







总流程:
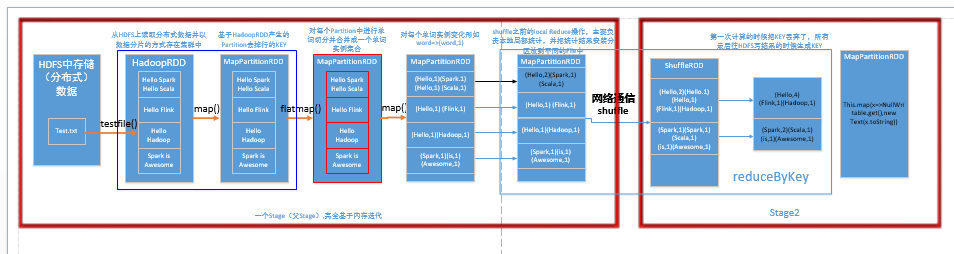
前部分:
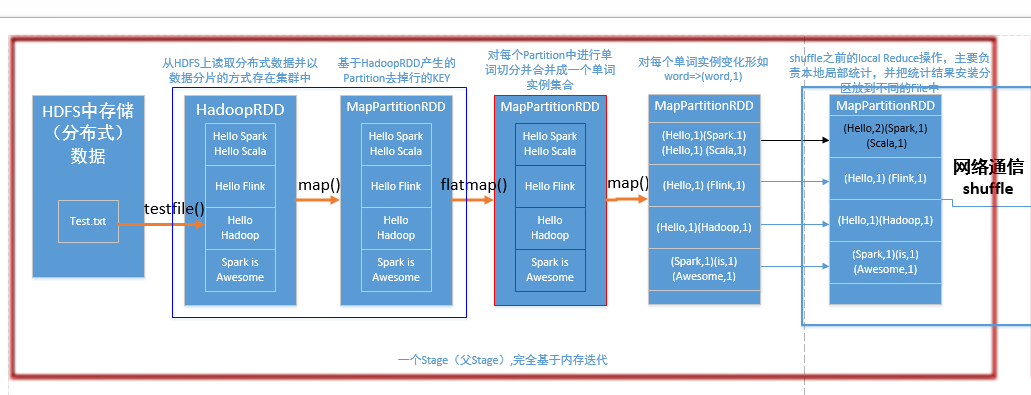
后部分:
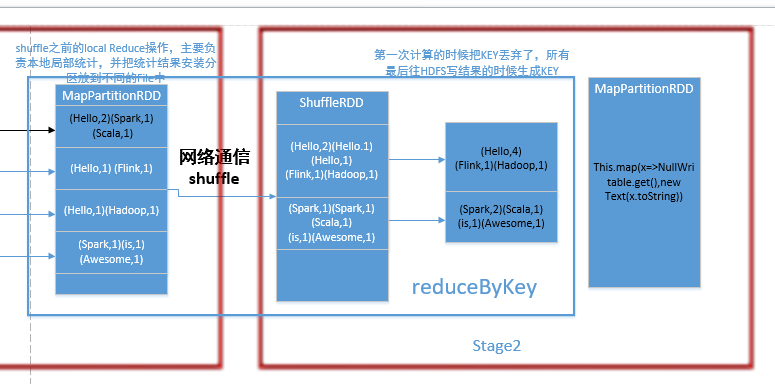
第一阶段执行的代码如下:
val lines = sc.textFile("E:/test/test.txt",4) //读取本地文件,并设置为4个Partition
val words=lines.flatMap(line => line.split(" "))
//对每一行的字符串进行单词拆分,并把所有行的拆分结果通过flat合并成为一个大的单词集合
val pairs = words.map(word => (word,1)) //在单词拆分的基础上对每个单词实例计数为1 总共出现的RDD有:HadoopRDD、MapPartitionRDD、MapPartitionRDD、MapPartitionRDD、MapPartitionRDD
第二阶段执行的代码如下:
val wordCounts = pairs.reduceByKey(_+_)
//对相同的key,进行Value的累计(包括local和Reducer同时Reduce)总共出现的RDD有:ShuffleRDD、MapPartitionRDD、
学习于:
DT大数据梦工厂
新浪微博:www.weibo.com/ilovepains/
微信公众号:DT_Spark
博客:http://.blog.sina.com.cn/ilovepains
TEL:18610086859
Email:18610086859@vip.126.com















 1298
1298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









