







 本文介绍了二叉树作为数据结构的优势,其定义以及遍历方式,包括先根遍历、中根遍历和后根遍历。此外,还详细讲述了如何用Java实现二叉树,并实现遍历、获取双亲结点和孩子结点等功能。
本文介绍了二叉树作为数据结构的优势,其定义以及遍历方式,包括先根遍历、中根遍历和后根遍历。此外,还详细讲述了如何用Java实现二叉树,并实现遍历、获取双亲结点和孩子结点等功能。
二叉树概述
数组、向量、链表都是一种顺序容器,它们提供了按位置访问数据的手段。而很多情况下,我们需要按数据的值来访问元素,而不是它们的位置来访问元素。比如有这样一个数组int num[3]={1,2,3},我们可以非常快速的访问数组中下标为2的数据,也就是说我们知道这个数据的位置,就可以快速访问。有时候我们是不知道元素的位置,但是却知道它的值是多少。假设我们有一个变量,存放在num这个数组中,我们知道它的值为2,却不知道它下标是多少,也就是说不知道它的位置。这个时候再去数组中访问这个元素就比较费劲,就得遍历数组,而且还要保证数组中没有重复的元素。
二叉树在很大程度上解决了这个缺点,二叉树是按值来保存元素,也按值来访问元素。怎么做到呢,和链表一样,二叉树也是由一个个节点组成,不同的是链表用指针将一个个节点串接起来,形成一个链,如果将这个链“拉直”,就像平面中的一条线,是一维的。而二叉树由根节点开始发散,指针分别指向左右两个子节点,像树一样在平面上扩散,是二维的。示意图如下:
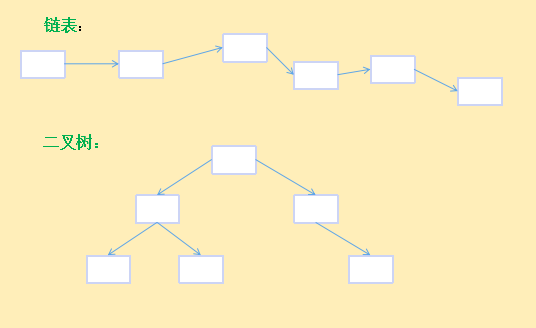
二叉树的定义:
二叉树是树形结构的一个重要类型。许多实际问题抽象出来的数据结构往往是二叉树的形式,即使是一般的树也能简单地转换为二叉树,而且二叉树的存储结构及其算法都较为简单,因此二叉树显得特别重要。
二叉树(BinaryTree)是n(n≥0)个结点的有限集,它或者是空集(n=0),或者由一个根结点及两棵互不相交的、分别称作这个根的左子树和右子树的二叉树组成。
这个定义是递归的。由于左、右子树也是二叉树, 因此子树也可为空树。下图中展现了五种不同基本形态的二叉树。
![这里写图片描述]![这里写图片描述]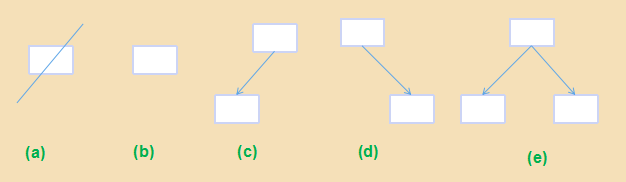
其中 (a) 为空树, (b) 为仅有一个结点的二叉树, (c) 是仅有左子树而右子树为空的二叉树, (d) 是仅有右子树而左子树为空的二叉树, (e) 是左、右子树均非空的二叉树。这里应特别注意的是,二叉树的左子树和右子树是严格区分并且不能随意颠倒的,图 (c) 与图 (d) 就是两棵不同的二叉树。
二叉树的遍历
对于二叉树来讲最主要、最基本的运算是遍历。
遍历二叉树 是指以一定的次序访问二叉树中的每个结点。所谓 访问结点 是指对结点进行各种操作的简称。例如,查询结点数据域的内容,或输出它的值,或找出结点位置,或是执行对结点的其他操作。遍历二叉树的过程实质是把二叉树的结点进行线性排列的过程。假设遍历二叉树时访问结点的操作就是输出结点数据域的值,那么遍历的结果得到一个线性序列。
从二叉树的递归定义可知,一棵非空的二叉树由根结点及左、右子树这三个基本部分组成。因此,在任一给定结点上,可以按某种次序执行三个操作:
(1)访问结点本身(N),
(2)遍历该结点的左子树(L),
(3)遍历该结点的右子树(R)。
以上三种操作有六种执行次序:
NLR、LNR、LRN、NRL、RNL、RLN。
注意:
前三种次序与后三种次序对称,故只讨论先左后右的前三种次序。
由于被访问的结点必是某子树的根,所以N(Node)、L(Left subtlee)和R(Right subtree)又可解释为根、根的左子树和根的右子树。NLR、LNR和LRN分别又称为先根遍历、中根遍历和后根遍历。
二叉树的java实现
首先创建一棵二叉树如下图,然后对这颗二叉树进行遍历操作(遍历操作的实现分为递归实现和非递归实现),同时还提供一些方法如获取双亲结点、获取左孩子、右孩子等。
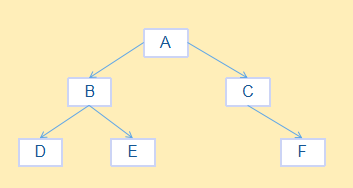
package com.zjn.tree;
import java.util.Stack;
/**
* 二叉树的链式存储
*
* @author zjn
*/
public class Tree {
private TreeNode root = null;
public Tree() {
root = new TreeNode(1, "rootNode(A)");
}
/**
* 二叉树的节点数据结构
*
*/
private class TreeNode {
private int key = 0;
private String data = null;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 852
852

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









