







原创 马申跃 架构与英文 3天前
收录于话题
#Flink6
#大数据26
#大数据常用技术20
流数据如何在Flink 不同的TaskManager之间流动?这是任何一位想深入研究Flink内核的伙伴都绕不过去的逻辑,之前写过一篇文章《流数据如何在Flink新线程模型上流动》,主要通过Demo调式研究了Flink在local模式下的数据流动过程,其完全是在同一个TaskManager内,Inputchannel使用的都是LocalInputchannel,这次好奇下RemoteInputChannel和ResultPartition吧。消费者生产者模型应该都听说过,让我们一起分析BufferBuilder和BufferConsumer组合是如何完美的应用到Flink上,从而达到数据处理线程和发送线程的解耦。经过大量源码研究,笔者终于理清了实现逻辑,本文试图用一个最简单的图去描述它,如下图其流程逻辑清晰明了,建议读者结合源码去看加深印象。
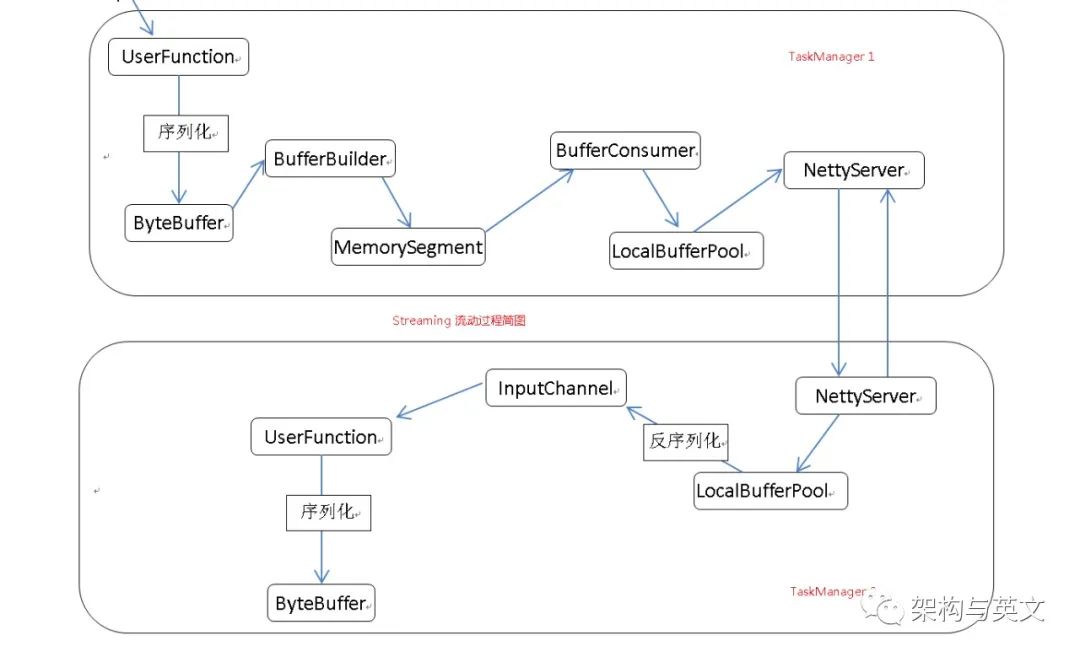
ResultPartition由ResultsubPartition组成,ResultsubPartition是streaming和batch的抽象接口,分别对应PipelinedSubpartition和BoundBlockingSubpartition(其产生的是文件)。
UserFunct
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 342
342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









