








第一章 大数据概述
1.1 进入大数据时代的原因
- 第三次信息化浪潮
- 信息科技为大数据时代提供支撑
1)存储设备容量不断增加
2)CPU处理能力大幅提升
3)网络带宽不断增加 - 数据产生方式的变革促成大数据时代来临
1.2 大数据概念
大数据不仅仅是数据的“大量化(数据量大)”,而是包含“快速化(产生速度快,处理速度快)”“多样化(数据格式多样化,来源多样化)”和 “价值化(潜在的)”等多重属性
1.3 大数据应用
- 大数据关键技术
1)大数据处理过程:
大数据采集-大数据预处理-大数据存储-大数据分析与挖掘-大数据可视化
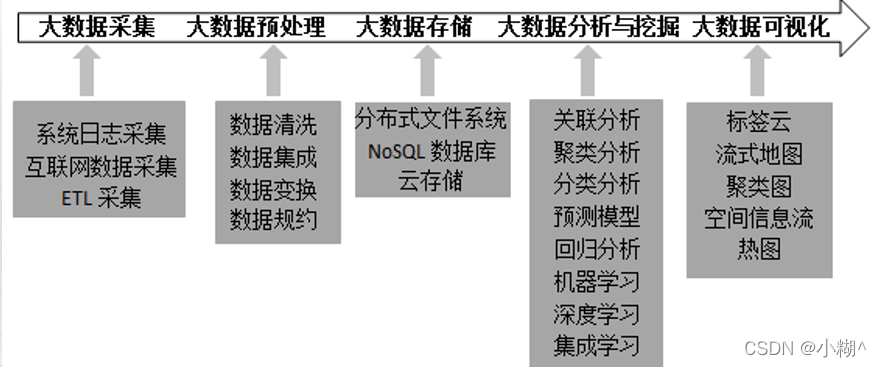
2)大数据技术体系:数据采集与预处理技术,分布式数据存储技术,分布式计算技术
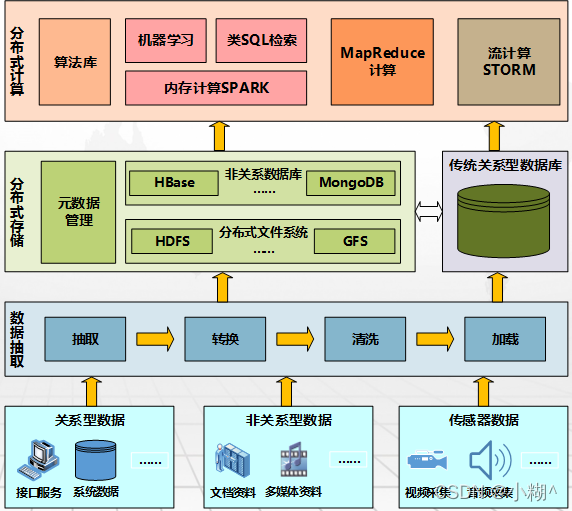
- 大数据采集技术
1)传统数据采集与分布式大数据采集
2)分布式架构的数据采集平台:Apache Chukwa,Flume,Scrible, Apache kafka
3)互联网大数据采集:爬虫技术,构建自己企业的大数据采集架构
4)企事业单位内部数据 - 大数据预处理技术
1)预处理的必要性:原始数据有杂乱性,重复性,不完整性
2)常用预处理技术:
数据清理:异常数据清理,数据错误纠正,重复数据的清除等目标
数据集成:将多个数据源中的数据结合起来并统一存储,建立数据仓库
数据变换:通过平滑聚集,数据概化,规范化等方式,将数据转换成适用于数据挖掘的形式
数据规约:寻找依赖于发现目标的数据应用特征,以缩减数据规模,从而在尽可能保持数据原貌的前提下,最大限度的精简数据量

第二章 大数据采集基础
2.1 传统数据采集技术
-
数据采集:将要获取的信息通过传感器转换为信号,并经过对信号的调整,采样,量化,编码和传输等步骤,最后送到计算机系统中进行处理,分析,存储和显示
