






背景
公司集群上不能进行简单的debug,但是提交一次任务进行print输出的话,又太浪费时间(每次提交要经历各种build dataset、model,load dataset等操作,等真正到网络里已经过10分钟了,这样效率太低)。
调用pdb的操作
在代码里加入
pdb.set_trace()
注意加入的py文件开头要先import pdb
比如深度学习领域里,某个model的py文件的某行代码加入了pdb.set_trace()
下图是节选片段,大概意思就是我要在dataset进行build之前打了个断点 然后我想check一下这个cfg.data.train是不是我想要的内容
with open(dataset_cfg) as f:
cfg.data.train = yaml.load(f, Loader=yaml.FullLoader)
pdb.set_trace()
# return a list
datasets = [build_dataset(cfg.data.train)]注意这种方式下不要再输出重定向到某个txt文件里了!否则你就会望着终端界面发呆一下午。。
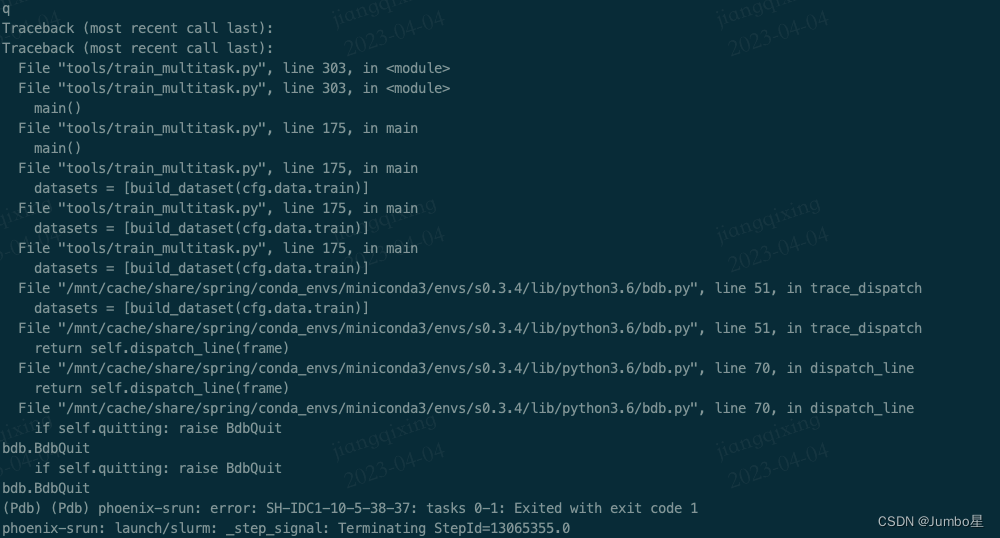
如果顺利的话,就能看到终端显示下面内容
第一行表示我在这个文件的这一行之前被中断了(实际上我的pdb.set_trace()在172行,175行是datasets = [build_dataset(cfg.data.train)],他到不了这行 所以展示给我看 告诉我要如果要执行,执行的下一行是这一行)
然后我的光标是可以动的 也就是说,我可以输入命令来操纵了!
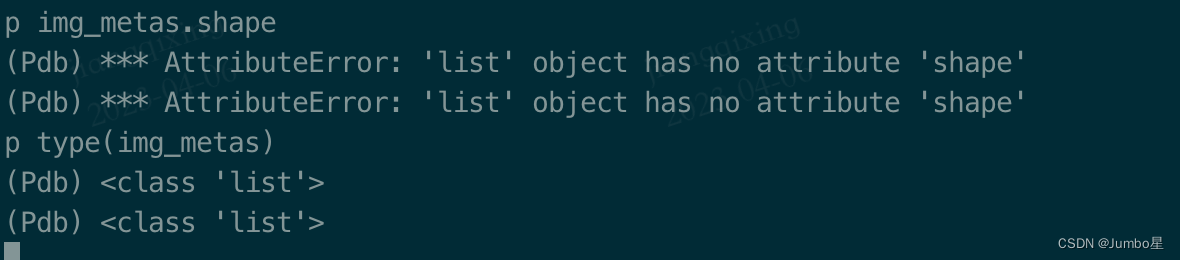
我想打印一下cfg.data.train看看,于是我输入了
p cfg.data.train
然后就看到终端有输出内容
 这样就实现了打断点进行随心所欲的print变量,相当于我这个程序在这边被我断了,我可以随心所欲在这个阶段想看什么变量就print看看,不需要一次次重新提交代码一次次在代码里添加个print
这样就实现了打断点进行随心所欲的print变量,相当于我这个程序在这边被我断了,我可以随心所欲在这个阶段想看什么变量就print看看,不需要一次次重新提交代码一次次在代码里添加个print
此外,这个p代表print,所以可以结合来看各种变量的各种属性,而不是只能打印变量值,比如看变量的shape和type
总结常用的pdb命令:
通过 n命令 执行下一行代码
输入 b 可以动态的添加断点
输入 q 退出:
b:设置断点,例如’b 12’表示在第12行下端点,'b a.py:12’表示在a.py这个文件的第12行下断点
cl:清除所有的断点
j:跳到指定的行数
















 2780
2780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









