






1.关于anaconda和pytorch的下载以及各种配置
参考下面这篇文章,真的很详细,按着操作即可
http://t.csdnimg.cn/Rf2lY![]() http://t.csdnimg.cn/Rf2lY
http://t.csdnimg.cn/Rf2lY
2.自制数据集
这里原本用labelimg扣标签的,后面发现我把xml格式转txt格式的代码走不通,找不到解决方法,所以我用了make sense(贴个链接Make Sense![]() https://www.makesense.ai/),标签导出直接就是txt格式了。
https://www.makesense.ai/),标签导出直接就是txt格式了。
3.训练集和验证集的划分
按道理来说这里本来应该随机分的,但是想了想手动分应该没什么大问题,再加上代码问题,真就手工训练集和验证集的划分处理了,花了有五六个小时才把两个集搞好。
4.模型下载以及预训练权重下载
还是参考这篇文章下载,很全http://t.csdnimg.cn/tw6sp![]() http://t.csdnimg.cn/tw6sp
http://t.csdnimg.cn/tw6sp
嫌进网站慢可以换个外国的vpn
不过里面还是有点小问题,有些代码是老版本的需要改改,其中有一些pycharm会提醒你,下个网易有道翻译实时翻译就行,还有一些没提醒的在下面这篇文章里找http://t.csdnimg.cn/nImYb![]() http://t.csdnimg.cn/nImYb
http://t.csdnimg.cn/nImYb
这样一套流程下来基本问题就解决了
5.模型训练
最开始用的是5s的权重,准度低但是真的快,然后试了一把5x的权重,笔记本跑不动(哭),
最后折中选了5m的权重,跑了一个半小时,结果还算能打
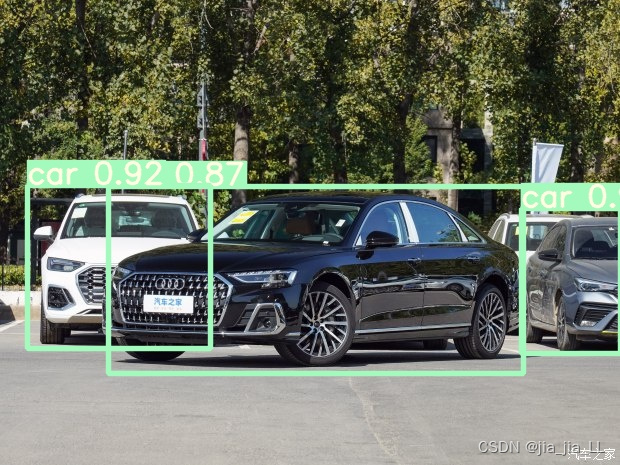
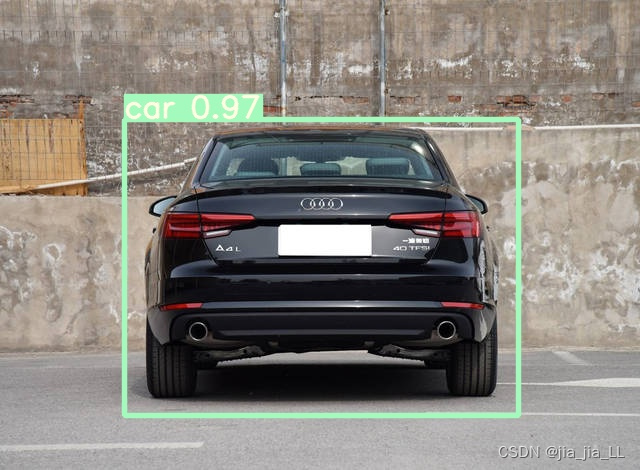
附上一些图片检测结果


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









