






当对Kafka中的数据进行解析时,由于数据量大,可以对Java开启多线程的处理,这里使用的 ThreadPoolExecutor 可以直接拿过来是使用。
目录
2、ThreadPoolExecutor执行execute()方法的示意图
前言
Java 中如何快速使用线程池来进行处理呢?直接使用第三方接口 ThreadPoolExecutor
一、线程池的作用是什么?
线程池的工作主要是控制运行的线程的数量,处理过程中将任务放入队列,然后在线程创建后启动这些任务,如果线程数量超过了最大数量,那么超出数量的线程排队等候,等其他线程执行完毕再从队列中取出任务来执行。
二、使用线程池的好处
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗;
- 提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行;
- 提高线程的可管理性。线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一分配、调优和监控。
三、线程池实现原理
1、线程池处理流程
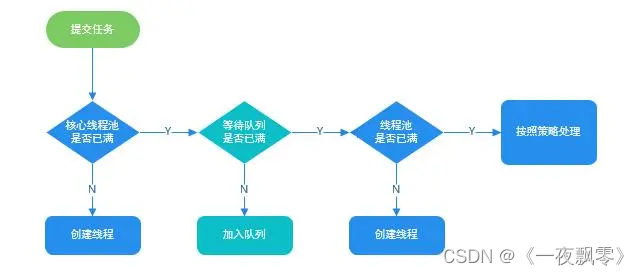
2、ThreadPoolExecutor执行execute()方法的示意图
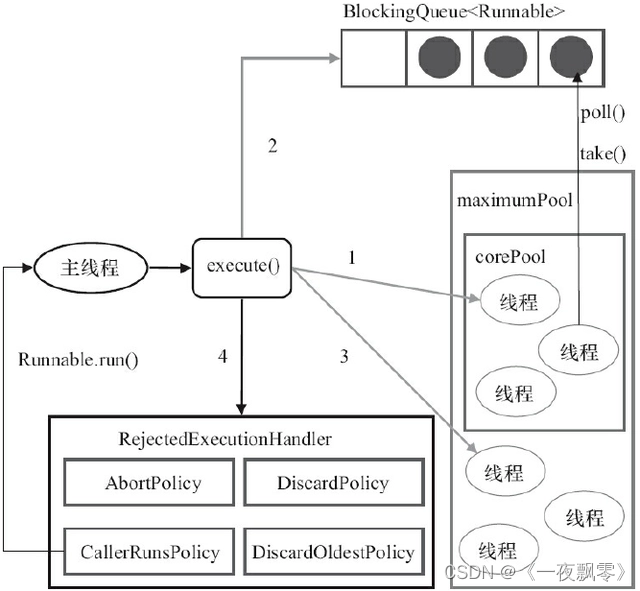
二、使用步骤
1.引入库
代码如下:
import java.util.concurrent.ThreadPoolExecutor
2.创建线程池
代码如下:通过ThreadPoolExecutor创建
// 定义线程池
private static final ThreadPoolExecutor EXECUTOR1 = new ThreadPoolExecutor(2500,
4500,
100L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(7000),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
// 引用线程池
for (ConsumerRecord<String, String> record : records) {
EXECUTOR.execute(new Runnable() {
@Override
public void run() {
//程序的具体执行逻辑
}
});
}3.ThreadPoolExecutor函数介绍
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
- corePoolSize:线程池的核心线程数,定义了最小可以同时运行的线程数量。
- maximumPoolSize:线程池的最大线程数。方队列中存放的任务达到队列容量时,房前可以同时运行的线程数量变为最大线程数。
- keepAliveTime:当线程池中的线程数量大于corePoolSize时,如果没有新任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了KeepAliveTime才会被回收销毁。
- unit:keepAliveTime参数的时间单位,包括DAYS、HOURS、MINUTES、MILLISECONDS等。
- workQueue:用于保存等待执行任务的阻塞队列。可以选择以下集个阻塞队列:
ArrayBlockingQueue数组BlockingQueue:是一个基于数组结构的阻塞队列,此队列按FIFO原则对元素进行排序;LinkedBlockingQueue:是一个基于链表结构的阻塞队列,此队列按FIFO排序元素,吞吐量通常高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()使用了这个队列。SynchronousQueue同步队列:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量常高于 LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool() 使用了这个队列。PriorityBlockingQueue:一个具有优先级的无限阻塞队列。
- threadFactory:用于设置创建线程的工厂,可以通过工厂给每个创造出来的线程设置更有意义的名字。使用开源框架guava提供的ThreadFactoryBuilder可以快速给线程池里的线程设置有意义的名字:
- new ThreadFactoryBuilder().setNameFormat("XX-task-%d").build();
- new ThreadFactoryBuilder().setNameFormat(“XX-task-%d”).build();
- handler:饱和策略。若当前同时运行的线程数量达到最大线程数量并且队列已经被放满,ThreadPoolExecutor定义了一些饱和策略:
ThreadPoolExecutor.AbortPolicy:直接抛出RejectedExecutionException异常来拒绝处理新任务;
ThreadPoolExecutor.CallerRunsPolicy:只用调用者所在的线程来运行任务,会降低新任务的提交速度,影响程序的整体性能。
ThreadPoolExecutor.DiscardPolicy:不处理新任务,直接丢弃掉。 ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列中最近的一个任务,执行当前任务。
