






求最长回文子串的方法有很多种,但是Manacher算法的时间复杂度为O(n)。通常求回文子串,要区分其长度是偶数或奇数,而Manacher算法提出了一种统一的处理方法:
对奇数长度的字符串“abc”,在每个空位添加字符‘#’,形成长度为奇数的新串“#a#b#c#”
对偶数数长度的字符串“abba”,在每个空位添加字符‘#’,形成长度为奇数的新串“#a#b#c#”
下面以字符串12212321为例,经过上一步,变成了 S[] = "$#1#2#2#1#2#3#2#1#";
然后用一个数组 P[i] 来记录以字符S[i]为中心的最长回文子串向右扩张的长度(包括S[i]),比如S和P的对应关系:
S # 1 # 2 # 2 # 1 # 2 # 3 # 2 # 1 #
P 1 2 1 2 5 2 1 4 1 2 1 6 1 2 1 2 1
(p.s. 可以看出,P[i]-1正好是原字符串中回文串的总长度)
下面计算P[i],该算法增加两个辅助变量id和mx,mx表示在i之前,回文子串可以延伸到最右端的位置,而id就是该回文子串的中心点。如下图,当前若访问的是i=9蓝色字符2的位置,之前的最长回文子串以i=7为中心可以延伸到最右端的位置为i=10,这里的mx就是10,而id为7。
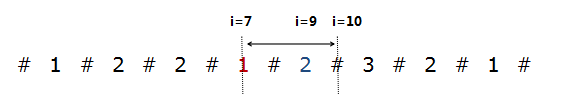
这个算法之所以为O(n)是因为它可以减少重复的访问,在算法中体现如下:
if( mx > i) p[i]=min(p[2*id-i], mx-i);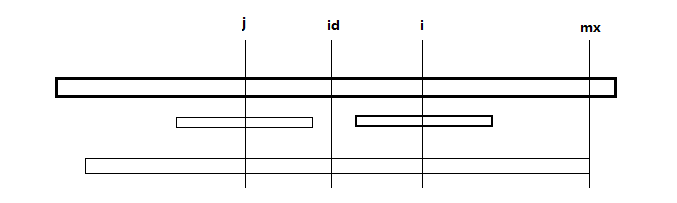
在看下为什么是mx-i,如下图,虽然i<mx,但是中间的小块还有一部分没有包含在i之前的最长回文子串中,但其可以保证p[i]可以向右扩展mx-i个长度,而剩下的部分则需要一步一步去判断(见代码中的while循环)。
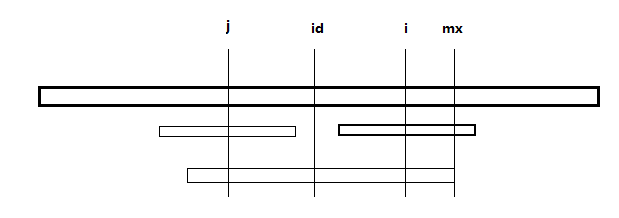
若if( mx < i) p[i]=1,说明当前的i无法通过前面的回文子串进行覆盖,只能一步一步地判断了,通过上面的分析,可以给出下面的代码:
#include <cstring>
#include <cstdio>
#include <algorithm>
using namespace std;
const int M=110005;
char str1[M],str[2*M];
int p[2*M];
int main(){
int i,j;
while(scanf("%s",str1)!=EOF){
int c=2,mx=0,id,ans=0;
str[0]='$'; str[1]='#';//设置str[0]='$'可防止越界
for(i=0;str1[i];i++){
str[c++]=str1[i];
str[c++]='#';
}
for(i=1;i<c;i++){
p[i]= i<mx ? min(p[2*id-i],mx-i) : 1;
while(str[i-p[i]]==str[i+p[i]]) p[i]++;
if(p[i]+i>mx){ //更新mx和id的值
mx=p[i]+i;
id=i;
}
ans=max(p[i]-1,ans); //保存最长的回文子串
}
printf("%d\n",ans);
}
}题目来源: http://acm.hdu.edu.cn/showproblem.php?pid=3068














 654
654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









