







Introduction
R is a programming language and a software suite used for data analysis, statistical computing and data visualization. It is highly extensible and has object oriented features and strong graphical capabilities. At its heart R is an interpreted language and comes with a command line interpreter – available for Linux, Windows and Mac machines – but there are IDEs as well to support development like RStudio or JGR.
R and Hadoop can complement each other very well, they are a natural match in big data analytics and visualization. One of the most well-known R packages to support Hadoop functionalities is RHadoop that was developed by RevolutionAnalytics.
Installing RHadoop
RHadoop is a collection of three R packages: rmr, rhdfs and rhbase. rmr package provides Hadoop MapReduce functionality in R, rhdfs provides HDFS file management in R and rhbase provides HBase database management from within R.
To install these R packages, first we need to install R base package. On Ubuntu 12.04 LTS we can do it running:
$ sudo apt-get install r-base
Then we need to install RHadoop packages with their dependencies. rmr requires RCpp, RJSONIO, digest, functional, stringr and plyr, while rhdfs requires rJava.
As part of the installation, we need to reconfigure Java for rJava package and we also need to set HADOOP_CMD variable for rhdfs package. The installation requires the corresponding tar.gz archives to be downloaded and then we can run R CMD INSTALL command with sudo privileges.
sudo R CMD INSTALL Rcpp Rcpp_0.10.2.tar.gz sudo R CMD INSTALL RJSONIO RJSONIO_1.0-1.tar.gz sudo R CMD INSTALL digest digest_0.6.2.tar.gz sudo R CMD INSTALL functional functional_0.1.tar.gz sudo R CMD INSTALL stringr stringr_0.6.2.tar.g sudo R CMD INSTALL plyr plyr_1.8.tar.gz sudo R CMD INSTALL rmr rmr2_2.0.2.tar.gz sudo JAVA_HOME=/home/istvan/jdk1.6.0_38/jre R CMD javareconf sudo R CMD INSTALL rJava rJava_0.9-3.tar.gz sudo HADOOP_CMD=/home/istvan/hadoop/bin/hadoop R CMD INSTALL rhdfs rhdfs_1.0.5.tar.gz sudo R CMD INSTALL rhdfs rhdfs_1.0.5.tar.gz
Getting started with RHadoop
In principle, RHadoop MapReduce is a similar operation to R lapply function that applies a function over a list or vector.
Without mapreduce function we could write a simple R code to double all the numbers from 1 to 100:
> ints = 1:100 > doubleInts = sapply(ints, function(x) 2*x) > head(doubleInts) [1] 2 4 6 8 10 12
With RHadoop rmr package we could use mapreduce function to implement the same calculations – see doubleInts.R script:
Sys.setenv(HADOOP_HOME="/home/istvan/hadoop")
Sys.setenv(HADOOP_CMD="/home/istvan/hadoop/bin/hadoop")
library(rmr2)
library(rhdfs)
ints = to.dfs(1:100)
calc = mapreduce(input = ints,
map = function(k, v) cbind(v, 2*v))
from.dfs(calc)
$val
v
[1,] 1 2
[2,] 2 4
[3,] 3 6
[4,] 4 8
[5,] 5 10
.....
If we want to run HDFS filesystem commands from R, we first need to initialize rhdfs using hdfs.init() function, then we can run the well-known ls, rm, mkdir, stat, etc commands:
> hdfs.init()
> hdfs.ls("/tmp")
permission owner group size modtime file
1 drwxr-xr-x istvan supergroup 0 2013-02-25 21:59 /tmp/RtmpC94L4R
2 drwxr-xr-x istvan supergroup 0 2013-02-25 21:49 /tmp/hadoop-istvan
> hdfs.stat("/tmp")
perms isDir block replication owner group size modtime path
1 rwxr-xr-x TRUE 0 0 istvan supergroup 0 45124-08-29 23:58:48 /tmp
Data analysis with RHadoop
The following example demonstrates how to use RHadoop for data analysis. Let us assume that we need to determine how many countries have greater GDP than Apple Inc.’s revenue in 2012. (It was 156,508 millions USD, see more details http://www.google.com/finance?q=NASDAQ%3AAAPL&fstype=ii&ei=5eErUcCpB8KOwAOkQQ)
GDP data can be downloaded from Worldbank data catalog site. The data needs to be adjusted to be suitable for MapReduce algorithm. The final format that we used for data analysis is as follows (where the last column is the GDP of the given country in millions USD):
Country Code,Number,Country Name,GDP, USA,1,United States,14991300 CHN,2,China,7318499 JPN,3,Japan,5867154 DEU,4,Germany,3600833 FRA,5,France,2773032 ....
