







 文章详细解释了B树和B+树的数据结构,重点讨论了它们在MySQL索引中的应用,包括等值和范围查询的性能差异,以及MyISAM和InnoDB引擎中的索引实现。强调了B+树在减少磁盘IO次数上的优势,以及B+树与B树在存储和查询策略上的改进。
文章详细解释了B树和B+树的数据结构,重点讨论了它们在MySQL索引中的应用,包括等值和范围查询的性能差异,以及MyISAM和InnoDB引擎中的索引实现。强调了B+树在减少磁盘IO次数上的优势,以及B+树与B树在存储和查询策略上的改进。
- B树的节点中存储着多个元素,每个内节点有多个分叉。
- 节点中的元素包含键值和数据,节点中的键值从大到小排列。也就是说,在所有的节点都储存数据。
- 父节点当中的元素不会出现在子节点中。
- 所有的叶子结点都位于同一层,叶节点具有相同的深度,叶节点之间没有指针连接。

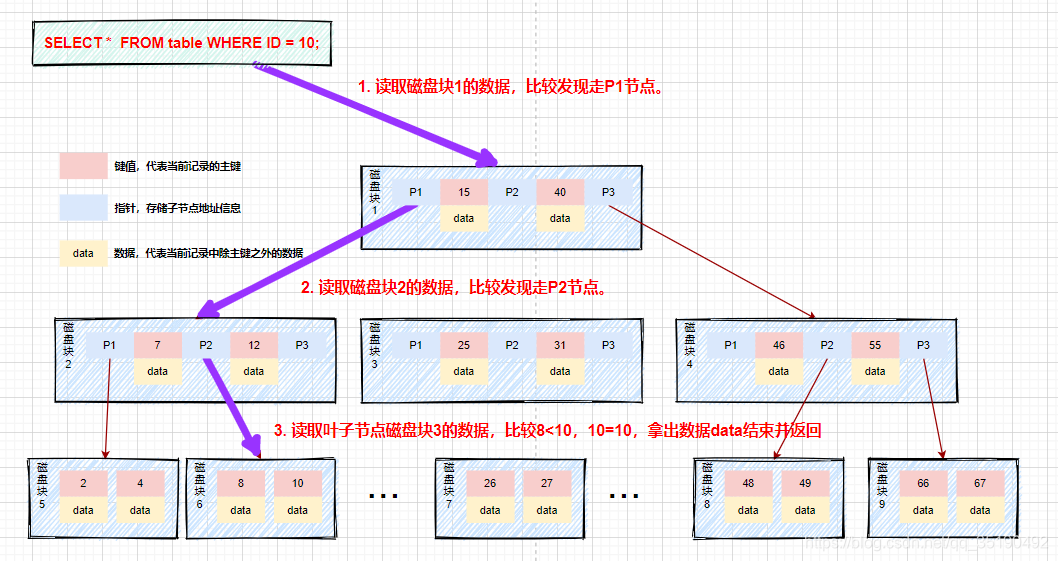
举个例子,在b树中查询数据的情况:
假如我们查询值等于10的数据。查询路径磁盘块1->磁盘块2->磁盘块5。
第一次磁盘IO:将磁盘块1加载到内存中,在内存中从头遍历比较,10<15,走左路,到磁盘寻址磁盘块2。
第二次磁盘IO:将磁盘块2加载到内存中,在内存中从头遍历比较,7<10,到磁盘中寻址定位到磁盘块5。
第三次磁盘IO:将磁盘块5加载到内存中,在内存中从头遍历比较,10=10,找到10,取出data,如果data存储的行记录,取出data,查询结束。如果存储的是磁盘地址,还需要根据磁盘地址到磁盘中取出数据,查询终止。
相比二叉平衡查找树,在整个查找过程中,虽然数据的比较次数并没有明显减少,但是磁盘IO次数会大大减少。同时,由于我们的比较是在内存中进行的,比较的耗时可以忽略不计。B树的高度一般2至3层就能满足大部分的应用场景,所以使用B树构建索引可以很好的提升查询的效率。
