







前言:
Oplog日志:
oplog 是 MongoDB 主从复制层面的一个概念,单点实例不存在;
通过 oplog 来实现复制集节点间数据同步(producer线程实现oplog抓取);
存储在local库下的oplog.rs固定集合(Capped collection),循环插入记录;
oplogSize默认是free-disk的5%,最小990M,最大50G,可通过oplogSizeMB参数设置;
1、Oplog的重放机制
同步过程
下图是MongoDB数据同步的流程
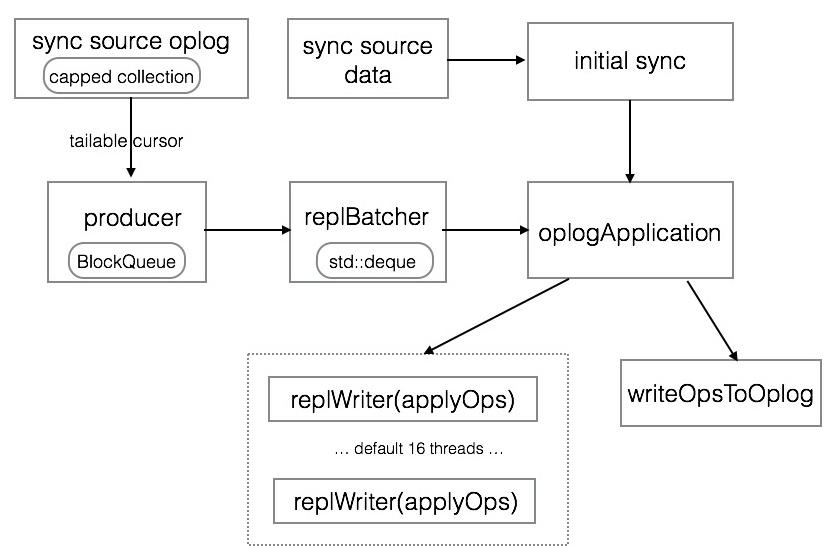
说明
producer thread,这个线程不断的从同步源上拉取oplog,并加入到一个BlockQueue的队列里保存着,BlockQueue最大存储256MB的oplog数据,当超过这个阈值时,就必须等到oplog被replBatcher消费掉才能继续拉取。replBatcher thread,这个线程负责逐个从producer thread的队列里取出oplog,并放到自己维护的队列里,这个队列最多允许5000个元素,并且元素总大小不超过512MB,当队列满了时,就需要等待oplogApplication消费掉。oplogApplication会取出replBatch thread当前队列的所有元素,并将元素根据docId(如果存储引擎不支持文档锁,则根据集合名称)分散到不同的replWriter线程,replWriter线程将所有的oplog应用到自身;等待所有oplog都应用完毕,oplogApplication线程将所有的oplog顺序写入到local.oplog.rs集合。
2.思考
问题来了, 为什么一个简单的『 拉取oplog并重放』 的动作要搞得这么复杂?
性能考虑, 拉取oplog是单线程进行, 如果把重放也放到拉取的线程里, 同步势必会很慢; 所以设计上producer thread只干一件事。
为什么不将拉取的oplog直接分发给replWriter thread, 而要多一个replBatcher线程来中转?
oplog重放时, 要保持顺序性, 而且遇到createCollection、 dropCollection等DDL命令时, 这些命令与其他的增删改查命令是不能并行执行的, 而这些控制就是由replBatcher来完成的。
3.oplog写入顺序
在上述整个过程中,都是线程在操作队列中的数据,也就是说都是在内存中,注意红色字体,oplog记录是先被重放应用,然后再顺序插入到local.oplog.rs的集合中。故在整个重放过程中,oplog是直接在内存中进行应用和写入oplog.rs集合,因为oplog.rs和普通集合没什么区别,想要落盘也是需要待checkpoint发生时才能进行;并且mongo不存在oplog日志文件,oplog记录全部是存储在local.oplog.rs集合中。
4.如何查看同步状态
producer的buffer和apply线程的统计信息都可以通过db.serverStatus().metrics.repl来查询到,如下图所示
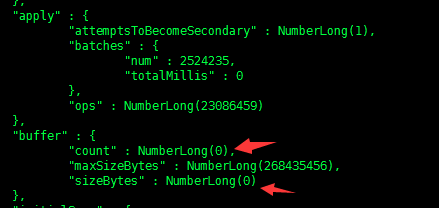
说明:一般情况下,producer的buffer里的count和sizeBytes为零,如果Secondary同步重放速度跟不上Primary操作量,那么producer的buffer就会达到饱和,从而可以判断oplog重放线程跟不上。默认情况下,Secondary采用16个replWriter线程来重放oplog;
可通过启动参数replWriterThreadCount来定制线程数,最大提升至32;
setParameter:
replWriterThreadCount: 32
另:同步拉取 oplog 时,会走 oplogHack 的路径,即快速根据oplog上次同步的位点定位到指点位置,这里会走一个二分查找,而不是COLLSCAN,然后从这个位点不断的tail oplog
5.oplog重放时的阻塞
MongoDB复制集里的Secondary节点不断从主节点批量拉取oplog,然后在本地进行重放;而在重放这批oplog时,会加一个特殊的锁 Lock::ParallelBatchWriterMode,这个锁会阻塞所有secondary节点上的读请求,直到这批oplog重放完成
原因有二:
- 尽量避免脏读,等一批 oplog 重放完后,这批数据才允许用户读到
尽量保证同步性能,设想一下,如果重放 oplog 时,使用普通的锁,那么 oplog 的重放就需要跟正常的读写竞争锁资源,如果 Secondary 上有大量的读,那么势必会造成备同步逐步跟不上。参考 SERVER-18190
如下案例就是在生产的secondary节点进行大量数据查询时需要的阻塞,通过db.currentOp()命令可以看到字段"waitingForLock" 设置为了true
"waitingForLock" : true
而此时持有锁的线程是:
"inprog" : [
{
"desc" : "rsSync",
......
