







最近工作要收集点酒店数据,就到携程上看了看,记录爬取过程去下
1.根据城市名称来分类酒店数据,所以先找了所有城市的名称
在这个网页上有http://hotels.ctrip.com/domestic-city-hotel.html

从网站地图上可以很容易发现这个页面
2.然后查看源码
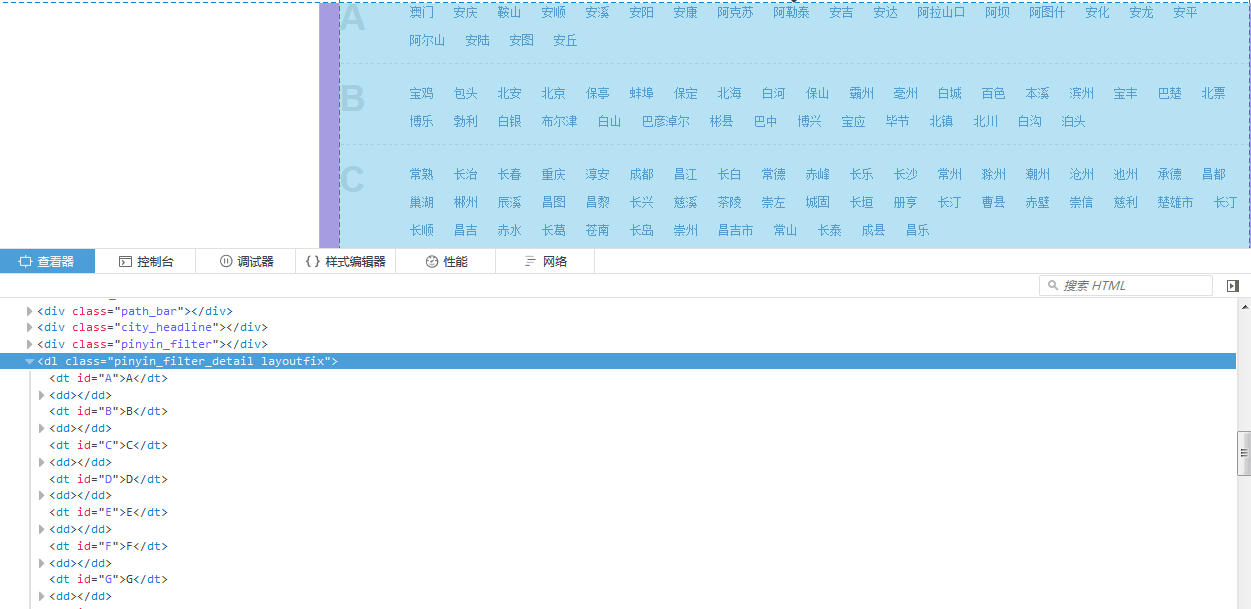
发现所有需要的数据都在
<dl class = "pinyin_filter_detail layoutfix"></dl>3.我们获取一下dl 这个元素和其中的所有子元素
我们用jsoup的jar包来解析获取的html,官网https://jsoup.org/,有API和jar包
String result = HttpUtil.getInstance().httpGet(null, "http://hotels.ctrip.com/domestic-city-hotel.html");
Document root_document = Jsoup.parse(result);
Elements pinyin_filter_elements = root_document.getElementsByClass("pinyin_filter_detail layoutfix");
//包含所有城市的Element
Element pinyin_filter = pinyin_filter_elements.first();4.我准备把获取的城市数据存储到mysql中,所以下面连接了本地mysql数据库
// 连接数据库
Connection conn = SqlDBUtils.getConnection();
StringBuilder create_table_sql = new StringBuilder();
create_table_sql.append("create table if not exists ctrip_hotel_city (id integer primary key auto_increment, city_id integer not null, city_name varchar(255) not null, head_pinyin varchar(80) not null, pinyin varchar(255) not null)");
PreparedStatement preparedStatement;
try {
//每次执行删除一下表,防止数据插入重复
preparedStatement = conn.prepareStatement("DROP TABLE IF EXISTS ctrip_hotel_city");
preparedStatement.execute();
// 创建ctrip_hotel_city表,存储城市数据
preparedStatement = conn.prepareStatement(create_table_sql.toString());
preparedStatement.execute();
} catch (SQLException e) {
e.printStackTrace();
}5.获取dl下所有的dt和dd,并从中提取数据库表中所需要的字段,实现存储
//拼音首字符Elements