过程如图:
看到这里一定觉得B树就很理想了,但是前辈们会告诉你依然存在可以优化的地方:
- B树不支持范围查询的快速查找,你想想这么一个情况如果我们想要查找10和35之间的数据,查找到15之后,需要回到根节点重新遍历查找,需要从根节点进行多次遍历,查询效率有待提高。
- 如果data存储的是行记录,行的大小随着列数的增多,所占空间会变大。这时,一个页中可存储的数据量就会变少,树相应就会变高,磁盘IO次数就会变大。
B+树:改造B树
B+树,作为B树的升级版,在B树基础上,MySQL在B树的基础上继续改造,使用B+树构建索引。B+树和B树最主要的区别在于非叶子节点是否存储数据的问题
- B树:非叶子节点和叶子节点都会存储数据。
- B+树:只有叶子节点才会存储数据,非叶子节点至存储键值。叶子节点之间使用双向指针连接,最底层的叶子节点形成了一个双向有序链表。
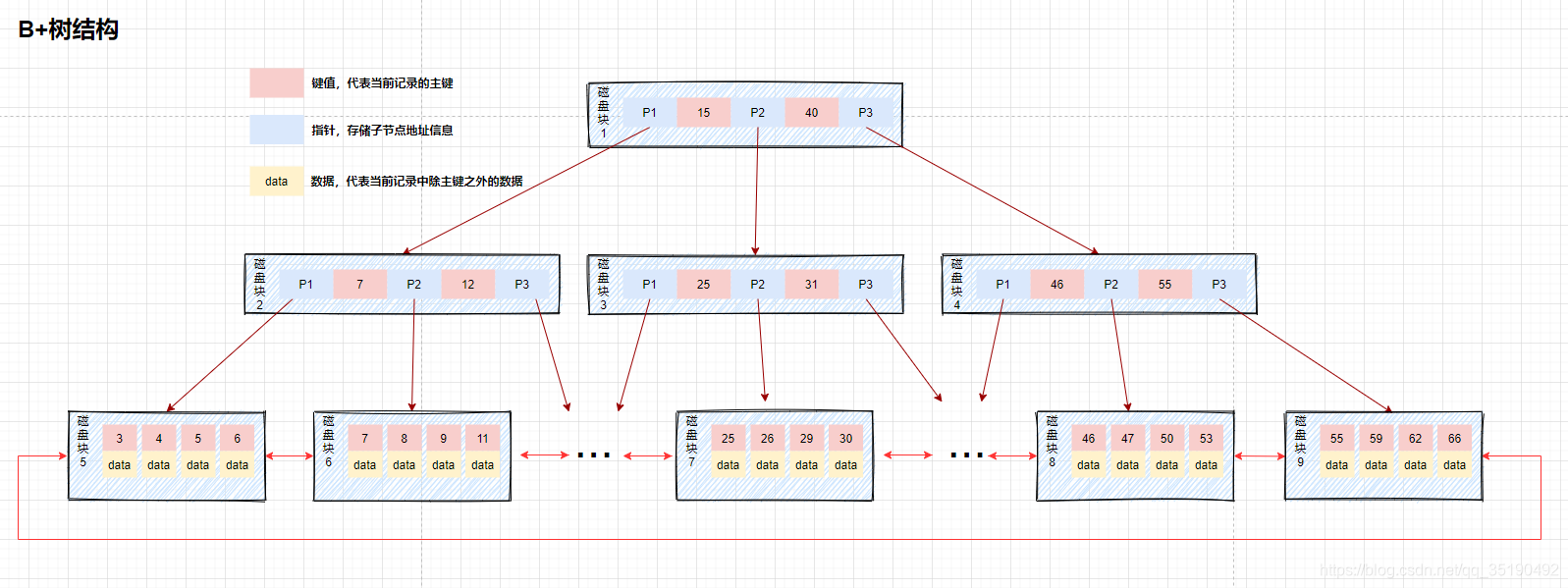
B+树的最底层叶子节点包含了所有的索引项。从图上可以看到,B+树在查找数据的时候,由于数据都存放在最底层的叶子节点上,所以每次查找都需要检索到叶子节点才能查询到数据。所以在需要查询数据的情况下每次的磁盘的IO跟树高有直接的关系,但是从另一方面来说,由于数据都被放到了叶子节点,所以放索引的磁盘块锁存放的索引数量是会跟这增加的,所以相对于B树来说,B+树的树高理论上情况下是比B树要矮的。也存在索引覆盖查询的情况,在索引中数据满足了当前查询语句所需要的全部数据,此时只需要找到索引即可立刻返回,不需要检索到最底层的叶子节点。
举个例子:
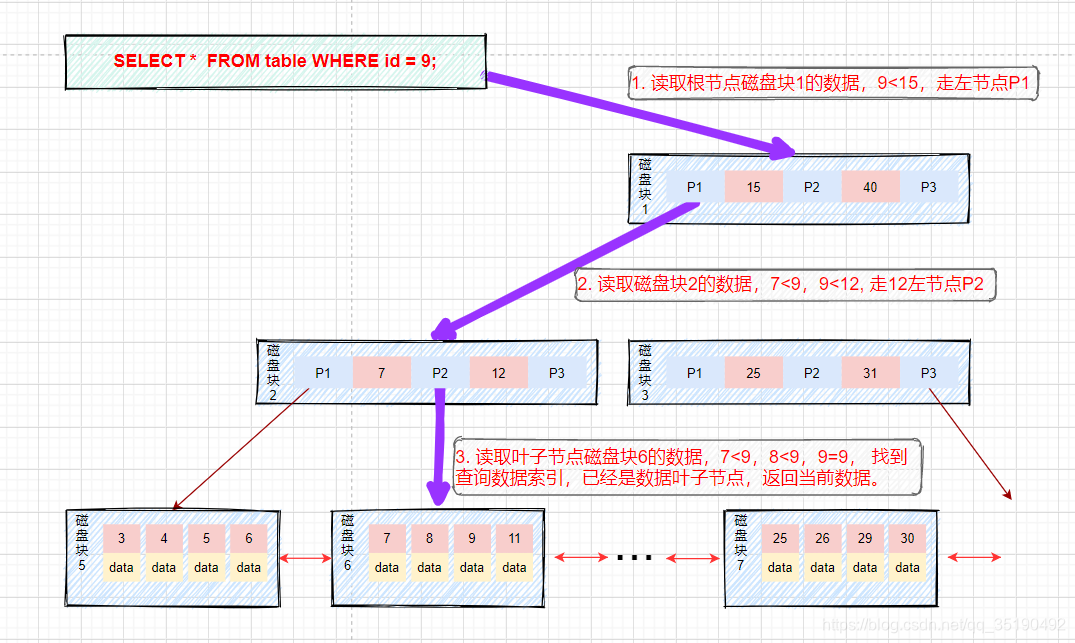
- 等值查询:
假如我们查询值等于9的数据。查询路径磁盘块1->磁盘块2->磁盘块6。
- 第一次磁盘IO:将磁盘块1加载到内存中,在内存中从头遍历比较,9<15,走左路,到磁盘寻址磁盘块2。
- 第二次磁盘IO:将磁盘块2加载到内存中,在内存中从头遍历比较,7<9<12,到磁盘中寻址定位到磁盘块6。
- 第三次磁盘IO:将磁盘块6加载到内存中,在内存中从头遍历比较,在第三个索引中找到9,取出data,如果data存储的行记录,取出data,查询结束。如果存储的是磁盘地址,还需要根据磁盘地址到磁盘中取出数据,查询终止。(这里需要区分的是在InnoDB中Data存储的为行数据,而MyIsam中存储的是磁盘地址。)
过程如图:
- 范围查询:
假如我们想要查找9和26之间的数据。查找路径是磁盘块1->磁盘块2->磁盘块6->磁盘块7。
- 首先查找值等于9的数据,将值等于9的数据缓存到结果集。这一步和前面等值查询流程一样,发生了三次磁盘IO。
- 查找到15之后,底层的叶子节点是一个有序列表,我们从磁盘块6,键值9开始向后遍历筛选所有符合筛选条件的数据。
- 第四次磁盘IO:根据磁盘6后继指针到磁盘中寻址定位到磁盘块7,将磁盘7加载到内存中,在内存中从头遍历比较,9<25<26,9<26<=26,将data缓存到结果集。
- 主键具备唯一性(后面不会有<=26的数据),不需再向后查找,查询终止。将结果集返回给用户。
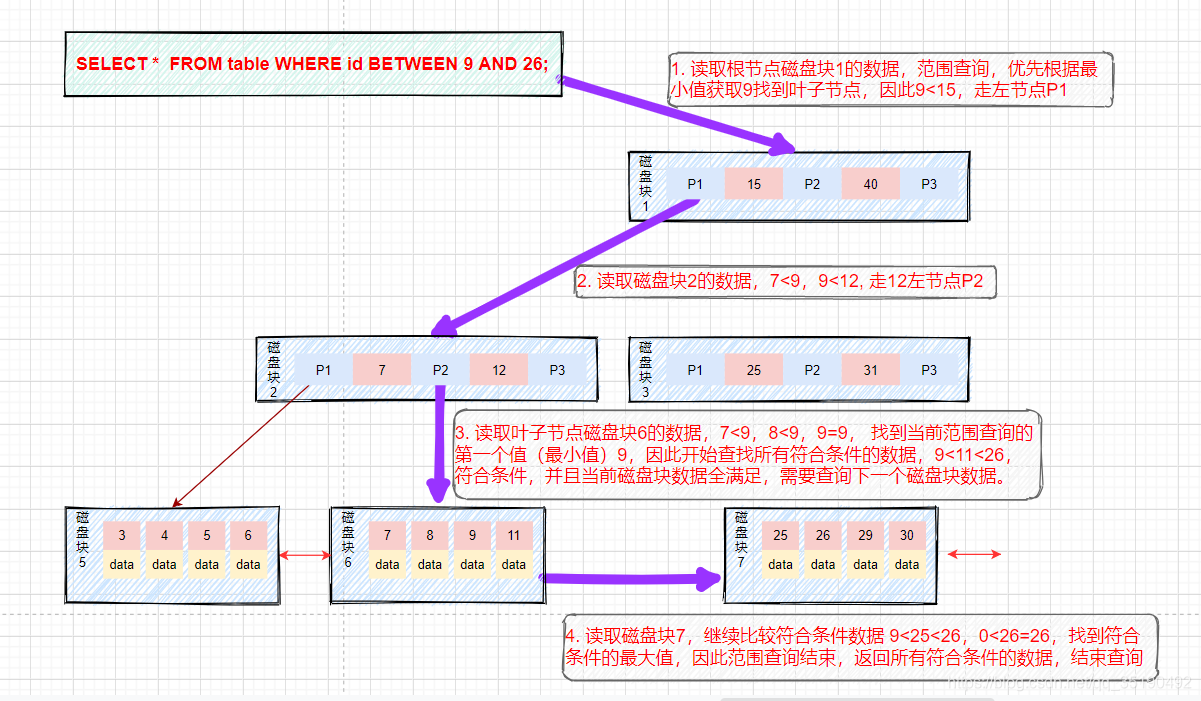
可以看到B+树可以保证等值和范围查询的快速查找,MySQL的索引就采用了B+树的数据结构。
Mysql的索引实现
介绍完了索引数据结构,那肯定是要带入到Mysql里面看看真实的使用场景的,所以这里分析Mysql的两种存储引擎的索引实现:MyISAM索引和InnoDB索引
