







c语言编译过程
最近面试也算是告一段落,沉下心来继续学习.这段时间在看一些编译的东西,写出来大家互相学习.
PS:系统版本出问题了,打不出英文符号…
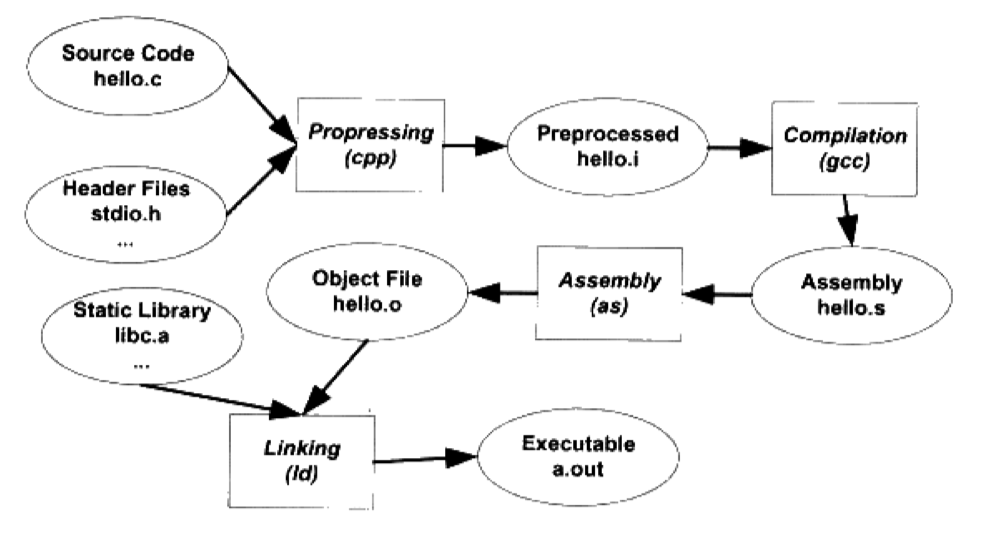
c语言的编译过程可以分为预处理、编译、汇编、链接四个步骤,接下来我们就一一介绍.
我们以一个具体的例子来讲解
#include <stdio.h>
#define test 1
#define max(a,b) ((a)>(b)) ? (a) : (b)
int main()
{
int a = max(1,2);
printf("hello world!\n");
return 0;
}
预处理
C 预处理器只不过是一个文本替换工具而已,它们会指示编译器在实际编译之前完成所需的预处理。主要处理的是源代码文件中#开始的预编译指令,不会检查语法错误。
编译的命令是gcc -E main.c -o main.i,我们简单看一下.i文件
❯ file a.i
a.i: C source, ASCII text
可以看出.i文件还是c语言文件,具体看下其中的内容
792 # 2 "a.c" 2
793
794
795
796
797
798 # 6 "a.c"
799 int main()
800 {
801 int a = ((1)>(2)) ? (1) : (2);
802 printf("hello world!\n");
803 return 0;
804 }
简单的10多行的代码在这一过程中会变成800+行,前面的都是从stdio.h中复制过来的函数接口的声明,而最后几行是我们的代码的展开,可以看出预处理阶段的主要工作是完成对预处理命令的展开.
编译
编译过程是将文本文件转换为机器语言-汇编语言,命令是gcc -S main.i -o main.s
❯ file a.s
a.s: assembler source, ASCII text
可以看出.s文件已经是汇编文件来,接下来看下其中的内容
1 .file "a.c"
2 .text
3 .section .rodata
4 .LC0:
5 .string "hello world!"
