







CREATE TABLE `t` (
`id` int(11) NOT NULL,
`city` varchar(16) NOT NULL,
`name` varchar(16) NOT NULL,
`age` int(11) NOT NULL,
`addr` varchar(128) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `city` (`city`)
) ENGINE=InnoDB;
构建一个表结构,以及数据。 本篇主要来分析下order by是如何进行排序的。
EXPLAIN SELECT city,name,age FROM city_info WHERE city = '河北' order by name LIMIT 1000;
全字段排序

执行语句,发现使用了filesort,因为city有索引。所以整个city索引树就是如下,city 对应id主键。
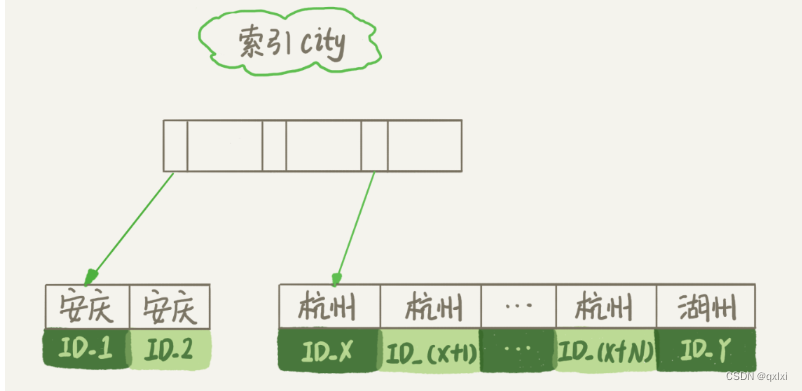
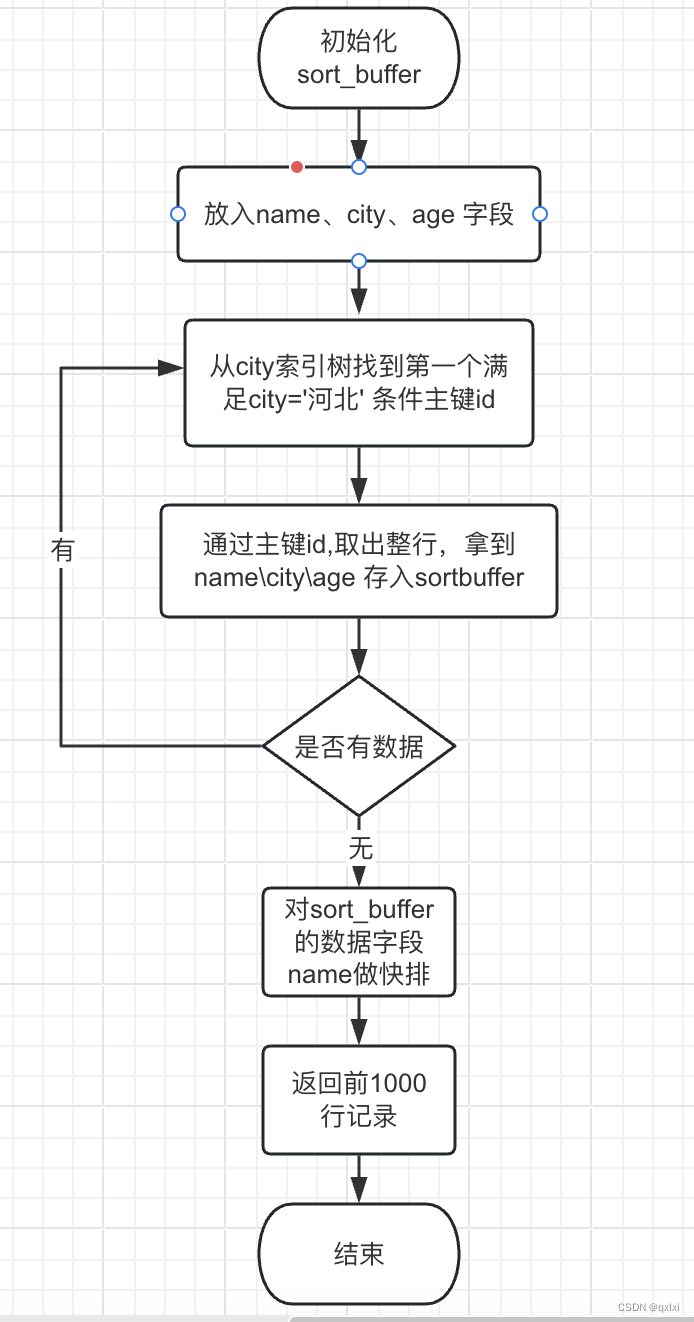
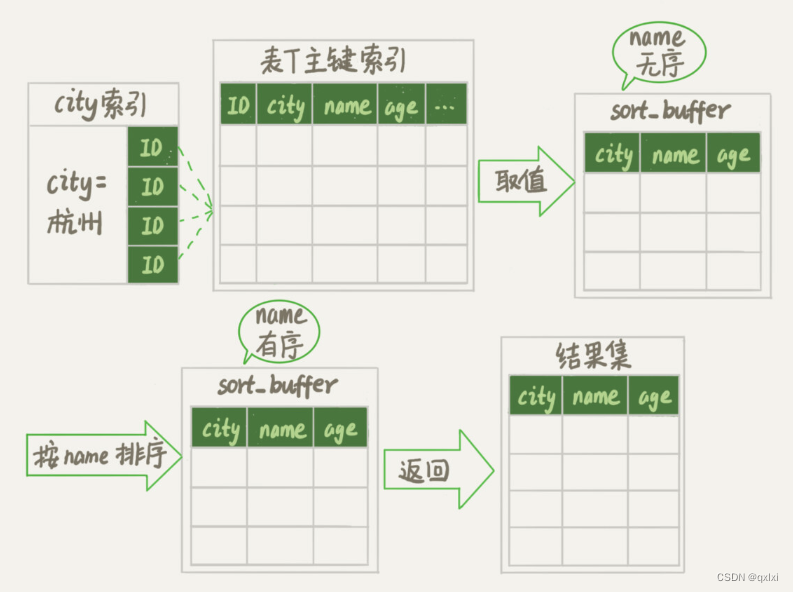
而图中按照sort_buffer 可能在内存或者外部排序使用,取决于排序所需的内存和参数sort_buffer_size 是MySQL为排序开辟的内存大小,如果排序的数据量小于 用内存,否则就用磁盘临时文件辅助排序。
rowid 排序
针对上面的执行流程,其实主要在临时文件进行排序,但是如何要排序的字段太多,那么sort_buffer中存储的数据就比较多。