MyIsam索引
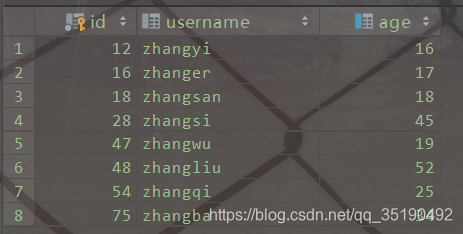
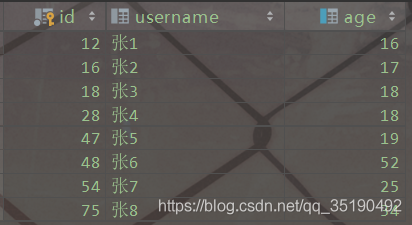
以一个简单的user表为例。user表存在两个索引,id列为主键索引,age列为普通索引
CREATE TABLE `user`
(
`id` int(11) NOT NULL AUTO\_INCREMENT,
`username` varchar(20) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_age` (`age`) USING BTREE
) ENGINE = MyISAM
AUTO\_INCREMENT = 1
DEFAULT CHARSET = utf8;
MyISAM的数据文件和索引文件是分开存储的。MyISAM使用B+树构建索引树时,叶子节点中存储的键值为索引列的值,数据为索引所在行的磁盘地址。
主键索引
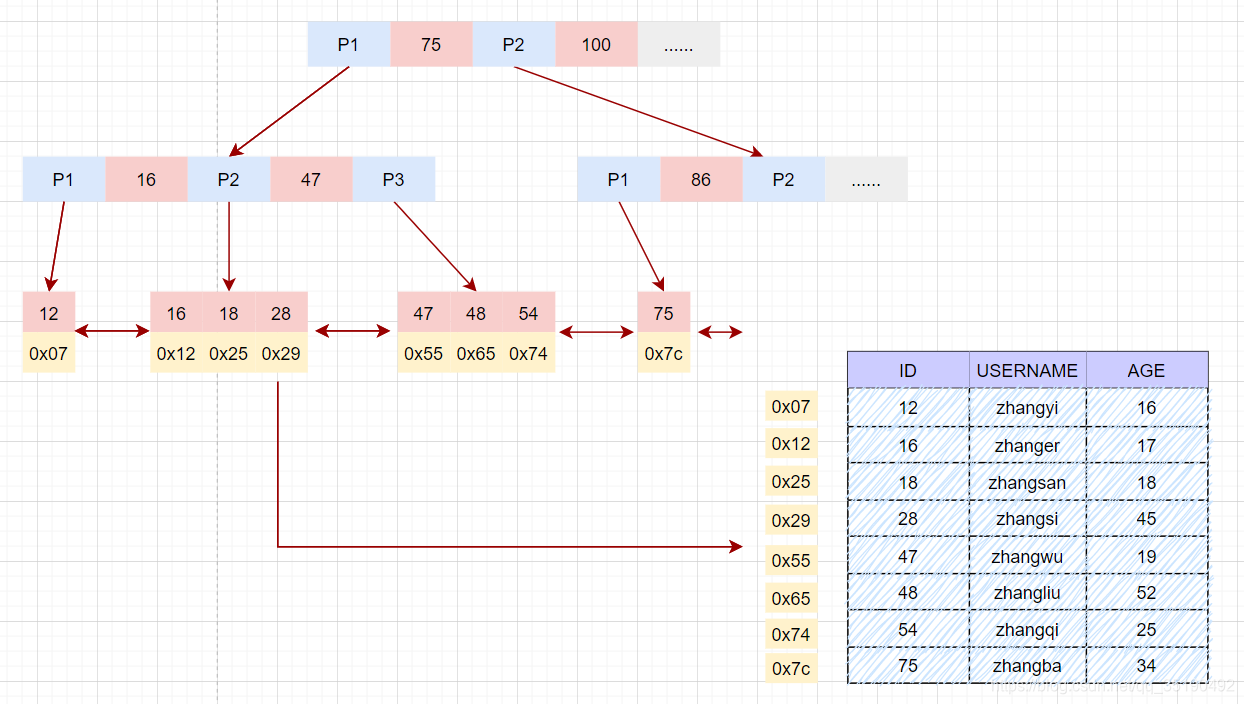
表user的索引存储在索引文件user.MYI中,数据文件存储在数据文件 user.MYD中。
简单分析下查询时的磁盘IO情况:
根据主键等值查询数据:
select * from user where id = 28;
- 先在主键树中从根节点开始检索,将根节点加载到内存,比较28<75,走左路。(1次磁盘IO)
- 将左子树节点加载到内存中,比较16<28<47,向下检索。(1次磁盘IO)
- 检索到叶节点,将节点加载到内存中遍历,比较16<28,18<28,28=28。查找到值等于30的索引项。(1次磁盘IO)
- 从索引项中获取磁盘地址,然后到数据文件user.MYD中获取对应整行记录。(1次磁盘IO)
