







一、Spark SQL简介
park SQL是spark的一个模块,主要用于进行结构化数据的SQL查询引擎,开发人员能够通过使用SQL语句,实现对结构化数据的处理,开发人员可以不了解Scala语言和Spark常用API,通过spark SQL,可以使用Spark框架提供的强大的数据分析能力。spark SQL前身为Shark。Shark是Spark上的数据仓库,最初设计成与Hive兼容,但是该项目于2014年项目因设计问题中止研发,转向Spark SQL。Spark SQL全面继承了Shark,并进行了优化。 Spark SQL主要提供了以下三个功能:
1)Spark SQL可从各种结构化数据源中读取数据,进行数据分析。
2)Spark SQL包含行业标准的JDBC和ODBC连接方式,因此它不局限于在Spark程序内使用SQL语句进行查询。
3)Spark SQL可以无缝地将SQL查询与Spark程序进行结合,它能够将结构化数据作为Spark中的分布式数据集(RDD)进行查询。
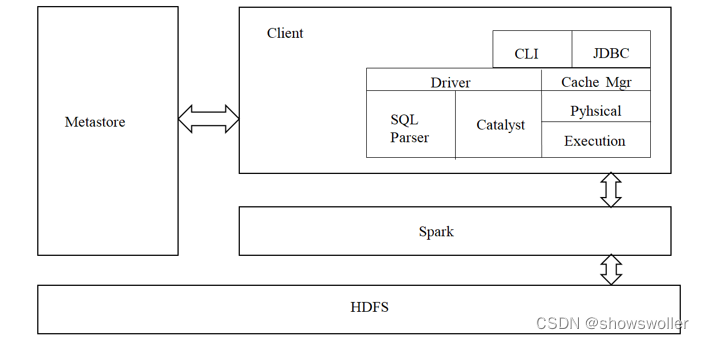
二、Spark架构
Spark SQL架构与Hive架构相比,把底层的MapReduce执行引擎更改为Spark,还修改了Catalyst优化器,Spark SQL快速的计算效率得益于Catalyst优化器。从HQL被解析成语法抽象树起,执行计划生成和优化的工作全部交给Spark SQL的Catalyst优化器进行负责和管理。
三、Dataframe
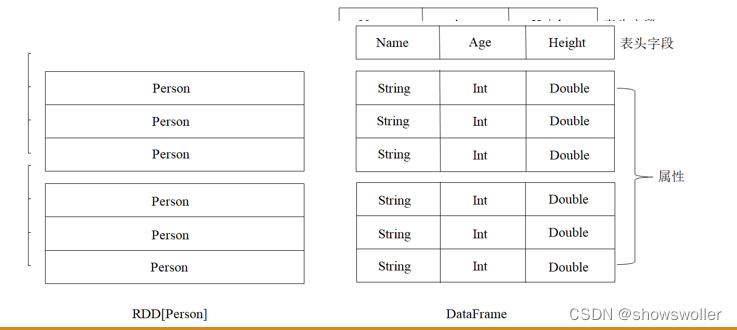
1:Dataframe简介
Spark SQL使用的数据抽象并非是RDD,而是DataFrame。
在Spark 1.3.0版本之前,DataFrame被称为SchemaRDD。
DataFrame使Spark具备处理大规模结构化数据的能力。 在Spark中,DataFrame是一种以RDD为基础的分布式数据集。 DataFrame的结构类似传统数据库的二维表格,可以从很多数据源中创建,如结构化文件、外部数据库、Hive表等数据源。