6 .text
7 .globl main
8 .type main, @function
9 main:
10 .LFB0:
11 .cfi_startproc
12 pushq %rbp
13 .cfi_def_cfa_offset 16
14 .cfi_offset 6, -16
15 movq %rsp, %rbp
16 .cfi_def_cfa_register 6
17 subq $16, %rsp
18 movl $2, -4(%rbp)
19 leaq .LC0(%rip), %rdi
20 call puts@PLT
21 movl $0, %eax
22 leave
23 .cfi_def_cfa 7, 8
24 ret
25 .cfi_endproc
26 .LFE0:
27 .size main, .-main
28 .ident "GCC: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0"
29 .section .note.GNU-stack,"",@progbits
编译器干的事情:
- 扫描:装入扫描机中,按照关键字、标识符、字面量、特殊符号分类,Linux下
lex工具 - 语法分析:语法分析器生成语法树,即以表达式为节点的树,Linux下
yacc工具 - 语义分析:语义分析器给语法树的节点表示类型
- 源代码优化:源代码分析器将语法树转换成中间代码,中间代码使得编译器分为编译器前端和编译器后端,前端产生机器无关的中间代码,后端负责将中间代码转换成目标机器代码.
- 代码生成:由编译器后端(代码生成器)生成机器相关代码
- 目标代码优化:由编译器后端(目标代码优化器)生成机器相关代码、
汇编
可以理解为翻译,将汇编文件转换为二进制文件,命令是gcc -c add.s -o add.o
❯ file a.o
a.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped
之后会加上Linux下ELF文件的讲解的…
通过objdump -h ./a.o更加简单的查看汇编文件中的内容
./a.o: file format elf64-x86-64
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000022 0000000000000000 0000000000000000 00000040 2**0
CONTENTS, ALLOC, LOAD, RELOC, READONLY, CODE
1 .data 00000000 0000000000000000 0000000000000000 00000062 2**0
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 0000000000000000 0000000000000000 00000062 2**0
ALLOC
3 .rodata 0000000d 0000000000000000 0000000000000000 00000062 2**0
CONTENTS, ALLOC, LOAD, READONLY, DATA
4 .comment 0000002a 0000000000000000 0000000000000000 0000006f 2**0
CONTENTS, READONLY
5 .note.GNU-stack 00000000 0000000000000000 0000000000000000 00000099 2**0
CONTENTS, READONLY
6 .eh_frame 00000038 0000000000000000 0000000000000000 000000a0 2**3
CONTENTS, ALLOC, LOAD, RELOC, READONLY, DATA
除了objdump以外在Linux下还可以使用readelf工具查看LF文件内容
链接
链接是将各个模块之间相互引用的部分处理好,使得各个模块能够正确的衔接,把一些指令对其他符号地址的引用加以修正.
将所有二进制形式的目标文件和系统组件组合成一个可执行文件。完成链接的过程也需要一个特殊的软件,叫做链接器(Linker),转换为可执行文件
链接器学习:
a linker or link editor is a computer utility program that takes one or more object files generated by a compiler and combines them into a single executable file, library file, or another ‘object’ file.
当a.c想要使用b.c中的函数func时,编译时在a.c中不知道func的地址,所以将其地址设置为0,等待链接器将a.c和b.c链接时对func的地址进行修正,这个过程也被称为重定位
ELF文件浅述
从结构上讲,目标文件是可执行文件,也就是二进制,只是没有经过链接的过程,里面的符号或者地址没有被调整
在Linux平台下,目标文件的格式是ELF(Executable Linkable Format)格式
目标文件、可执行文件、动态链接库、静态链接库都按照ELF格式存储
- 可重定位文件:这类文件包含了代码和数据,可以被用来链接成可执行文件或共享目标文件,静态链接库也可以归为这一类,
Linux下的.o文件 - 可执行文件, 这类文件包含了可以直接执行的程序,它的代表就是 ELF 可执行文件,它们一般都没有扩展名,
/bin/bash文件 - 共享目标文件,这种文件包含了代码和数据,可以在以下两种情况下使用.一种是链接器可以使用这种文件跟其他的可重定位文件和共享目标文件链接,产生新的目标文件。第二种是动态链接器可以将几个这种共享目标文件与可执行文件结合,作为进程映像的一部分来运行,
Linux下的.so文件 - 核心转储文件,当进程意外终止时,系统可以将该进程的地址空间的内容及终止时的一些其他信息转储到核心转储文件
Linux下的core dump














 3284
3284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