- 将记录返给客户端。
磁盘IO次数:3次索引检索+记录数据检索。

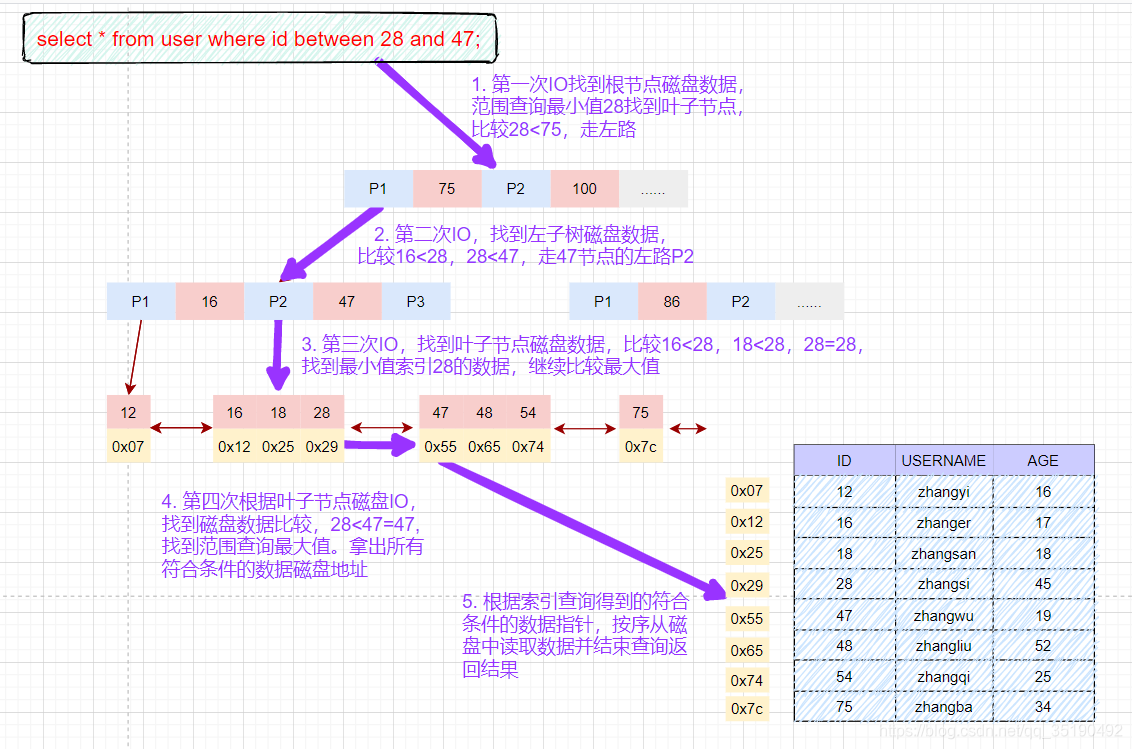
根据主键范围查询数据:
select \* from user where id between 28 and 47;
- 先在主键树中从根节点开始检索,将根节点加载到内存,比较28<75,走左路。(1次磁盘IO)
- 将左子树节点加载到内存中,比较16<28<47,向下检索。(1次磁盘IO)
- 检索到叶节点,将节点加载到内存中遍历比较16<28,18<28,28=28<47。查找到值等于28的索引项。
根据磁盘地址从数据文件中获取行记录缓存到结果集中。(1次磁盘IO)
我们的查询语句时范围查找,需要向后遍历底层叶子链表,直至到达最后一个不满足筛选条件。
4. 向后遍历底层叶子链表,将下一个节点加载到内存中,遍历比较,28<47=47,根据磁盘地址从数据文件中获取行记录缓存到结果集中。(1次磁盘IO)
5. 最后得到两条符合筛选条件,将查询结果集返给客户端。
磁盘IO次数:4次索引检索+记录数据检索。
**备注:**以上分析仅供参考,MyISAM在查询时,会将索引节点缓存在MySQL缓存中,而数据缓存依赖于操作系统自身的缓存,所以并不是每次都是走的磁盘,这里只是为了分析索引的使用过程。
辅助索引
在 MyISAM 中,辅助索引和主键索引的结构是一样的,没有任何区别,叶子节点的数据存储的都是行记录的磁盘地址。只是主键索引的键值是唯一的,而辅助索引的键值可以重复。
查询数据时,由于辅助索引的键值不唯一,可能存在多个拥有相同的记录,所以即使是等值查询,也需要按照范围查询的方式在辅助索引树中检索数据。
InnoDB索引
主键索引(聚簇索引)