Elements pinyins = pinyin_filter.getElementsByTag("dt");
//所有dd的Elements
Elements hotelsLinks = pinyin_filter.getElementsByTag("dd");6.数据提取
for (int i = 0; i < pinyins.size(); i++) {
Element head_pinyin = pinyins.get(i);
Element head_hotelsLink = hotelsLinks.get(i);
Elements links = head_hotelsLink.children();
for (Element link : links) {
String cityId = StringUtil.getNumbers(link.attr("href"));
String cityName = link.html();
String head_pinyin_str = head_pinyin.html();
String pinyin_cityId = link.attr("href").replace("/hotel/", "");
String pinyin = pinyin_cityId.replace(StringUtil.getNumbers(link.attr("href")), "");
StringBuffer insert_sql = new StringBuffer();
insert_sql.append("insert into ctrip_hotel_city (city_id, city_name, head_pinyin, pinyin) values (");
insert_sql.append(cityId);
insert_sql.append(", '" + cityName + "'");
insert_sql.append(", '" + head_pinyin_str + "'");
//此处注意汉语拼音中会有',直接插入数据库会报错,要把一个'替换为两个''
insert_sql.append(", '" + pinyin.replace("'", "''") + "')");
try {
preparedStatement = conn.prepareStatement(insert_sql.toString());
preparedStatement.execute();
} catch (SQLException e) {
e.printStackTrace();
}
}
}7.运行后查看mysql数据库ctrip_hotel_city表,如下
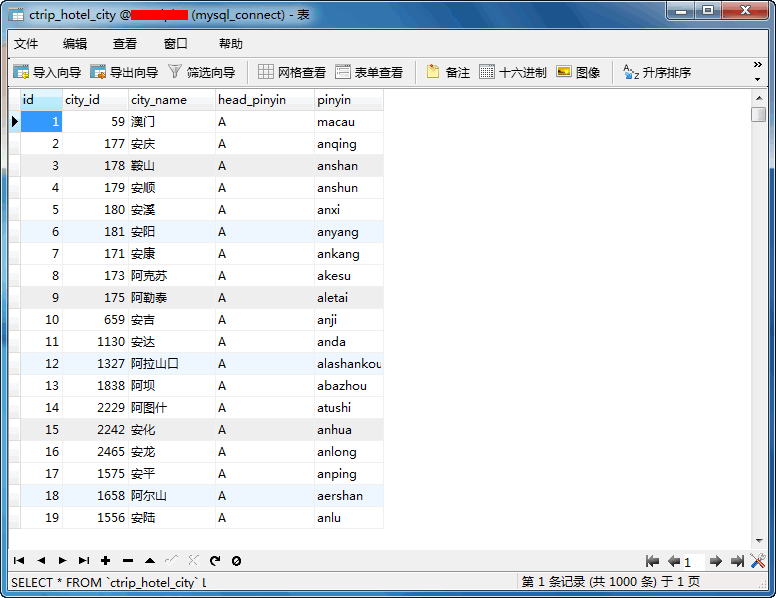
至此,酒店城市获取思路已介绍完毕,下面将介绍怎么用城市获取城市所有酒店的数据,
github源码地址 https://github.com/jianiuqi/CTripSpider
博文Java数据爬取——爬取携程酒店数据(二) 中介绍了如何利用地区爬取酒店数据,并保存到了mysql数据库















 744
744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