-
传统数据采集系统特点
1.数据采集系统一般都包含有计算机系统,这使得数据采集的质量和效率等大为提高,同时节省了硬件投资。
2.软件在数据采集系统中的作用越来越大,增加了系统设计的灵活性。
3.数据采集与数据处理相互结合得日益紧密,形成了数据采集与处理相互融合的系统,可实现从数据采集、处理到控制的全部工作。
4.速度快,数据采集过程一般都具有“实时”特性。
5.随着微电子技术的发展,电路集成度的提高,数据采集系统的体积越来越小,可靠性越来越高。
6.出现了很多先进的采集技术,比如总线采集技术、分布式采集技术等。 -
数据采集系统框架
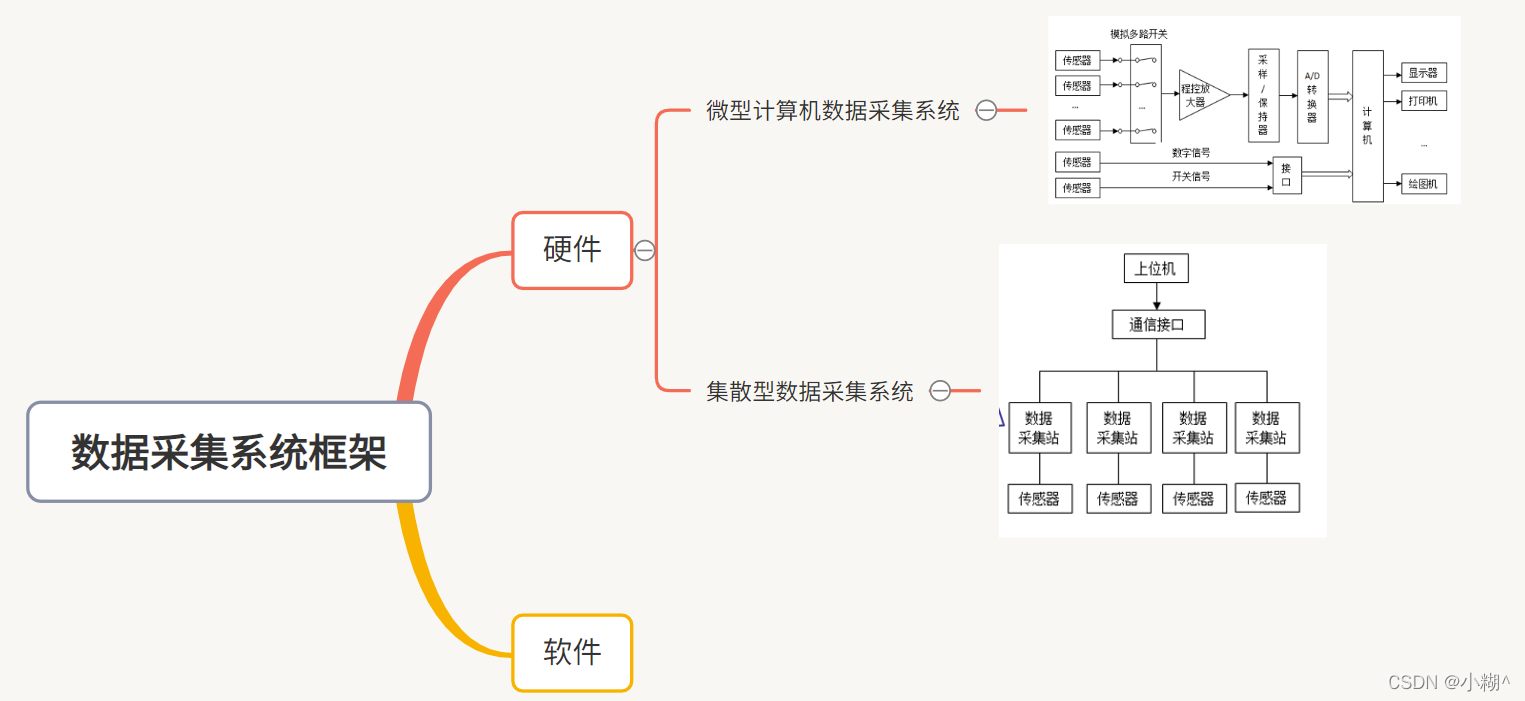
1.微型计算机数据采集系统
传感器:把各种非电的物理量,比如温度,压力,位移,流量等转成电信号的器件
模拟多路开关:数据采集系统往往要对多路模拟量进行采集。可以用模拟多路开关来轮流切换各路模拟量与A/D转换器间的通道,使得在一个特定的时间内,只允许一路模拟信号输入到 A/D转换器,从而实现分时转换的目的
程控放大器:在数据采集时,来自传感器的模拟信号一般都是比较弱的低电平信号。程控放大器的作用是将微弱输入信号进行放大,以便充分利用A/D转换器的满量程分辨率
采样/保持器:AD转换器完成一次转换需要一定的时间,在这段时间内希望AD转换器输入端的模拟信号电压保持不变,以保证有较高的转换精度。这可以用采样/保持器来实现,采样/保持器的加入,大大提高了数据采集系统的采样频率
A/D转换器:模拟信号转为数字信号
接口:用来将传感器输出的数字信号进行整形或电平调整,然后再传送到计算机的总线
绘图机:对数据采集系统的工作进行管理和控制,并对采集到的数据做必要的处理,然后根据需要进行存储,显示或打印
2.集散型数据采集系统