每个InnoDB表都有一个聚簇索引 ,聚簇索引使用B+树构建,叶子节点存储的数据是整行记录。一般情况下,聚簇索引等同于主键索引,当一个表没有创建主键索引时,InnoDB会自动创建一个ROWID字段来构建聚簇索引。InnoDB创建索引的具体规则如下:
- 在表上定义主键PRIMARY KEY,InnoDB将主键索引用作聚簇索引。
- 如果表没有定义主键,InnoDB会选择第一个不为NULL的唯一索引列用作聚簇索引。
- 如果以上两个都没有,InnoDB 会使用一个6 字节长整型的隐式字段 ROWID字段构建聚簇索引。该ROWID字段会在插入新行时自动递增。
除聚簇索引之外的所有索引都称为辅助索引。在中InnoDB,辅助索引中的叶子节点存储的数据是该行的主键值都。 在检索时,InnoDB使用此主键值在聚簇索引中搜索行记录。
这里以user_innodb为例,user_innodb的id列为主键,age列为普通索引。
CREATE TABLE `user_innodb`
(
`id` int(11) NOT NULL AUTO\_INCREMENT,
`username` varchar(20) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_age` (`age`) USING BTREE
) ENGINE = InnoDB;
InnoDB的数据和索引存储在一个文件t_user_innodb.ibd中。InnoDB的数据组织方式,是聚簇索引。
主键索引的叶子节点会存储数据行,辅助索引只会存储主键值。
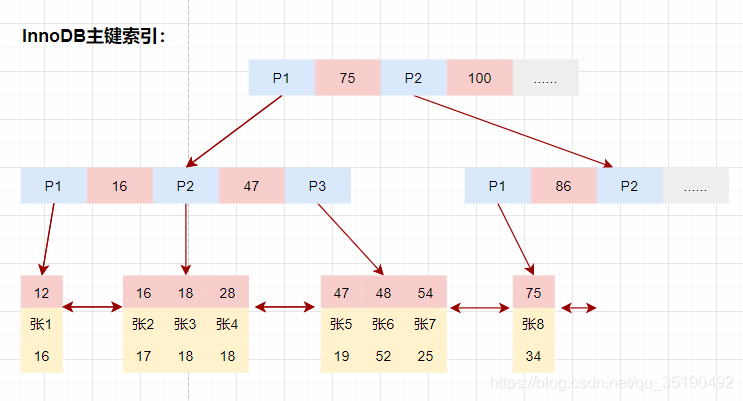
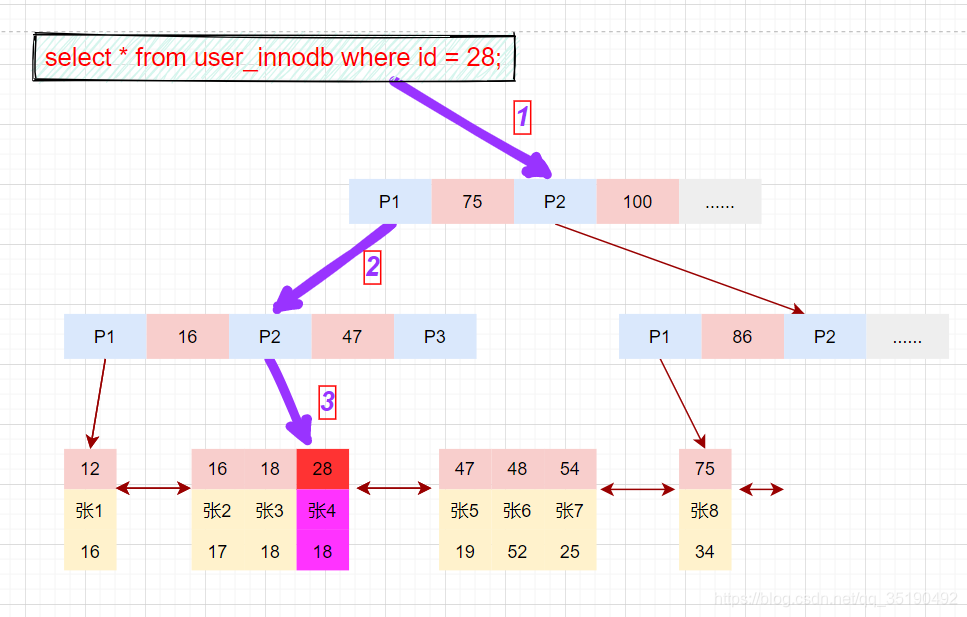
等值查询数据:
select \* from user_innodb where id = 28;
