







蛮力查找就是逐个比较数据,完全一样就是找到了,都找完了还没找到就是没有这样的数据。这是最容易实现的也最直观的查找算法。但是我估计很多人都会觉得我在逗你玩,因为这个太容易了,以至于容易到我都不用写出示例代码也没人写不出来(我想能看这篇文章的基本都会点:)。的确是这样的,但是我显然不能这样逗你玩的,因为我要讲的是你未必就真正明白的。
1. 数据规模和算法的常数时间
在设计任何实际应用算法的时候首先要考虑的就是数据规模,不谈数据规模的实际应用算法设计都是在耍流氓。因为保持代码清晰易读是所有程序员应该遵循的重要原则。代码不是有注释就易读了,而是需要具有显而易见的逻辑和统一可读的风格。统一可读的风格不用说,只要你还是团队战斗,你的领导就会要求你了。那么何为显而易见的逻辑呢?Unix的缔造者Ken Thompson说:“拿不准就穷举”,我认为这是最贴切的表达。因为只要穷举能搞定的问题,穷举是最显而易见的了。不要随便拿出O(n)这种度量算法好坏的标准来抨击穷举。因为好多所谓优良的算法在n很小的时候都很慢,在大多数情况下n都很小,也就是数据规模都很小。
大O标记法本质上只是一种理论估值,是对算法内常数时间上的一种规模度量,它屏蔽了算法的真实运行时间是常数时间 * O的这样的本质。也正因为如此,时间复杂度为O(nlogn)的快速排序要比其他具有相同复杂度的排序算法快,因为快速排序的常数时间一般情况下要比其他算法小。至于这个常数时间如何度量,其本身比较复杂,不在本文讨论范围内,有兴趣的读者可以参考相关专业文献。
2. 局部性原理
数据规模和常数时间问题搞清楚了,我们就可以回到蛮力查找这个算法上了。笔者要说的蛮力查找,就一定要在连续内存(更专业点说法叫顺序表)中查找!根因就是程序的局部性原理。
局部性原理并没有什么理论基础,它是人们通过观察程序特性所归纳总结出来的一个客观事实,即程序常常重复使用它们最近用过的数据和指令。一条广泛使用的经验规律是:一个程序90%的执行时间花费在仅10%的代码中。这比惯用的2:8原则还要倾斜。
局部性一般有两个维度,即:空间局部性和时间局部性。时间局部性是指:被引用过一次的的存储器位置在未来会被多次引用;空间局部性是指:如果一个存储器的位置被引用,那么将来他附近的位置也会被引用。为了说明这个问题,还是拿蛮力查找算法的代码说事儿:
int search( int *s, int n, int k)
{
int i;
for (i = 0; i < n; i++)
if (s[i] == k)
return i;
return -1;
}3. 高速缓存
CPU的高速缓存是局部性原理应用的典型案例。现代计算机系统都设置了多级高速缓存,下图描述了这个关系:
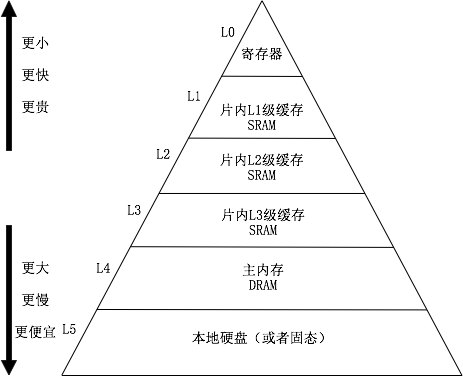
这图可能都不陌生,为了尊重版权,我给重画了:)。为啥这样设计呢?第一,钱闹的;第二,局部性原理说没必要浪费。如果所有存储器都做成寄存器那么快,伤的绝对不是心,那是白花花的银子,对于绝大多数人来说比伤心难过多了。