数据采集站:一般是由单片机数据采集装置组成,位于生产设备附近,独立完成数据采集和处理任务,并将数据以数字信号的形式传送给上位机
上位机:一般为PC计算机,配置有打印机和绘图机。上位机用来将各个数据采集站传送来的数据,集中显示在显示器上或用打印机打印各种报表,或以文件形式存储在磁盘上。此外,还可以将系统的控制参数发送给各个数据采集站,以调整数据采集站的工作状态
通信接口:异步串行传送数据。数据通信通常采用主从方式,由上位机确实与哪一个数据采集站进行数据传送
主要优点:系统的适应能力强;系统的可靠性高;系统可以实时响应;对系统硬件的要求不高
3.微型数据采集系统是基本型系统,由它可组成集散型数据采集系统
4.数据采集系统的软件
模拟信号采集与预处理程序:对模拟信号采集,标度变换,滤波处理及次数数据计算,并将数据存储到硬盘
数字信号采集与处理程序:对数字输入信号进行采集及码制之间的转换,如BCD码转换为ASCII码
脉冲信号处理程序:对输入的脉冲信号进行电平高低判断和计数
开关信号处理程序:判断开关信号输入状态的变化情况,如果发生变化,则执行相应的处理程序
运行参数设置程序:对数据采集系统的运行参数进行设置,运行参数有:采样通道号,采样点数等
系统管理(主控)程序:将各个工程模块程序组织成一个程序系统,并管理和调用各个功能模块的程序,还可以来管理系统数据文件的存储和输出。一般以文字菜单和图形菜单的人机界面技术来组织,管理和运行系统程序
通信程序:完成上位机与各个数据采集站之间的数据传送工作 -
数据采集关键技术
数据采集系统中采用计算机作为处理机。计算机处理的信号是二进制的离散数字信号,而被采集的各种物理量一般都是连续模拟信号,因此,在数据采集系统中,首先遇到的问题是传感器所测量到的连续模拟信号怎样转换成离散的数字信号。其关键技术包括:
采样技术:
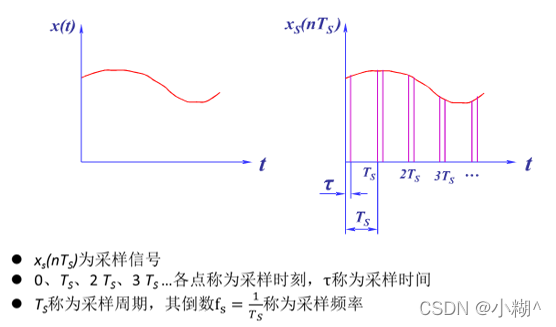