"locks" : {
"Global" : "W"
},
6.注意事项
- initial sync单线程复制数据, 效率比较低, 生产环境应该尽量避免initial sync出现, 需合理配置oplog, 按默认『 5%的可用磁盘空间』 来配置oplog在绝大部分场景下都能满足需求, 特殊的case(case1, case2)可根据实际情况设置更大的oplog。
- 新加入节点时, 可以通过物理复制的方式来避免initial sync, 将Primary上的dbpath拷贝到新的节点, 直接启动, 这样效率更高。
- 当Secondary上需要的oplog在同步源上已经滚掉时, Secondary的同步将无法正常进行, 会进入RECOVERING的状态, 需向Secondary主动发送resyc命令重新同步。 3.2版本目前有个bug, 可能导致resync不能正常工作, 必须强制(kill -9)重启节点, 详情参考SERVER-24773。
- 生产环境, 最好通过db.printSlaveReplicationInfo()来监控主备同步滞后的情况, 当Secondary落后太多时, 要及时调查清楚原因。
- 当Secondary同步滞后是因为主上并发写入太高导致, (
db.serverStatus().metrics.repl.buffer.sizeBytes持续接近db.serverStatus().metrics.repl.buffer.maxSizeBytes) , 可通过调整Secondary上replWriter并发线程数来提升。
7.改进思路
如果因Primary上的写入qps很高,经常出现Secondary同步无法追上的问题,可以考虑以下改进思路
- 配置更高的replWriterThreadCount,Secondary上加速oplog重放,代价是更高的内存开销
- 使用更大的oplog,可按照官方教程修改oplog的大小,阿里云MongoDB数据库增加了patch,能做到在线修改oplog的大小。
- 将writeOpsToOplog步骤分散到多个replWriter线程来并发执行,这个是官方目前在考虑的策略之一,参考Secondaries unable to keep up with primary under WiredTiger
附修改replWriterThreadCount参数的方法,具体应该调整到多少跟Primary上的写入负载如写入qps、平均文档大小等相关,并没有统一的值。
1) 通过mongod命令行来指定
mongod --setParameter replWriterThreadCount=32
2) 在配置文件中指定
setParameter:
replWriterThreadCount: 32
8.备如何选择同步源?
MongoDB 复制集使用 oplog 来做主备同步,主将操作日志写入 oplog 集合,备从 oplog 集合不断拉取并重放,来保持主备间数据一致。MongoDB 里的 oplog 特殊集合拥有如下特性:
-
每条 oplog 都包含时间戳,按插入顺序递增,如果底层使用的KV存储引擎,这个时间戳将作为 oplog 在KV引擎里存储的key,可以理解为 oplog 在底层存储就是按时间戳顺序存储的,在底层能快速根据ts找位置。
-
oplog 集合没有索引,它一般的使用模式是,备根据自己已经同步的时间戳,来定位到一个位置,然后从这个位置不断 tail query oplog。针对这种应用模式,对于 local.oplog.rs.find({ts: {$gte: lastFetechOplogTs}}) 这样的请求,会有特殊的oplogStartHack 的优化,先根据gte的查询条件在底层引擎快速找到起始位置,然后从该位置继续 COLLSCAN。
-
oplog 是一个 capped collection,即固定大小集合(默认为磁盘大小5%),当集合满了时,会将最老插入的数据删除。
9.oplog.rs的COLLSCAN产生原因:
当一致时间点对应的oplog在同步源上找不到时,会在同步源上触发一次oplog的全表扫描。当主备之间频繁的切换(比如线上的这个实例因为写入负载调大,主备角色切换过很多次),会导致多次ROLLBACK发生,最后出现备上minvalid里的一致时间点在同步源上找不到,引发了oplog的全表扫描;即使发生全表扫描,因为不包含minvalid的oplog,备也不能选择这个节点当同步源,最后就是一直找不到同步源,处于RECOVERING状态无法恢复,然后不断重试,不断触发主上的oplog全表扫描,恶性循环
参考资料
capped collection
SERVER-18908
修改oplog的大小
MongoDB Secondary 延时高(同步锁)问题分析)
MongoDB复制集同步原理解析
Secondary节点为何阻塞请求近一个小时?















 7348
7348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