SET max_length_for_sort_data = 16;
可以将排序的字段长度设置小一点,MySQL就采用另一个算法。
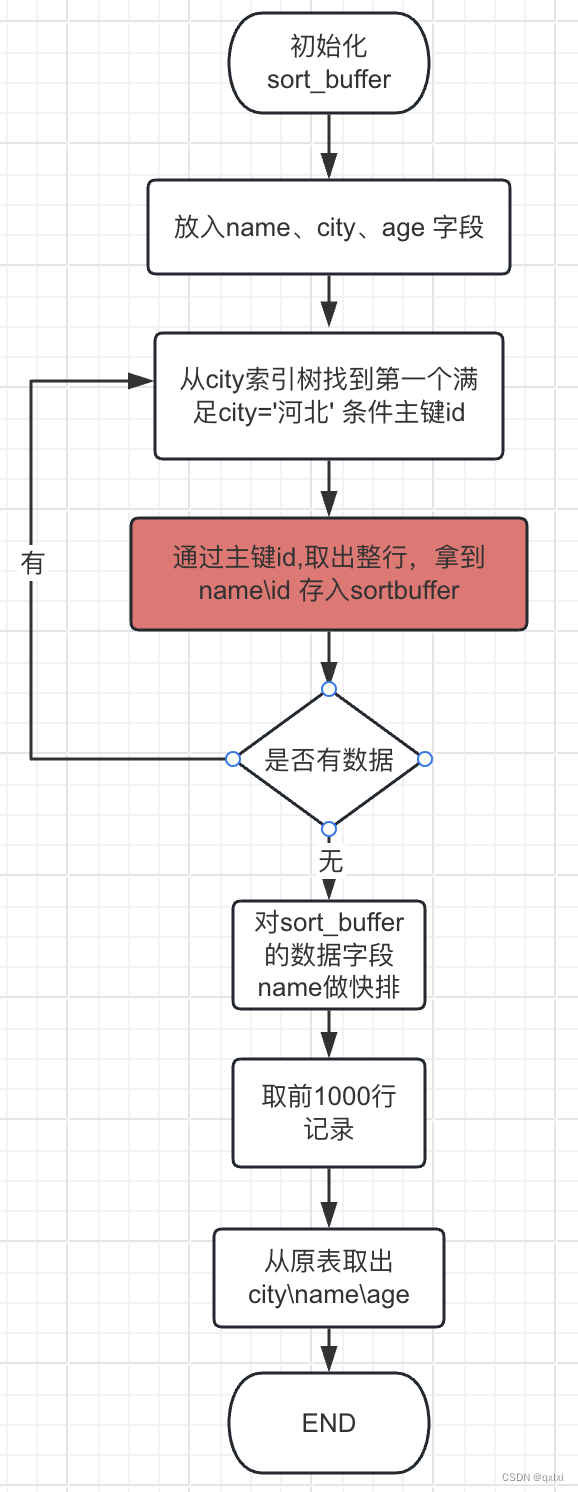
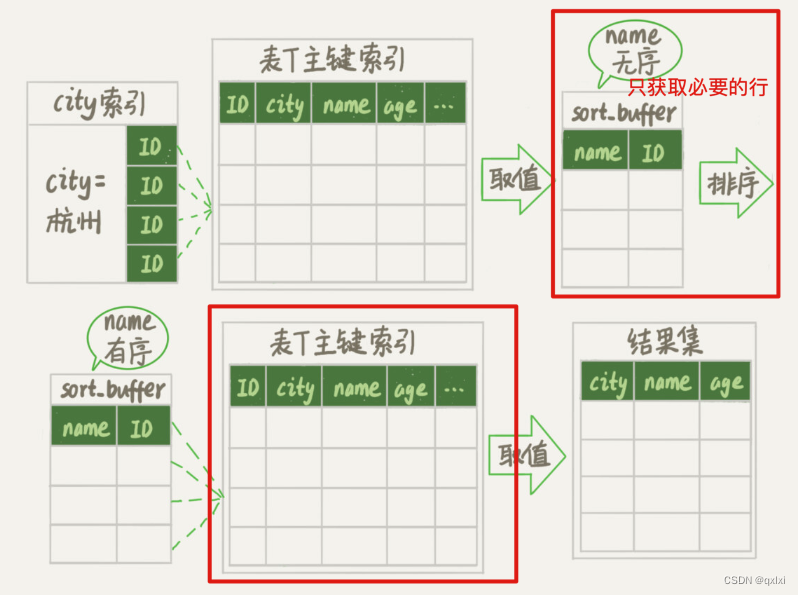
可以看到,如果字段太多的话,会先获取排序字段和id列,然后在最终返回结果的时候,进行处理。从主键id索引树获取对应的行。
全字段排序 VS rowid 排序
其实从这两种排序中可以看出,MySQL是能利用内存就多利用内存,减少外部磁盘的使用。另一个就是用不同的算法进行选择rowid排序或者全字段排序。
MySQL做排序成本还是比较高的,需要生成一个临时表,当然只是原数据是无序的。