随着技术的不断发展,CPU自己是越来越快了,可内存的速度在不伤银子的情况下是很难提高的。而局部性原理又说程序90%的时间只运行了其10%的代码,为了让CPU的速度不至于被龟速的内存所累,那些设计CPU的科学家们就设计了高速缓存这个东西,在CPU与内存之间增加了小而快但昂贵的高速缓存来做一个折中。只要那些精贵的10%的代码在缓存中,CPU就不寂寞。之所以设计多层结构,是跟缓存命中率相关的。毕竟高速缓存都很小,不能保证100%的把那10%装进去,CPU一旦执行了不在高速缓存中的代码(专业讲叫未命中或缺失),那就要孤单寂寞好久了,这个代价一般会超过100个时钟周期。由于程序结构的特点(无外乎顺序、循环和选择分支三种),致使CPU指令的局部性非常好(缓存命中率高),但是对于数据的访问上来讲就并不那么乐观了。就Intel最先进的i7来讲(现在应该是i9了),其L1数据缓存未命中率(缺失率)能达到5%~10%,有时还会更高一些,所以L2和L3的缓存重要性就非常明显了,因为L2的平均未命中率可以控制在4%,而L3则是1%。这在一个程序有50%是存储指令的情况下,只相当于平均给每条指令增加了不到1个的时钟周期。
对于高速缓存的具体工作原理,本文暂不更进一步描述了,在笔者的这一系列文章里面,后续的内容会根据具体的数据结构和算法有针对性的介绍。对这部分内容感兴趣的读者们可以期待一下我的后续内容。
通过前面的论述可知,充分利用局部性原理是可以帮助我们极大的提高程序的执行速度的。而且我们只需关注数据的组织方式就行了,因为指令的组织方式编译器就帮我们做好了。如果数据能够装入寄存器中,那则是最快的,但是寄存器就那么几个,一般也就一些局部变量用用,所以不能有太多奢望;数据如果能够一次性装入L1缓存,也会得到无与伦比的极致速度,Intel的i7有32k这么多,对付一些情况也是够用的;至于其他两级缓存,因为命中率还不错,只要你的程序写的不是太过分,效率也不会低多少。可以说,搞清楚了局部性原理和高速缓存的基本工作方式,对编写出高效的代码是非常有益的。
4. 蛮力查找的适用性
好了,现在终于回到了正题,谈谈蛮力查找的适用性上了。虽然蛮力查找的时间复杂度是O(n)的,但是如果能充分利用局部性原理,让数据有效的落在L1中,会拥有非常漂亮的常数时间,这根跟你的数据规模有很大的相关性。当然,这些指标与具体的CPU有很大关系,不过基本可以有一个大概的估计。
拿i7的32k一级数据缓存来说吧。虽然全部都给你用不太现实,因为你的程序都是运行在操作系统之上,且还是多任务的。但是能分到1/10还是有合理性的,那么就是3K这么多。对于要查找的数据是32位整数类型(这个很常用),可以有750多个。如果用红黑树来查找则平均需要做10次比较。由于一般的红黑树实现都不是有很强的局部性(数据不连续),倒霉的时候这10次比较都发生了缓存不命中,那么大概总共要花费掉CPU的1000个时钟周期(其实这还没完,因为还要选择路径,也要多花费不少时钟周期)。可是这个时候的蛮力查找只要800个时钟周期即可完成(同时循环结构本身就是局部性良好的)。这便宜还真没少占啊。
当然,上述的分析都只是比较简略的分析,并不精准。但蛮力搜索的好处不只是在数据规模小的时候局部性好,更重要的是实现简单不会出错。所以在项目初期,为了保证“多、快、好、省”的交付产品,遇到这样的问题就直接上蛮力搜索吧。因为你无法预估实际的数据规模是多少,但多数不会超过3K那么多,即便超过了也不会太夸张。“过早优化是万恶之源”,每一个人都应该牢记(不限程序员)!















 958
958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