The gdp.R script looks like this:
Sys.setenv(HADOOP_HOME="/home/istvan/hadoop")
Sys.setenv(HADOOP_CMD="/home/istvan/hadoop/bin/hadoop")
library(rmr2)
library(rhdfs)
setwd("/home/istvan/rhadoop/blogs/")
gdp <- read.csv("GDP_converted.csv")
head(gdp)
hdfs.init()
gdp.values <- to.dfs(gdp)
# AAPL revenue in 2012 in millions USD
aaplRevenue = 156508
gdp.map.fn <- function(k,v) {
key <- ifelse(v[4] < aaplRevenue, "less", "greater")
keyval(key, 1)
}
count.reduce.fn <- function(k,v) {
keyval(k, length(v))
}
count <- mapreduce(input=gdp.values,
map = gdp.map.fn,
reduce = count.reduce.fn)
from.dfs(count)
R will initiate a Hadoop streaming job to process the data using mapreduce algorithm.
packageJobJar: [/tmp/Rtmp4llUjl/rmr-local-env1e025ac0444f, /tmp/Rtmp4llUjl/rmr-global-env1e027a86f559, /tmp/Rtmp4llUjl/rmr-streaming-map1e0214a61fa5, /tmp/Rtmp4llUjl/rmr-streaming-reduce1e026da4f6c9, /tmp/hadoop-istvan/hadoop-unjar1158187086349476064/] [] /tmp/streamjob430878637581358129.jar tmpDir=null 13/02/25 22:28:12 INFO mapred.FileInputFormat: Total input paths to process : 1 13/02/25 22:28:12 INFO streaming.StreamJob: getLocalDirs(): [/tmp/hadoop-istvan/mapred/local] 13/02/25 22:28:12 INFO streaming.StreamJob: Running job: job_201302252148_0006 13/02/25 22:28:12 INFO streaming.StreamJob: To kill this job, run: 13/02/25 22:28:12 INFO streaming.StreamJob: /home/istvan/hadoop-1.0.4/libexec/../bin/hadoop job -Dmapred.job.tracker=localhost:9001 -kill job_201302252148_0006 13/02/25 22:28:12 INFO streaming.StreamJob: Tracking URL: http://localhost:50030/jobdetails.jsp?jobid=job_201302252148_0006 13/02/25 22:28:13 INFO streaming.StreamJob: map 0% reduce 0% 13/02/25 22:28:25 INFO streaming.StreamJob: map 100% reduce 0% 13/02/25 22:28:37 INFO streaming.StreamJob: map 100% reduce 100% 13/02/25 22:28:43 INFO streaming.StreamJob: Job complete: job_201302252148_0006 13/02/25 22:28:43 INFO streaming.StreamJob: Output: /tmp/Rtmp4llUjl/file1e025f146f8f