DataFrame可以看作是分布式的Row对象的集合,在二维表数据集的每一列都带有名称和类型,这就是Schema元信息,这使得Spark框架可获取更多数据结构信息,从而对在DataFrame背后的数据源以及作用于DataFrame之上数据变换进行针对性的优化,最终达到提升计算效率。
2:Dataframe的创建
创建DataFrame的两种基本方式:
已存在的RDD调用toDF()方法转换得到DataFrame。
通过Spark读取数据源直接创建DataFrame。
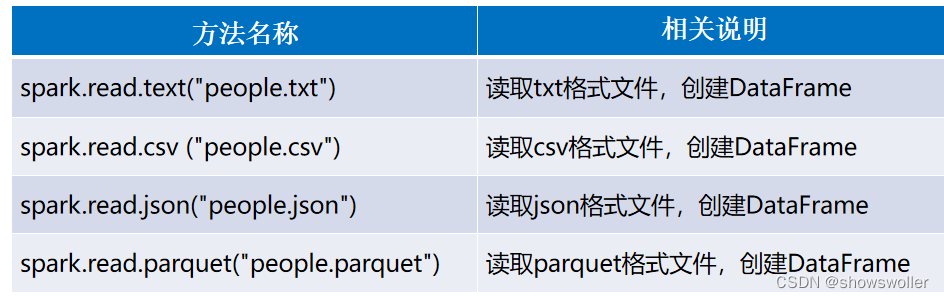
若使用SparkSession方式创建DataFrame,可以使用spark.read从不同类型的文件中加载数据创建DataFrame。spark.read的具体操作,如下所示。
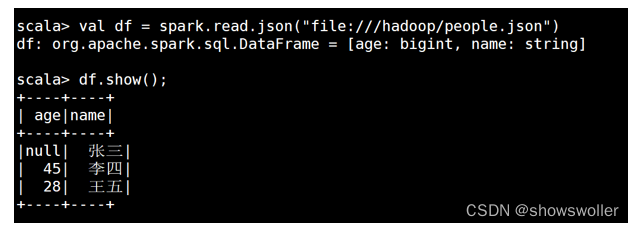
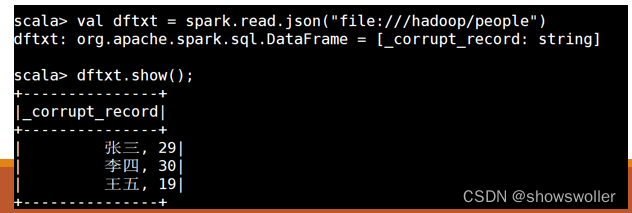
具体操作示例如下: 首先在linux操作系统hadoop文件夹下存了两个文件,一个是people.json,存的是 json格式数据,内容如下: {"name":"张三"} {"name":"李四", "age":45} {"name":"王五", "age":28} 另一个是people.txt,存的是普通文本格式,内容如下: 张三, 29 李四, 30 王五, 19。 打开spark-shell,如图所示
读取json文件创建DataFrame,命令如下
读取txt文件创建DataFrame,命令如下
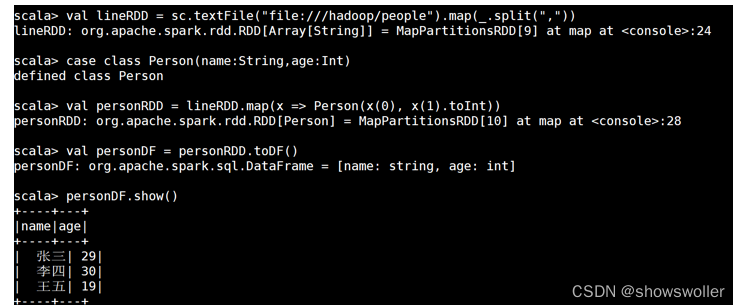
已存在的RDD调用toDF()方法转换得到DataFrame,具体操作如下:
(1)从文件系统加载数据创建RDD
val lineRDD = sc.textFile("file:///hadoop/people").Map(_.split(","))
(2)定义类
case class Person(name:String,age:Int)
(3)实例化类并赋值