1)常规采样技术,遵循采样定理。采样频率必须大于模拟信号的最高频率的二倍
2)间歇采样技术,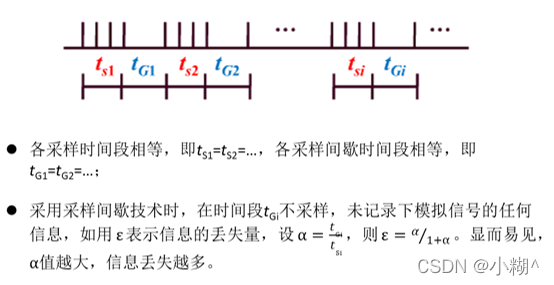
3)变频采样技术, 变频采样是指在采样过程中采样频率可以变化。例如,如果模拟信号的频率是随时间增大而减小的,那么就可以采用变频采样技术,从而减少采样的数据量。因此,实现变频采样的先决条件是清楚目标信号的频率随时间变化的关系
量化技术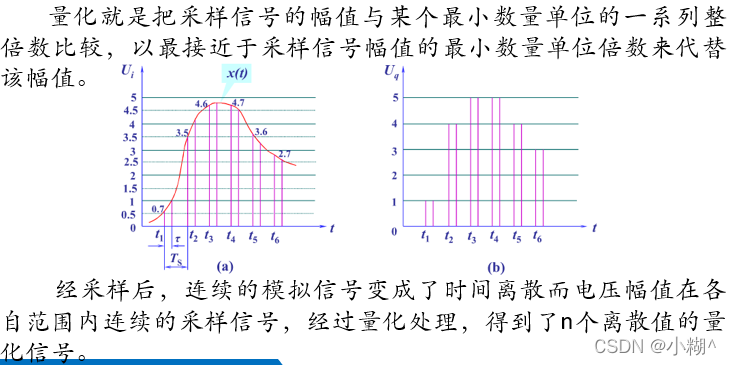
编码技术
2.2 大数据采集基础
2.2.1数据的发展
- 大数据产生:分布式计算,互联网技术发展(物联网,移动互联网,社交网络等)
- 大数据区别于传统数据之处:
大数据关注数据流,而不是数据库中的“库表”
大数据分析依赖于数据科学家,而不是传统的数据分析师
大数据正改变传统数据采集,存储,分析和处理流程
大数据正引领新的数据思维
2.2.2大数据来源
- 大数据分类


2.2.3大数据采集技术
大数据采集常用方法包括系统日志采集,利用ETL工具采集,网络爬虫等
-
系统日志采集


-
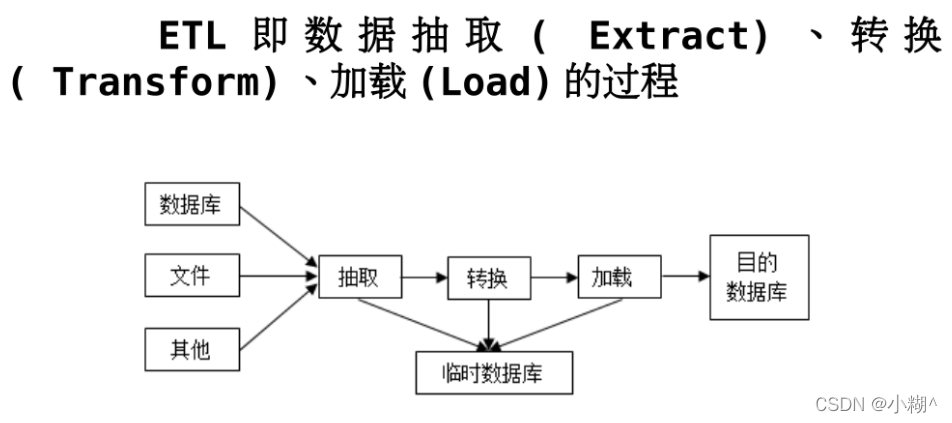
利用ETL工具采集

-
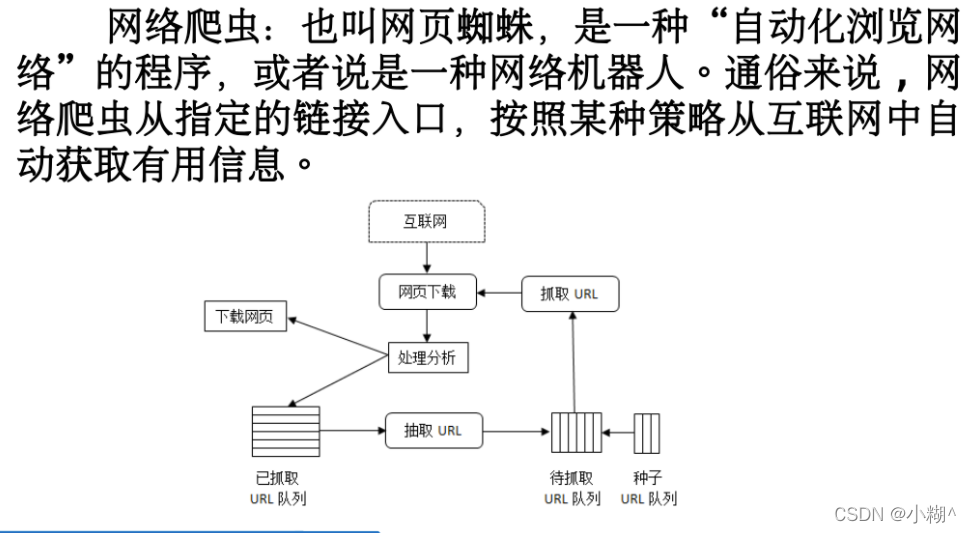
网络爬虫
第三章 大数据采集架构
3.1 概述
数据采集的方式多种多样,如通过卫星摄像机和传感器等硬件设备进行遥感数据、交通数据、人流数据的采集;通过半自动整理的方式采集商业景气数据、税务数据、人口普查数据等;通过互联网服务器自动采集业务数据、用户行为数据等等。
大型的互联网公司、金融行业、零售行业、医疗行业等都有自己的业务平台,在此平台上,每天都会产生大量的系统日志数据。