Then we will get the data saying how many countries have greater and how many contries have less GDP than Apple Inc.’s revenue in year 2012. The result is that 55 countries had greater GDP than Apple and 138 countries had less.
$key GDP 1 "greater" 56 "less" $val [1] 55 138
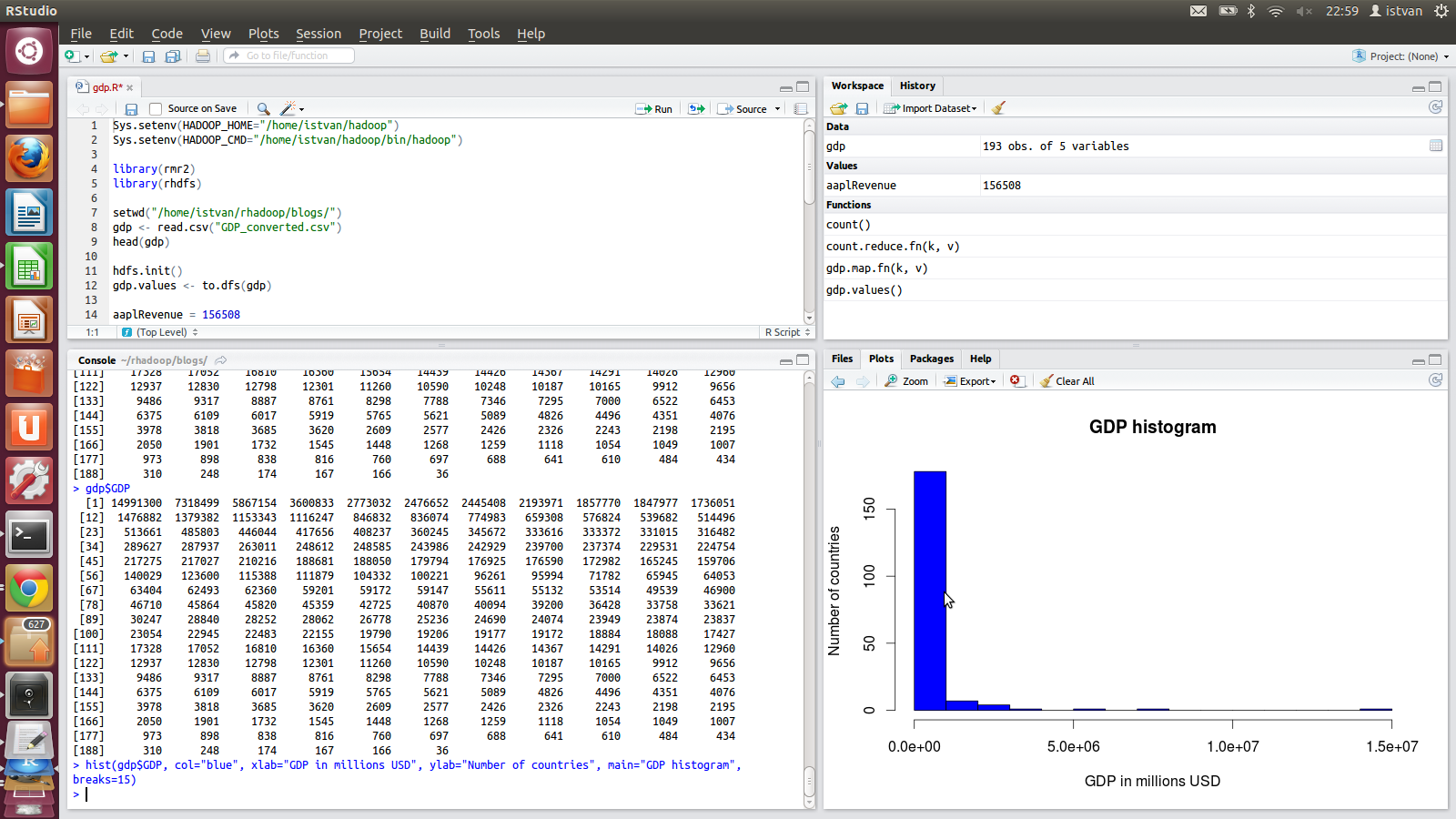
The following screenshot from RStudio shows the histogram of GDPs – there are 15 countries having more than 1,000 millions USD GDP; 1 country is in the range of 14,000 – 15,000 millions USD, 1 country is in the range of 7,000 – 8,000 millions USD and 1 country is in the range of 5,000 – 6,000 USD.
Conclusion
If someone needs to combine strong data analytics and visualization features with big data capabilities supported by Hadoop, it is certainly worth to have a closer look at RHadoop features. It has packages to integrate R with MapReduce, HDFS and HBase, the key components of the Hadoop ecosystem. For more details, please read the R and Hadoop Big Data Analytics whitepaper.

















 1226
1226


 到【灌水乐园】发言
到【灌水乐园】发言









Pingback: R and Hadoop Data Analysis – RHadoop « Another Word For It
Hello,
Does R works on MacOSx?
Yes, it does. You may want to have a look at this link: http://cran.r-project.org/bin/macosx/
Pingback: Installing R, RHadoop and RStudio over Cloudera Hadoop ecosystem | Linux Uncle
Pingback: First simple MapReduce example in RHadoop :-) | a hundred billion neurons
Pingback: Integrating R with Cloudera Impala for Real-Time Queries on Hadoop | BigHadoop
I cannot go over the step “sudo R CMD INSTALL rJava rJava_0.9-3.tar.gz”. It throws an error:
** testing if installed package can be loaded
Error : .onLoad failed in loadNamespace() for ‘rJava’, details:
call: dyn.load(file, DLLpath = DLLpath, …)
error: impossível carregar objeto compartilhado ‘/usr/local/lib/R/site-library/rJava/libs/rJava.so':
libjvm.so: Não é possivel abrir arquivo de objetos compartilhado: Arquivo ou diretório não encontrado
Erro: loading failed
Execução interrompida
ERROR: loading failed
* removing ‘/usr/local/lib/R/site-library/rJava’
Nevermind, I had to use this command before “R CMD javareconf -e”, and it worked =)