val personRDD = lineRDD.Map(x => Person(x(0), x(1).toInt))
(4)调用toDF()方法转换得到DataFrame
val personDF = personRDD.toDF()
3:Dataframe常用操作
DataFrame提供了两种语法风格,即DSL风格语法和SQL风格语法。二者在功能上并无区别,仅仅是根据用户习惯,自定义选择操作方式。
DataFrame提供了一个领域特定语言(DSL)以方便操作结构化数据。
在程序中直接使用spark.sql()方式执行SQL查询,结果将作为一个DataFrame返回,使用SQL风格操作的前提是将DataFrame注册成一个临时表。
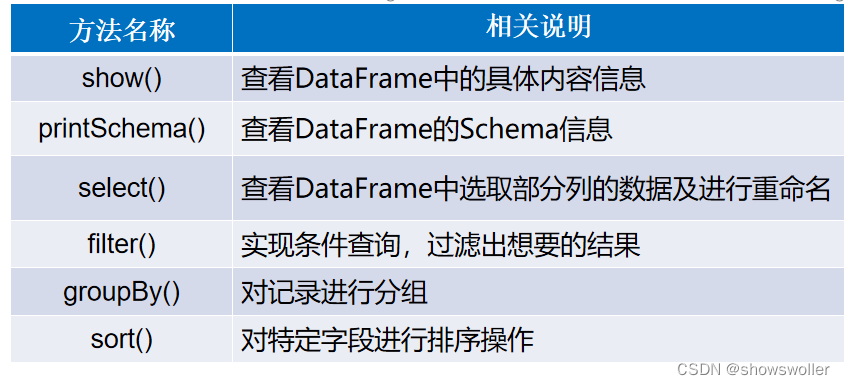
DSL风格操作DataFrame的常用方法,具体如下表如示。
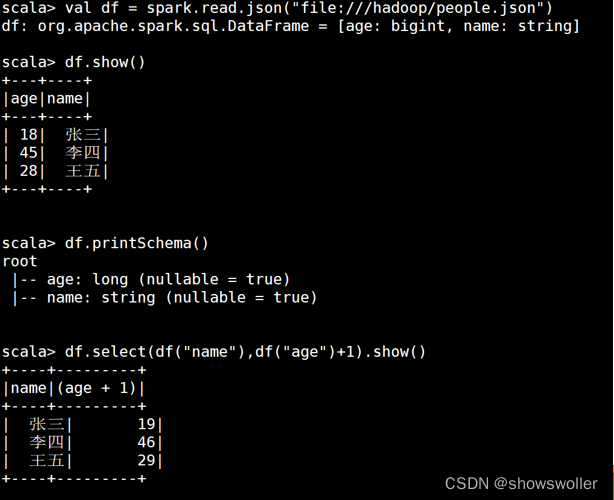
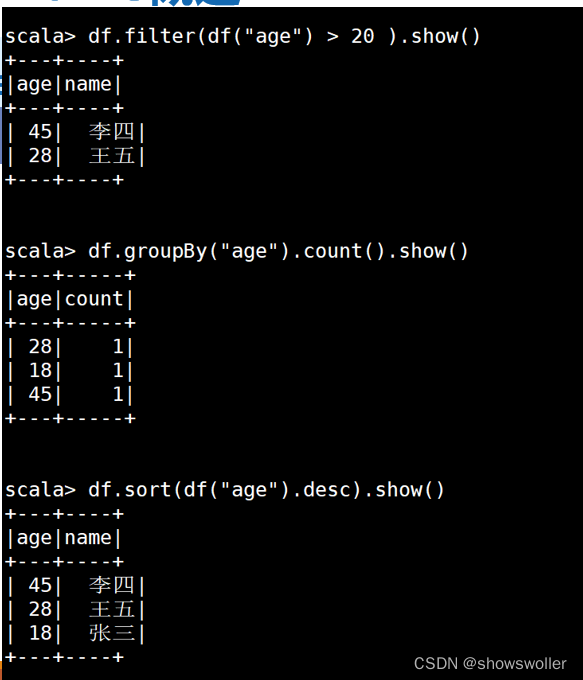
DSL风格操作Dataframe实例如下
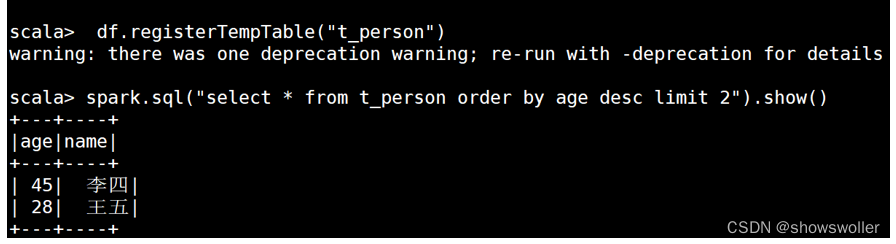
SQL风格操作Dataframe
三、Dataset
Dataset是从Spark1.6 Alpha版本中引入的一个新的数据抽象结构,最终在Spark2.0版本被定义成Spark新特性。Dataset提供了特定域对象中的强类型集合,也就是在RDD的每行数据中添加了类型约束条件,只有约束条件的数据类型才能正常运行。Dataset结合了RDD和DataFrame的优点,并且可以调用封装的方法以并行方式进行转换等操作。
RDD、DataFrame及Dataset的区别
RDD数据的表现形式,即序号(1),此时RDD数据没有数据类型和元数据信息。
DataFrame数据的表现形式,即序号(2),此时DataFrame数据中添加Schema元数据信息(列名和数据类型,如ID:String),DataFrame每行类型固定为Row类型,每列的值无法直接访问,只有通过解析才能获取各个字段的值。
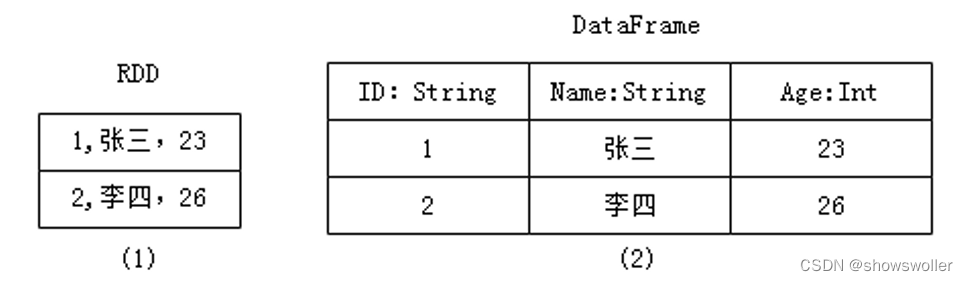
Dataset数据的表现形式,序号(3)和(4),其中序号(3)是在RDD每行数据的基础之上,添加一个数据类型(value:String)作为Schema元数据信息。而序号(4)每行数据添加People强数据类型,在Dataset[Person]中里存放了3个字段和属性,Dataset每行数据类型可自定义,一旦定义后,就具有错误检查机制。

1、通过SparkSession中的createDataset来创建Dataset
scala > val personDs=spark.createDataset(sc.textFile("/spark/person.txt"))
personDs: org.apache.spark.sql.Dataset[String] = [value: string]
scala > personDs.show()
+---------------+
| value |
+---------------+
|1 zhangsan 20|
|2 lisi 29|
|3 wangwu 25|
|4 zhaoliu 30 |
|5 tianqi 35|
|6 jerry 40|
+---------------+
2、DataFrame通过“as[ElementType]”方法转换得到Dataset
scala> spark.read.text("/spark/person.txt").as[String]
res14: org.apache.spark.sql.Dataset[String] = [value: string]
scala> spark.read.text("/spark/person.txt").as[String].toDF()
res15: org.apache.spark.sql.DataFrame = [value: string]
创作不易 觉得有帮助请点赞关注收藏~~~
















 9753
9753











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











