







http://blog.csdn.net/wangxin110000/article/details/22581279
LVQ网络(Learning Vector Quantization)是前面说的SOM的一个变种,但是学习方法仍然是Kohonen的竞争方法,说他是变种,因为这个算法是一种有监督的方法。
单看他的名字就知道,这是一种向量量化手段,如果给我K类数据,每类数据若干样本,我要找K个向量来代表这K类数据的模式,最简单的方法就是我对每类求均值,这是个很好的想法,但是如果我每个类中都有若干离群点,那可能会导致均值不能很好的代表那类数据的输入模式;怎么做呢?投票机制!LVQ,SOM都是这么做的;
LVQ分为LVQ1,LVQ2,LVQ3,下面简单说说LVQ2:
前面讲了SOM,LVQ与SOM的区别在输入,LVQ的输入是有标签的,同时其神经元也是有初始标签的,如下图:
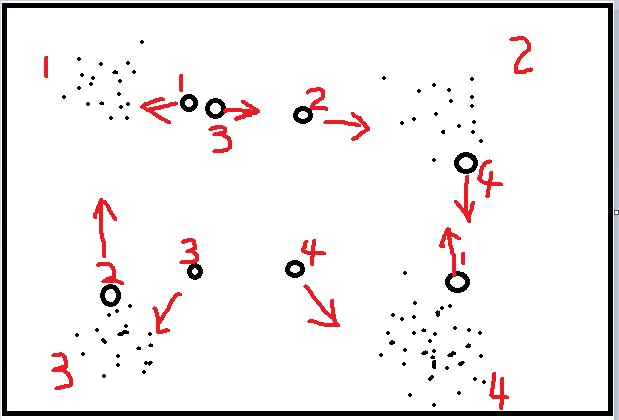
LVQ是由数据驱动的,数据搜索距离它最近的两个神经元,对于同类神经元采取拉拢,异类神经元采取排斥,这样相对于只拉拢不排斥能加快算法收敛的速度,最终得到数据的分布模式,开头提到,如果我得到已知标签的数据,我要求输入模式,我直接求均值就可以,用LVQ或者SOM的好处就是对于离群点并不敏感,少数的离群点并不影响最终结果,因为他们对最终的神经元分布影响很小。















 5887
5887











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









