







1.2 池化层(Pooling)
1.ReLU非线性特征
一句话概括:不用simgoid和tanh作为激活函数,而用ReLU作为激活函数的原因是:加速收敛。
因为sigmoid和tanh都是饱和(saturating)的。何为饱和?个人理解是把这两者的函数曲线和导数曲线plot出来就知道了:他们的导数都是倒过来的碗状,也就是,越接近目标,对应的导数越小。而ReLu的导数对于大于0的部分恒为1。于是ReLU确实可以在BP的时候能够将梯度很好地传到较前面的网络。
ReLU(线性纠正函数)取代sigmoid函数去激活神经元
1. 卷积神经网络结构
卷积神经网络是一个多层的神经网络,每层都是一个变换(映射),常用卷积convention变换和pooling池化变换,每种变换都是对输入数据的一种处理,是输入特征的另一种特征表达;每层由多个二维平面组成,每个平面为各层处理后的特征图(feature map)。
常见结构:
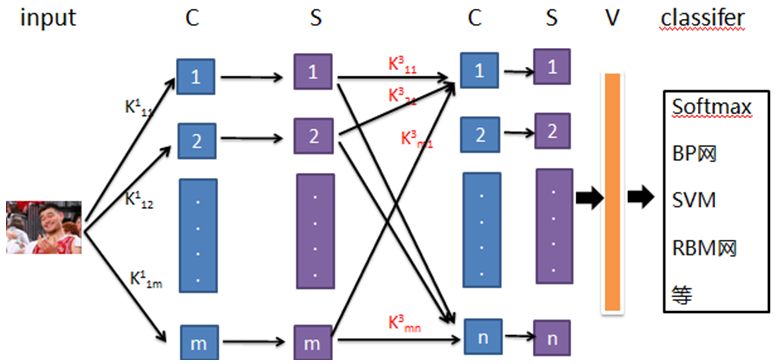
输入层为训练数据,即原始数据,网络中的每一个特征提取层(C-层)都紧跟着一个二次提取的计算层(S-层),这种特有的两次特征提取结构使网络在识别时对输入样本有较高的畸变容忍能力。具体C层和S层的个数不确定,依据具体案例而定;最后一个S,即完成了对原始数据的特征提取后,把S层的特征数据进行向量化(vector),然后连接到相应分类器。
一个具有7(输入层+c1+s2+c3+s4+c5+v)层网络结构的字母识别的CNN网络
高帧率扑克牌识别技术详解(可用于车牌识别,字符识别,人脸检测,验证码识别等等成熟领域)
本文主要介绍目前主流的adaboost目标检测算法,和CNN卷积神经网络字符识别算法。以扑克牌识别技术为题介绍相关的开发流程和经验。
整个系统包括,
1、摄像头采集,这里以USB摄像头通过directShow采集为例进行介绍。一个线程做采集,一个线程做检测识别。
2、字符检测正负样本得取。后面会详细介绍怎么在只有视频的情况下,
(1)自己写个鼠标拉框手工割取样本的软件,采用OpenCV的鼠标相应控件很容易实现。
(2)或者通过灰度化,自适应二值化,ROI找轮廓,轮廓筛选,ROI轮廓分割,自动割取样本;
(3)以及通过pictureRelate进行重复高样本自动剔除等等筛选。
准备样本:
正样本:
3、adaboost字符检测:
(1)用adaboost+haar特征训练第2步中得取的样本。
(2)进一步将测试分割出的误识别样本,进行筛选,重复2,3两步。直到获得满意的检测率。
4、识别样本得取
(1)字符识别样本读取,分为0-10,JQK,共14个类别。
(2)花色样本得取,共桃杏梅方四个类。
5、采用CNN组进行样本训练识别。这里为了提高识别率,采用两个CNN分别识别4.1和4.2,采用两个CNN并行思路提升识别速度。
(1)针对4.1的14各类,训练一个CNN分类器;
(2)针对4.2的4各类训练一个CNN分类器。
在介绍系统之前先对本文涉及的两大算法做简要的介绍:
1、adaboost算法实例介绍,这里不上理论,直接来实例对照着学boosting的思路。


2、CNN算法详细介绍。

1. 输入图像是32x32的大小,局部滑动窗的大小是5x5的,由于不考虑对图像的边界进行拓展,则滑动窗将有28x28个不同的位置,也就是C1层的大小是28x28。这里设定有6个不同的C1层,每一个C1层内的权值是相同的。
2. S2层是一个下采样层。简单的说,由4个点下采样为1个点,也就是4个数的加权平均。但在LeNet-5系统,下采样层比较复杂,因为这4个加权系数也需要学习得到,这显然增加了模型的复杂度。在斯坦福关于深度学习的教程中,这个过程叫做Pool。
3. 根据对前面C1层同样的理解,我们很容易得到C3层的大小为10x10. 只不过,C3层的变成了16个10x10网络! 试想一下,如果S2层只有1个平面,那么由S2层得到C3就和由输入层得到C1层是完全一样的。但是,S2层由多层,那么,我们只需要按照一定的顺利组合这些层就可以了。具体的组合规则,在 LeNet-5 系统中给出了下面的表格:

简单的说,例如对于C3层第0张特征图,其每一个节点与S2层的第0张特征图,第1张特征图,第2张特征图,总共3个5x5个节点相连接。后面依次类推,C3层每一张特征映射图的权值是相同的。
4. S4 层是在C3层基础上下采样,前面已述。在后面的层由于每一层节点个数比较少,都是全连接层
一、准备样本:
正样本:

负样本:















 78
78

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