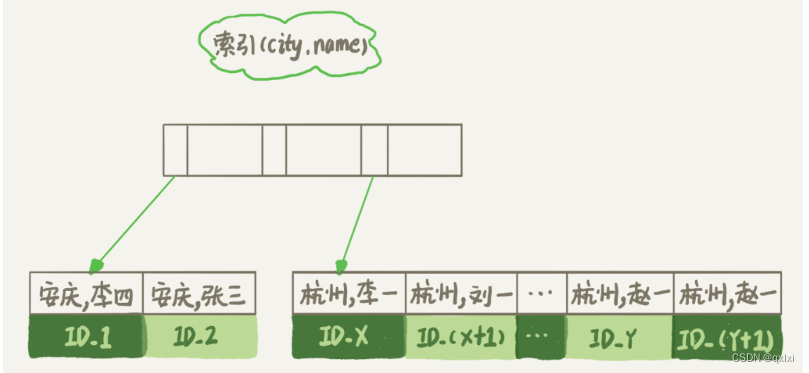
如果name是天然有序的,那么就不需要进行file sort的排序操作。
alter table t add index city_user(city, name);

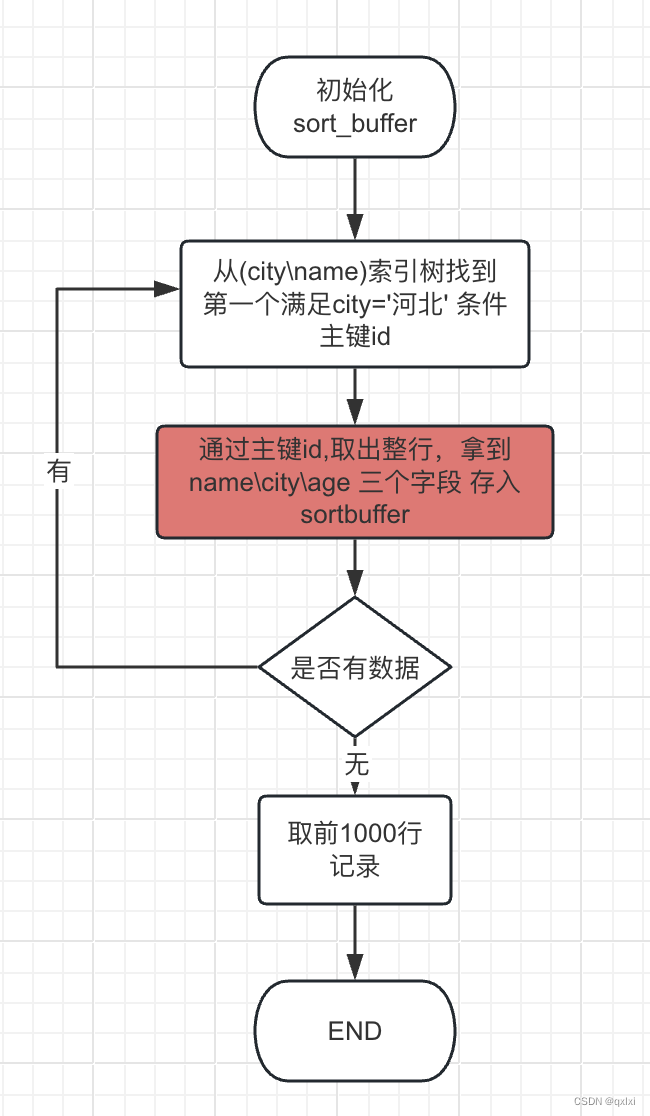
小结
本篇文章主要介绍order by 字段 在全字段和rowid排序的过程,针对不同的情况主要取决于要排序的字段长度,因此我们可以通过添加组合索引、覆盖索引进行优化file排序。


















 930
930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