- 先在主键树中从根节点开始检索,将根节点加载到内存,比较28<75,走左路。(1次磁盘IO)
- 将左子树节点加载到内存中,比较16<28<47,向下检索。(1次磁盘IO)
- 检索到叶节点,将节点加载到内存中遍历,比较16<28,18<28,28=28。查找到值等于28的索引项,直接可以获取整行数据。将改记录返回给客户端。(1次磁盘IO)
磁盘IO数量:3次。
辅助索引
除聚簇索引之外的所有索引都称为辅助索引,InnoDB的辅助索引只会存储主键值而非磁盘地址。
以表user_innodb的age列为例,age索引的索引结果如下图。
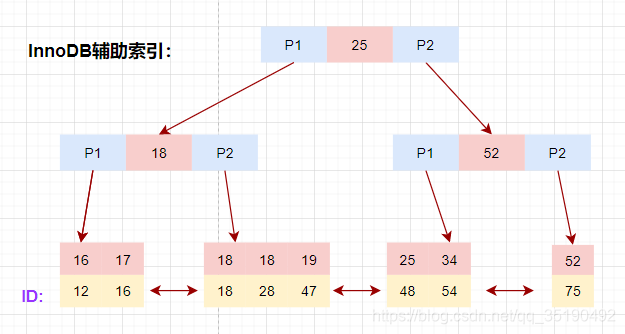
底层叶子节点的按照(age,id)的顺序排序,先按照age列从小到大排序,age列相同时按照id列从小到大排序。
使用辅助索引需要检索两遍索引:首先检索辅助索引获得主键,然后使用主键到主索引中检索获得记录。
画图分析等值查询的情况:
select \* from t_user_innodb where age=19;
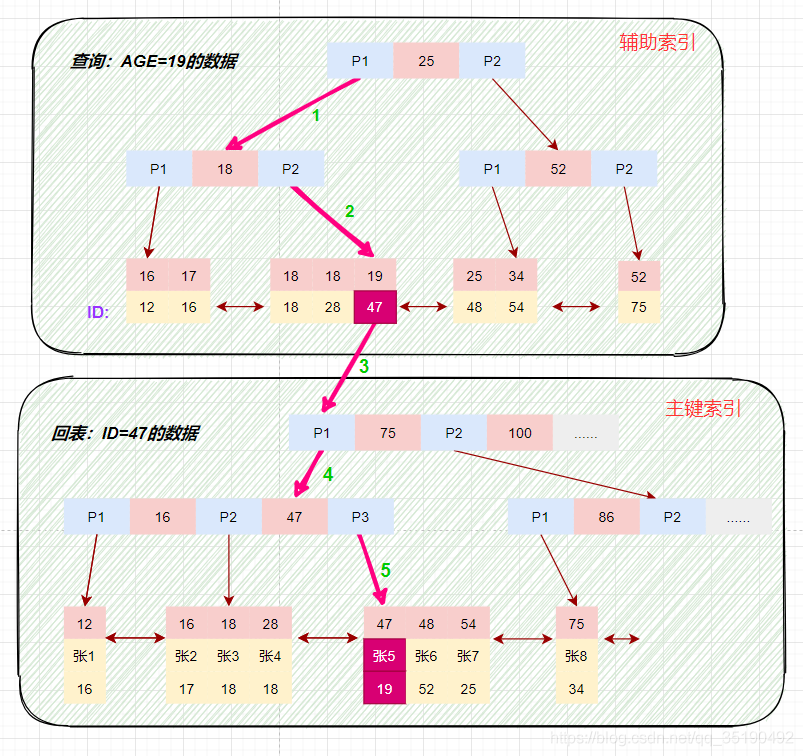
根据在辅助索引树中获取的主键id,到主键索引树检索数据的过程称为回表查询。
磁盘IO数:辅助索引3次+获取记录回表3次
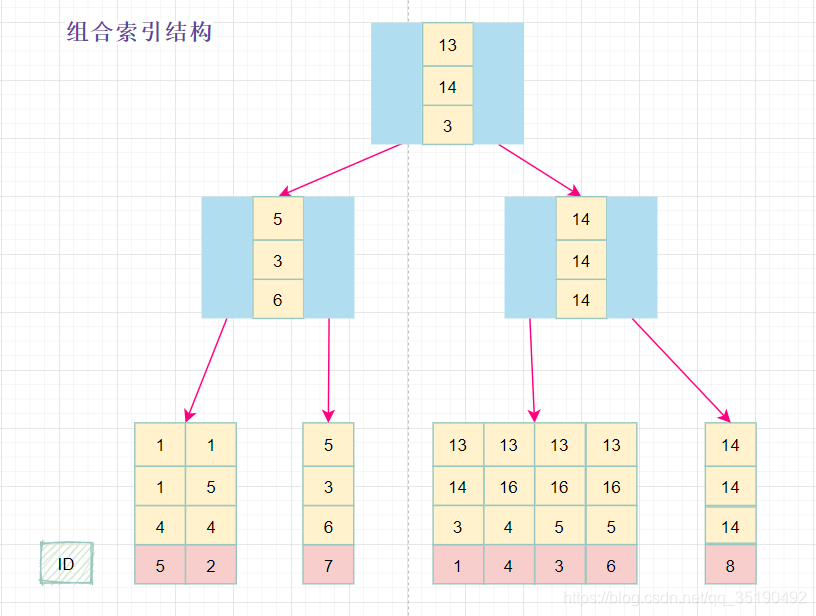
组合索引
还是以自己创建的一个表为例:表 abc_innodb,id为主键索引,创建了一个联合索引idx_abc(a,b,c)。
CREATE TABLE `abc_innodb`
(
`id` int(11) NOT NULL AUTO\_INCREMENT,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
