







收录于话题
#大数据常用技术15
#大数据17
Hive是大数据生态必不可少的数据仓库服务,我们能使用很简单的sql命令执行分布式查询任务,后端可以对接MR、TEZ、SPARK分布式查询引擎。高性能是衡量分布式的指标,为了对hive能更高效的使用,我们有必要研究其线程模型是如何支持高并发的。我们以Beeline和HiveServer为入口分析下客户端和服务端执行流程。
一、HiveServer执行解析。
首先看下service接口及其继承类

其中Hive Server2->Composite Service->AbstractService->Service是我们分析的主线。CLiService用于对客户端收到的sql命令进行异步提交到后端集群(MR、SPARK、TEZ),Session Manager是用于客户端会话管理,并在初始化中创建一个backgroupthreadPool。ThriftBinaryCLIService用于创建线程接收并处理客户端连接。
看下HiveServer2的初始化定义。
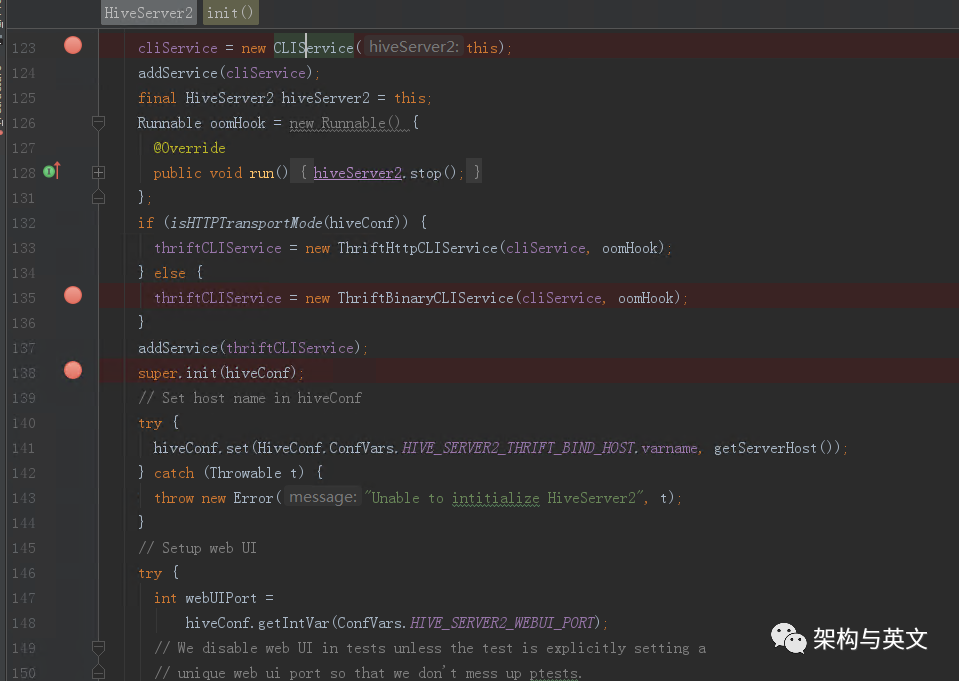
此函数内部定义了ThriftBinaryCLIService和CLiService。直接看下ThriftBinaryCLIService的run函数代码:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2652
2652











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