4. 向线程池提交任务
- execute()方法用于像线程池提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功。
executor.execute(new Runnable() {
@Override
public void run() {
// TODO
}
});- submit()方法用于提交需要返回值的任务。线程池会返回一个future类型的对象,通过这个future对象可以判断任务是否执行成功,并且可以通过future的get()方法获取返回值,get()方法会阻塞当前线程直到任务完成,而使用get(long timeout, TimeUnit unit)方法则会阻塞当前线程一段时间后立即返回,这时有可能任务还没有执行完。
Future<T> future = EXECUTOR.submit(hasReturnValueTask);
try {
T s = future.get();
} catch (Excception e) {
// 处理异常 e.printStackTrace();
} finally {
// 关闭线程池 executor.shutdown();
}5.关闭线程池
使用线程池的shutdown或shutdownNow方法来关闭线程池。其原理在于遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能无法终止。
二者区别在于:shutdownNow方法首先将线程池状态设置为STOP,然后尝试停止所有正在执行或暂停任务的线程,并返回等到执行任务的列表,而shutdown只是将线程池的状态设置为SHUTDOWN状态,然后中断所有没有整在执行任务的线程。
6. 合理配置线程池
查看当前设备的CPU核数:
Runtime.getRuntime().availableProcessors();- CPU密集型任务:任务需要大量的运算,而没有阻塞,CPU一直全速运行。CPU密集型任务配置尽可能的少的线程数量。公式:CPU核数 + 1个线程的线程池。
- IO密集型任务:任务需要大量的IO,即大量的阻塞。由于IO密集型任务线程并不是一直在执行任务,可以多分配一点线程数,如CPU核数*2。公式:CPU核数/(1-阻塞系数),其中阻塞系数在0.8-0.9之间。
总结
在实际应用中,比如我是处理各种各样的数据的,由于每一类数据的复杂程度不一样,有时会造成资源等待的问题,但是如果是处理的数据难易程度差不多时,效果还是很显著的。
代码
package cn.ac.ii;
import cn.ac.ii.kafka.Kafka;
import cn.ac.ii.tool.ConstUtil;
import cn.ac.ii.tool.MyTools;
import com.alibaba.fastjson.JSONObject;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.util.Arrays;
import java.util.Map;
import java.util.concurrent.*;
/**
* @author 一夜飘零
* @create 2022-05-26 10:07
*/
@Slf4j
public class Metrics_App {
private static final ThreadPoolExecutor EXECUTOR = new ThreadPoolExecutor(2500, 4500, 100L, TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(7000), Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy());
public void running() {
// 1、连接到kafka
KafkaConsumer<String, String> kafkaConsumer =
Kafka.getKafkaConsumer(ConstUtil.KAFKA_QUORUM, "group10",true);
// true是latest
kafkaConsumer.subscribe(Arrays.asList(ConstUtil.METRICS_TOPIC_NAME));
Map<String, JSONObject> extracted = null;
while (true) {
ConsumerRecords<String, String> records = kafkaConsumer.poll(10);
if (!records.isEmpty()) {
// 2、 将plugins_plugin中data不为空的过滤出来
for (ConsumerRecord<String, String> record : records) {
EXECUTOR.execute(new Runnable() {
@Override
public void run() {
//实际要的处理逻辑部分
}
});
}
}
}
}
public static void main(String[] args) {
Metrics_App rk = new Metrics_App();
rk.running(); // 正常业务的
}
}
















 1227
1227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









