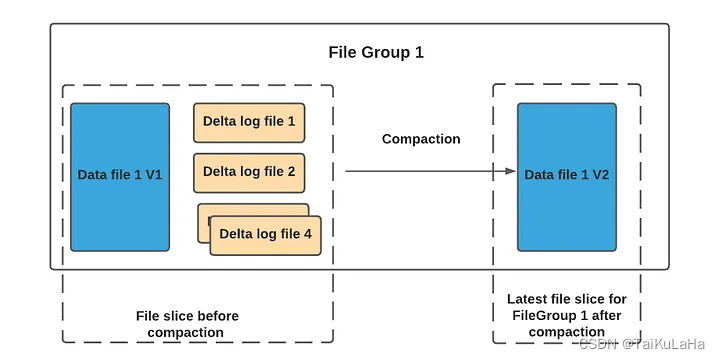
While serving the read query(snapshot read), for each file group, records in base file and all its constituent log files are merged together and served. And hence the read latency for MOR snapshot query might be higher compared to COW table since there is no merge involved incase of COW.
Hudi employs a table service called COMPACTION to compact these base files and log files to form a compacted new version of the file slice which contains only a base file. Compaction has to happen at regular intervals to bound the growth of log files and to ensure the read latencies does not spike up.
使用 Amazon EMR Studio 探索 Apache Hudi 核心概念 (3) – Compaction
https://aws.amazon.com/cn/blogs/china/exploring-apache-hudi-core-concepts-with-amazon-emr-studio-3-compaction/














 1432
1432











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