`c` varchar(10) DEFAULT NULL,
`d` varchar(10) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_abc` (`a`, `b`, `c`)
) ENGINE = InnoDB;
select * from abc_innodb order by a, b, c, id;

组合索引的数据结构:
总结
我们总是喜欢瞻仰大厂的大神们,但实际上大神也不过凡人,与菜鸟程序员相比,也就多花了几分心思,如果你再不努力,差距也只会越来越大。
面试题多多少少对于你接下来所要做的事肯定有点帮助,但我更希望你能透过面试题去总结自己的不足,以提高自己核心技术竞争力。每一次面试经历都是对你技术的扫盲,面试后的复盘总结效果是极好的!

ng?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1MTkwNDky,size_16,color_FFFFFF,t_70#pic_center)
总结
我们总是喜欢瞻仰大厂的大神们,但实际上大神也不过凡人,与菜鸟程序员相比,也就多花了几分心思,如果你再不努力,差距也只会越来越大。
面试题多多少少对于你接下来所要做的事肯定有点帮助,但我更希望你能透过面试题去总结自己的不足,以提高自己核心技术竞争力。每一次面试经历都是对你技术的扫盲,面试后的复盘总结效果是极好的!
[外链图片转存中…(img-8euUVunF-1714543888087)]















 15万+
15万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