通过采集系统日志数据,可以获得大量数据。(属于半结构化数据,也可转化为结构化数据–二维表)
常用大数据采集架构:
- Hadoop的Chukwa:Chukwa是一个开源的用于监控大型分布式系统的数据收集系统。这是构建在Hadoop 的 HDFS 和 map/reduce 框架之上的,继承了Hadoop 的可伸缩性和鲁棒性。
- Cloudera的Flume:Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。*
- Facebook的Scribe:Scribe是Facebook开源的日志收集系统,在Facebook内部已经得到大量的应用。
- Apache Kafka:是由Apache开发的一个开源消息系统项目。它是一个分布式的、分区的、多副本的日志提交服务。
- 其他大数据采集框架
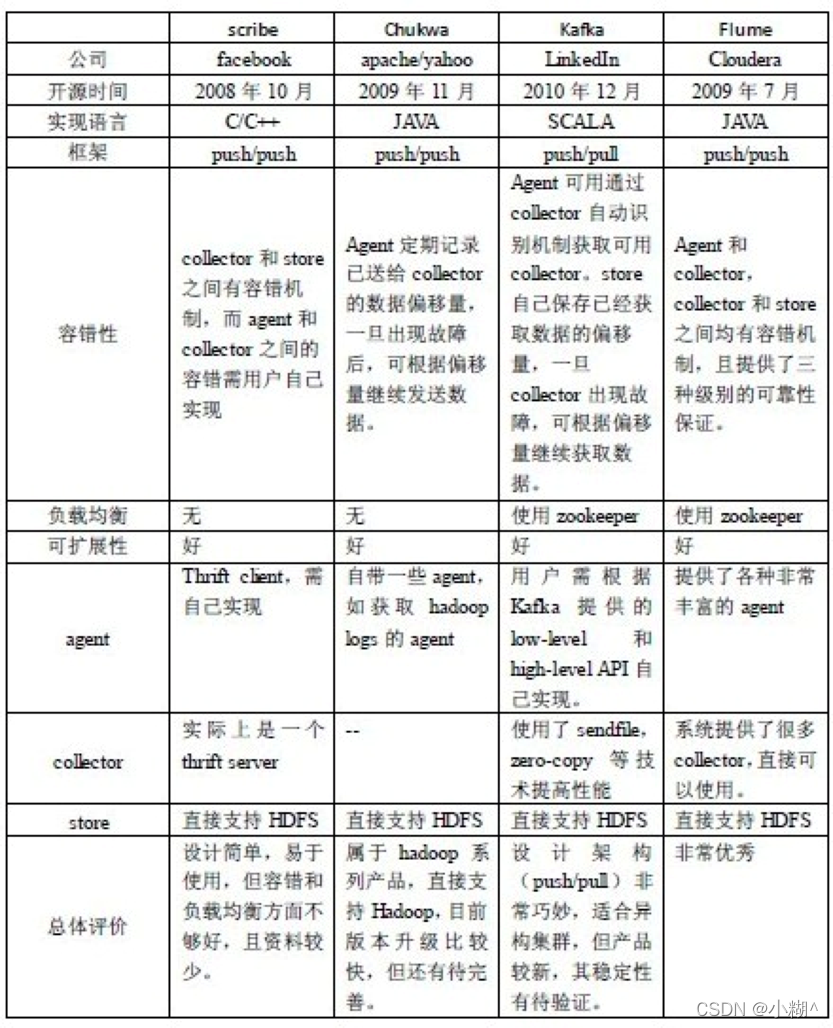
负载均衡:将负载(工作任务)进行平衡、分摊到多个操作单元上进行运行,例如FTP服务器、Web服务器、企业核心应用服务器和其它主要任务服务器等,从而协同完成工作任务。
容错性:系统在部分组件发生故障时仍能正常运作的能力。
可扩展性:规划网络过程中预留一些可扩展的地方以应对未来可能的更高要求的需求,比如在接入交换机上预留更多的接口应对业务的扩展,在核心交换机上预留板卡插槽等等
3.2 Chukwa数据采集
Chukwa是一个针对大型分布式系统的数据采集系统,其构建于Hadoop之上
Chukwa使用HDFS作为其存储,最初的设计是用于收集和分析Hadoop系统的日志
C
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1179
1179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









